
如何针对搜索引擎爬虫优化您的网站?
已发表: 2023-04-27网络爬虫不断地浏览网站以确定每个页面的内容。 当用户提交请求时,可以对数据进行索引修改和查找。 一些网站使用网络爬虫机器人来更新他们网站的内容。
Google 或 Bing 等搜索引擎将搜索引擎与网络爬虫收集信息结合使用,以显示相关网站和相关信息作为用户搜索的结果。
如果一个网页设计 公司或网站所有者希望看到他们的网站出现在搜索结果中,必须对其进行抓取和索引。 如果网站未被抓取或编入索引,则搜索引擎将无法有机地找到它们。
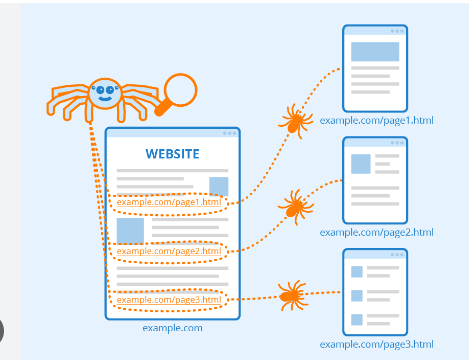
网络爬虫从爬取特定页面开始,然后跟随页面上的超链接到新页面。
不希望被搜索引擎抓取或发现的网站可以使用 robots.txt 文件中的工具来指示机器人不要索引网站或只索引其中的一小部分。
使用爬行工具进行站点检查可以帮助网站所有者识别损坏的超链接或重复内容。 标题不存在或标题太长或太短。
目录
搜索引擎在网络爬虫中的作用:
1. Crunching:在 Internet 上查找信息,然后查看他们遇到的每个 URL 的源代码/内容。
2. 索引:管理和存储在爬行过程中收集的信息。 将页面包含在索引中后,将其显示为相关搜索的结果可能是一个连续的过程。
3.排序:展示最有可能满足用户需求的部分信息。
Google 中的抓取到底是什么?
爬行是搜索引擎用来分发一组机器人(蜘蛛和爬虫)以查找新鲜和更新内容的查找方法。
内容可以是不同的格式,例如图像、网页或视频、PDF 等。无论是哪种格式,都可以通过超链接找到内容。
Googlebot 首先搜索某些网站; 之后,它会扫描页面的超链接以查找新的 URL。
在遍历超链接时,爬虫可以发现可以包含在名为 Caffeine 的索引中的新内容。
它是一个包含最近发现的 URL 的庞大数据库,当有人在内容 URL 完全匹配的网站上搜索信息时,可以检索这些 URL。
搜索引擎排名:
当有人进行谷歌搜索时,搜索引擎会扫描他们的索引以找到相关内容,然后安排内容来解决问题。
搜索结果根据相关性排列的顺序称为排名。
您可以阻止搜索引擎的抓取工具抓取您网站的特定部分甚至全部,或者指示搜索引擎不要将特定网站包含在其索引中。
如果你想看到你的网站通过搜索引擎结果被索引,你应该确保它可以被爬虫访问并且可以被索引。
爬行搜索引擎:
如您所见,确保您的网站被抓取、索引和抓取对于它出现在搜索结果中至关重要。 如果贵公司的 网站在您正在查看的网站的索引中,最好先查看搜索结果中的页数。

这可以让您很好地了解 Google 如何抓取您的网站以找到您想要链接到的每个页面而不是发现您不想链接的页面。
结果: Google 显示的结果数量并不准确。 但是,它可以让您了解在您的网站上找到的网页以及它们在搜索结果页上的显示方式。
该工具允许网页设计趋势在您的网站上上传站点地图并跟踪提交的页面数量以添加到 Google 的索引和其他方面。
如果您的网站没有出现在结果页面上,有很多原因需要查看:
- 您的网站是新网站,仍有待抓取。
- 您网站的导航使抓取工具难以有效地导航。
- 您的网站有一个称为爬虫指令的基本代码,可以阻止搜索引擎的爬虫指令。
- 您的网站已被 Google 从列表中删除,因为它使用了垃圾邮件方法。
让搜索引擎知道他们可以访问您网站的方式:
如果您尝试使用 Google Search Console 或“site: domain.com”高级搜索引擎并发现您的一些重要页面未在索引中列出,或者某些不那么重要的页面未正确编入索引, 然后有一些方法可以按照您希望抓取网站内容的方式来管理 Googlebot。
许多网站专注于确保 Google 能够找到他们最重要的网站,但很容易忽略您最有可能希望避免 Googlebot 找到的几个页面。
这些可能是没有信息的旧 URL 和大量 URL(例如电子商务的过滤器和排序参数)、促销代码、登台或测试页面等等。
结论:
Google 在为您的网站确定正确的 URL 方面做得非常出色。
但是,您也可以在 Search Console 中使用此功能来告诉 Google 您希望他们如何处理您的网站。
如果您利用此功能告诉 Googlebot“抓取不包含参数 ____ 的 URL”,它会试图说服 Google 将此信息从 Googlebot 中移除,从而从搜索结果中删除这些页面。
当这些参数导致重复页面时,这就是您要寻找的。 但是,如果您希望包含这些页面,还有更好的选择。
常见问题:
您是否发现您的网站内容在使用登录表单时消失了?
当您要求用户在访问特定网站之前注册并完成表格或调查时,搜索引擎将无法访问受保护的页面。 爬虫必然需要协助登录。
你应该使用谷歌的搜索页面吗?
机器人无法访问搜索表单。 有些人认为,如果他们在网站上包含搜索选项,搜索引擎就可以找到用户正在搜索的内容。
搜索引擎可以跟随您网站的方向吗?
爬虫必须通过指向其他网站的超链接找到您的网站,并需要一个链接列表,将用户从一个页面引导到另一个页面。 如果您有一个您希望搜索引擎找到的页面,但它没有连接到另一个页面,那么它比被忽视要有效得多。