
Apache Solr'dan En İyi Şekilde Yararlanın: Arama Dizinlemenin Teknik Bir Keşfi
Yayınlanan: 2023-02-21Bir arama özelliği, kullanıcının aradığını kolay ve hızlı bir şekilde bulmasını sağlayarak bir web sitesinin kullanıcı deneyimini geliştirir. Daha çok büyük web siteleri, e-ticaret siteleri ve dinamik içeriğe sahip siteler (haber siteleri, bloglar) için.
Apache Solr, her büyüklükteki web sitesi tarafından kullanılan en popüler arama platformlarından biridir. Makaleler, ürünler, müşteri incelemeleri ve daha fazlası gibi büyük miktarda veride arama yapmanızı sağlayan, Java tabanlı açık kaynaklı bir arama motorudur. Bu makalede Apache Solr'a daha yakından bakın.
Drupal'da Apache Solr'u nasıl yapılandıracağınızı öğrenmek için bu makaleye göz atın

Apache Solr neden bu kadar popüler?
Apache Solr hızlı ve esnektir ve tam metin arama, isabet vurgulama (eşleşen arama terimini vurgular), yönlü arama (daha rafine bir arama), gerçek zamanlı dizin oluşturma (yeni içeriğin hemen dizine eklenmesini sağlar), dinamik kümeleme ( arama sonuçlarını gruplar halinde düzenler), veritabanı entegrasyonu, NoSQL özellikleri (ilişkisel olmayan veritabanı) ve zengin belge işleme (PDF, MS Office, Open office gibi çok çeşitli belge biçimlerini dizine eklemek için).
Apache Solr hakkında bazı iyi bilinen gerçekler:
- Başlangıçta CNET ağları, inc. tarafından geliştirilmiştir. web siteleri ve makaleler için bir arama motoru olarak. Daha sonra açık kaynaklı oldu ve üst düzey bir Apache projesi oldu.
- PHP, Java, Python ve Ruby gibi çoklu programlama dillerini destekler. Ayrıca bu diller için API'ler sağlar.
- Jeo-uzamsal arama için yerleşik desteğe sahiptir ve içeriğin konumuna göre aranmasına izin verir. Özellikle emlak siteleri, seyahat siteleri vb. siteler için kullanışlıdır.
- API'ler ve eklentiler aracılığıyla yazım denetimi, otomatik tamamlama ve özel arama gibi gelişmiş arama özelliklerini destekler.
- İndeksleme ve arama için Lucene'i kullanır.
Lucene nedir?
Apache Lucene, uygulamaya kolayca arama veya bilgi alma eklemenizi sağlayan açık kaynaklı bir Java arama kitaplığıdır. Çok yönlüdür, güçlüdür, doğrudur ve verimli bir arama algoritması üzerinde çalışır.
Lucene, tam metin arama yetenekleriyle bilinmesine rağmen belge sınıflandırma, veri analizi ve bilgi alma için de kullanılabilir. Ayrıca Almanca, Fransızca, İspanyolca, Çince, Japonca ve daha fazlası gibi İngilizce dışındaki birçok dili destekler.
İndeksleme nedir?
Tüm arama motorları indeksleme ile başlar. İndeksleme, hızlı aramayı kolaylaştırmak için orijinal verilerin yüksek verimli çapraz referans aramasında işlenmesidir.
Arama motorları verileri doğrudan indekslemez. Metinler önce belirteçlere (atomik öğeler) bölünür. Arama, arama dizinine başvurma ve sorguyla eşleşen belgeyi alma işlemidir.
İndekslemenin avantajları
- Hızlı ve doğru bilgi alma (toplar, ayrıştırır ve depolar)
- Dizine ekleme olmadan, arama motorunun her belgeyi taraması için daha fazla zamana ihtiyaç duyar
indeksleme akışı
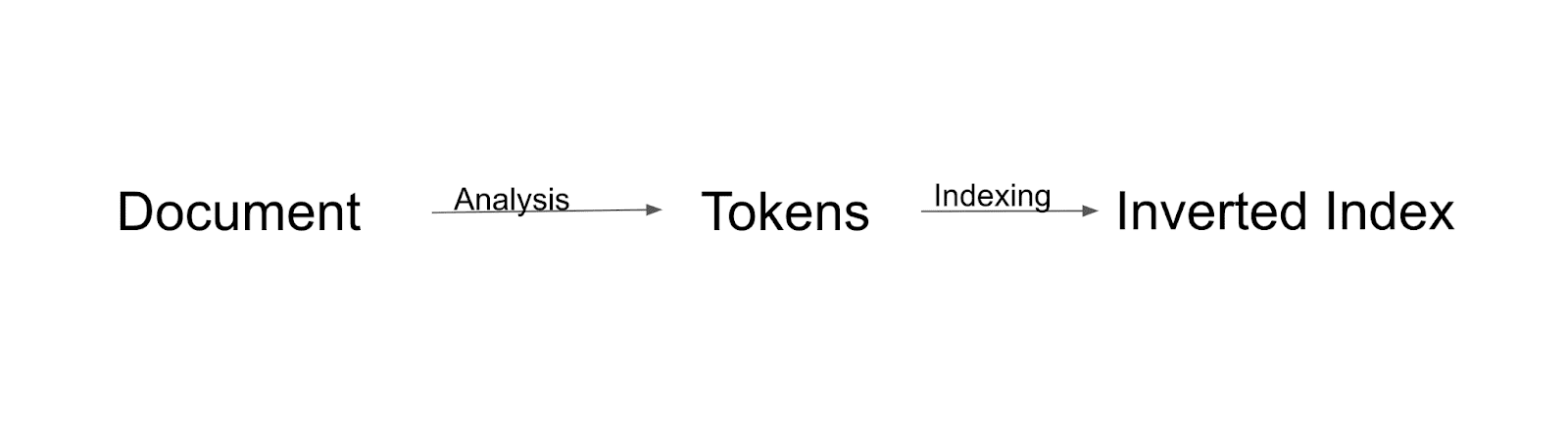
İlk olarak, belge analiz edilecek ve belirteçlere bölünecektir. Tüm bu belirteçler, tersine çevrilmiş dizine endekslenecektir. Tersine çevrilmiş dizin, Solr'un dizini oluşturduğu bir yoldur.
Ters indeksleme nasıl çalışır?
3 belgemiz olduğunu düşünelim:
- Çikolatayı seviyorum (D 1)
- Çikolatalı kek sipariş ettim (D 2)
- Büyük vanilyalı kek hazırladım (D 3)
Tokenize edilme şekli aşağıdaki tablonun 2. sütununda gösterildiği gibidir.

"Çikolata", D1 ve D2'de mevcuttur
"Kek", D2 ve D3'te mevcuttur
"Büyük" D3'te mevcuttur
"Sıralı" D2'de mevcuttur
"Hazırlandı" D3'te mevcuttur
D3'te “Vanilya” mevcuttur
"Ben", "aşk" gibi kelimelerin simgeleştirilmediğini fark edeceksiniz. Bunlar, Solr tarafından indekslenmeyecek veya aranamayacak Durdurma kelimeleri olarak adlandırılır.
Bu nedenle, birisi "Çikolatalı Kek" terimini aradığında, motor dizine bakar. Belge aramak yerine önce dizine bakarak “Çikolata” ve “Kek” kelimelerinin hangi belgelere girdiğini görüyor. Bu, yalnızca belirli belgeyi getirmeyi kolay ve hızlı hale getirir. Buna ters indeksleme denir.
Depolama Şeması
Apache Solr, belge tabanlı bir depolama şeması kullanır ve her veri parçasını bir koleksiyon içinde ayrı bir belge olarak depolar. Bu, verilerin verimli ve esnek bir şekilde depolanmasına ve alınmasına olanak tanır.
Drupal'da her düğüm bir belge olarak kabul edilir. Dolayısıyla, düğümünüzü Apache Solr'a endekslediğinizde, bu bir belge olarak kabul edilir. Her belge birden çok alan içerebilir. Lucene ortak bir küresel şemaya sahip değildir. Bu, Apache Solr'daki her belgedeki herhangi bir alan türünü indeksleyebileceğiniz anlamına gelir.

Apache Solr Nasıl Kurulur?
- Öncelikle, sisteminizde Java'nın kurulu olduğundan emin olun.
- Ardından Solr'u buradan yükleyelim: https://solr.apache.org/downloads.html
- Solr'u indirin ve çıkarın.
- Solr klasöründe bu komutu çalıştırın.
◦ bin/solr -e teknoloji ürünleri
Bu, gösterim için sahte bir çekirdek oluşturacak ve ayrıca Solr sunucusunu başlatacaktır.
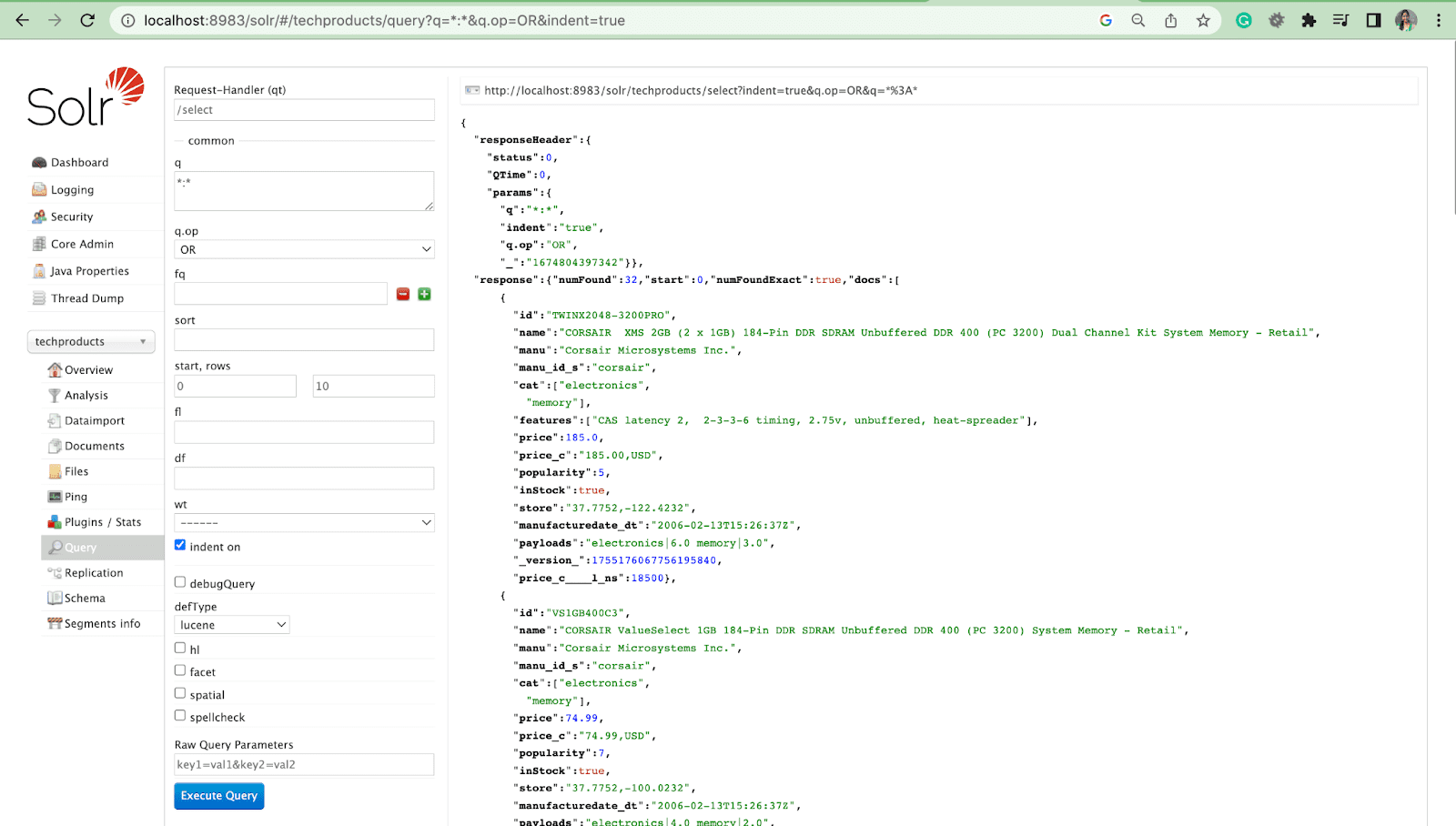
- Sunucu başladıktan sonra tarayıcınıza gidin ve “http://localhost:8983/” yazın.
- Solr'ın sahte çekirdekle başarıyla kurulduğundan emin olun.
Dizin Yapısı
Solr'u kurduktan sonra, aşağıdaki gibi birçok klasör göreceksiniz:
Belgeler - Solr hakkında belgeler içerir
Dist - Solr ana .jar dosyası
Contrib - eklenti eklentilerini ve Solr'un özel özelliklerini içerir
Bin - Solr komut dosyaları
Örnek - solr yeteneklerini göstermeyi içerir
Sunucu - Solr'un kalbi. Solr web uygulamasını, günlükleri, Solr çekirdeğini içerir

yapılandırma dosyaları
Bir çekirdek oluşturmak için zorunlu iki dosyaya ihtiyacımız var.
- Schema.xml
- Solrconfig.xml
Schema.xml
- Desteklemeyi planladığınız alan türlerini ve bu türlerin nasıl analiz edilmesi gerektiğini içerecektir.
Solrconfig.xml
- İstek işleyici, istek gönderici, sorgu bileşenleri, güncelleme işleyicileri vb. gibi bir Solr çekirdeğinin davranışını kontrol eden çeşitli ayarlar içerir.
Solr'da sorgulama
Şimdi Solr yönetici arayüzünde Solr sonuçlarının nasıl sorgulanacağını görelim.
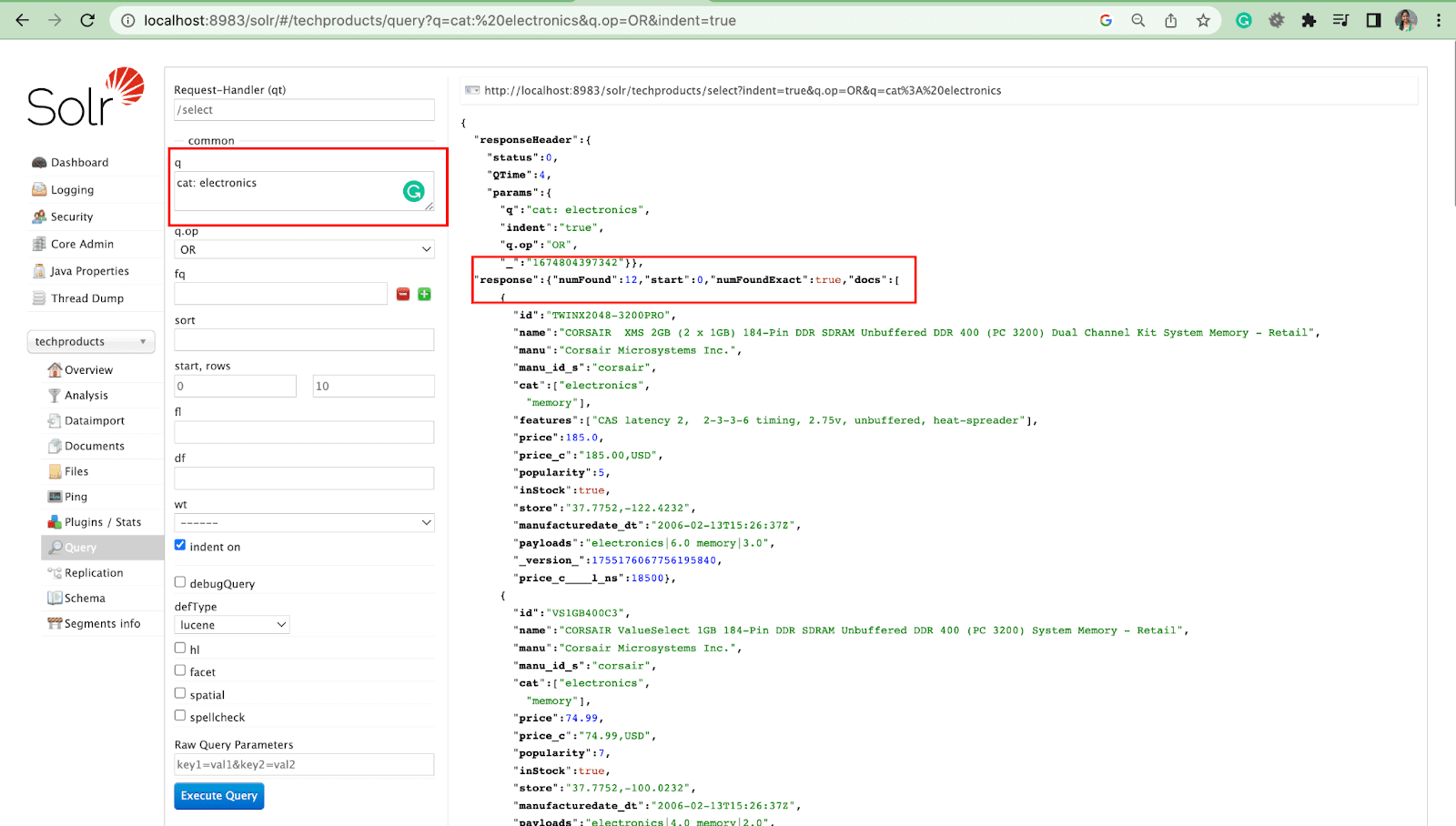
Sorgu Parametresi
- Yerel parametreler, bir Solr isteğindeki bir sorgu parametresine özgü bağımsız değişkenlerdir.
Örneğin: kedi: elektronik
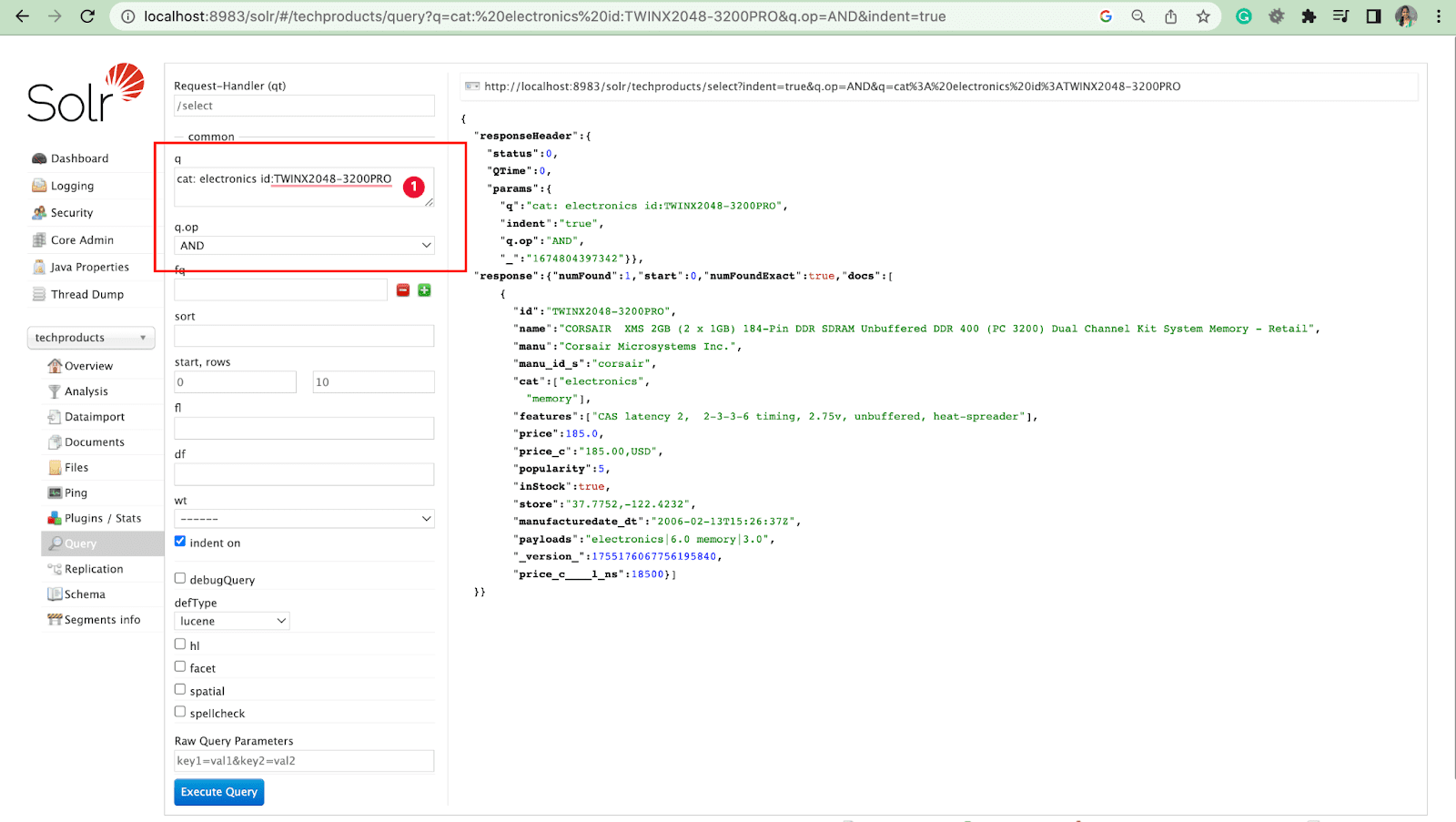
İşlemlerle Sorgu Parametresi
- İşlem ile birden çok alanı sorgulayabiliriz.
Örneğin: cat: elektronik kimliği:TWINX2048-3200PRO, q.op AND ile
[VEYA]
kedi: elektronik VE kimlik:TWINX2048-3200PRO
[VEYA]
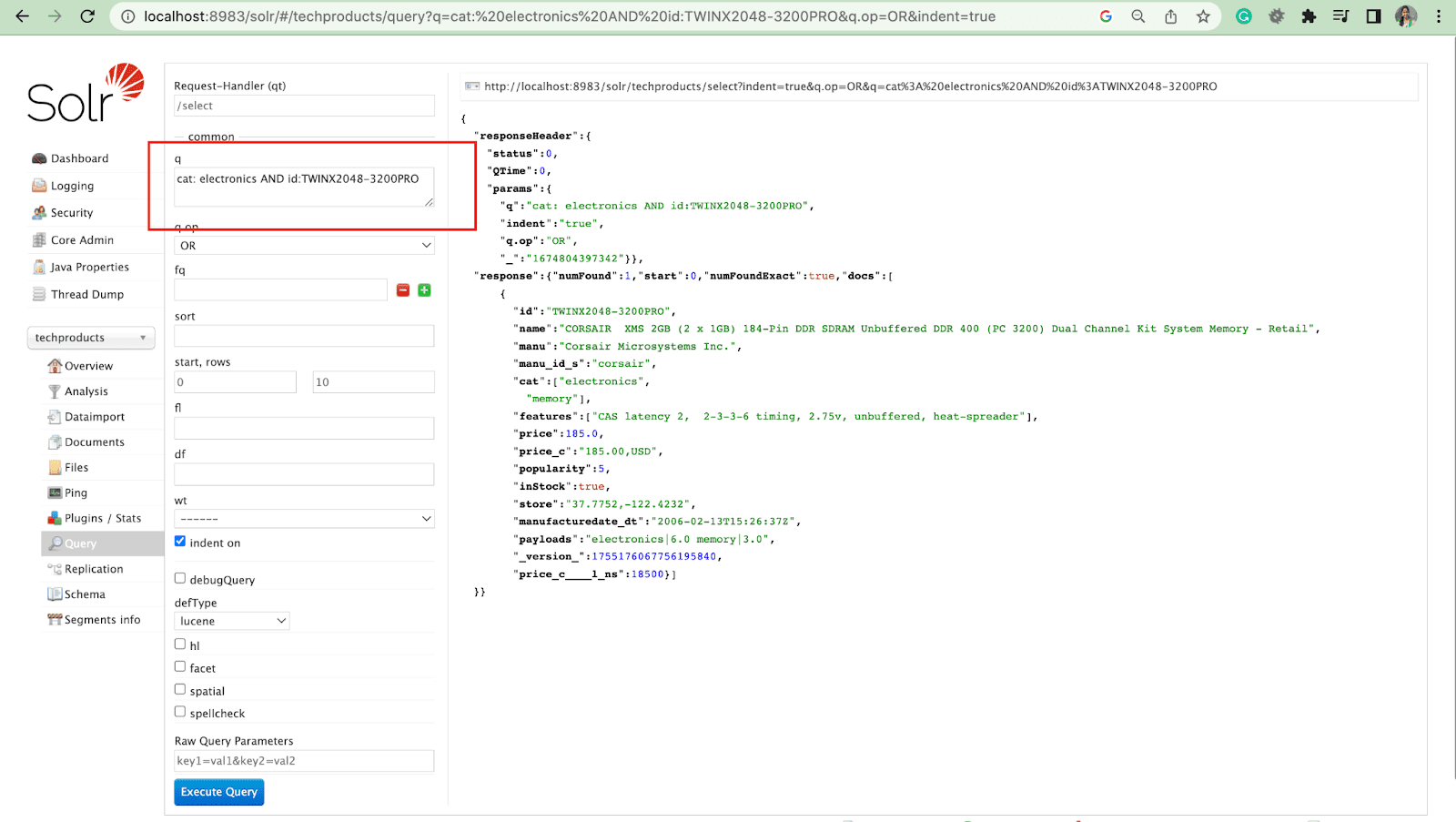
Filtre Sorgusu
Bir filtre sorgusu, bir aramanın sonuçlarını daraltmaya yardımcı olur. Puanı etkilemeden üst kümede hangi belgelerin döndürüleceğini kısıtlamak için fq parametresi tarafından bir sorgu belirtilebilir.
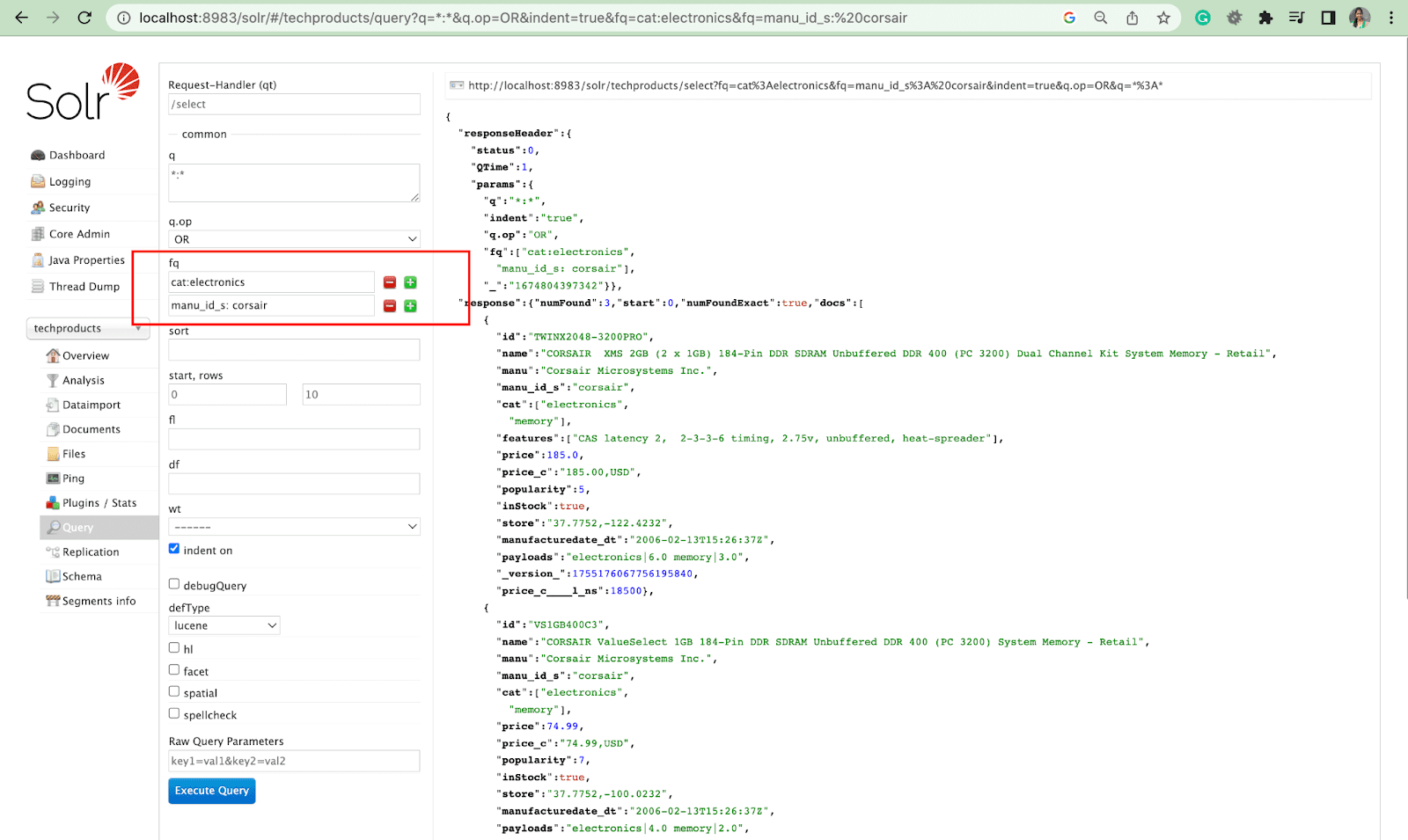
Sıralama Parametresi
sort parametresi, arama sonuçlarını artan (artan) veya azalan (azalan) düzende düzenler. İçeriğe bağlı olarak, parametre sayısal veya alfabetik olarak kullanılabilir.
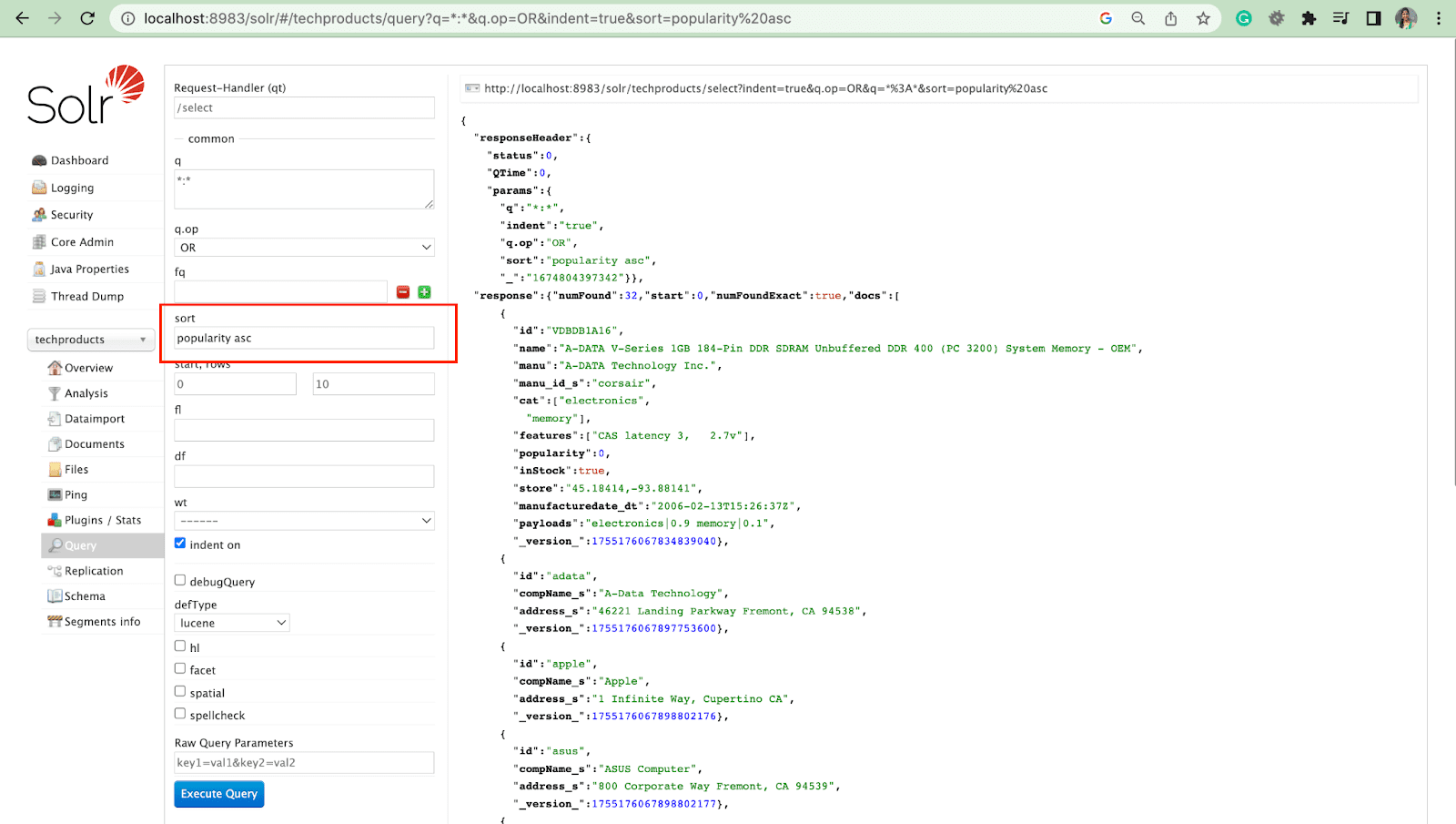
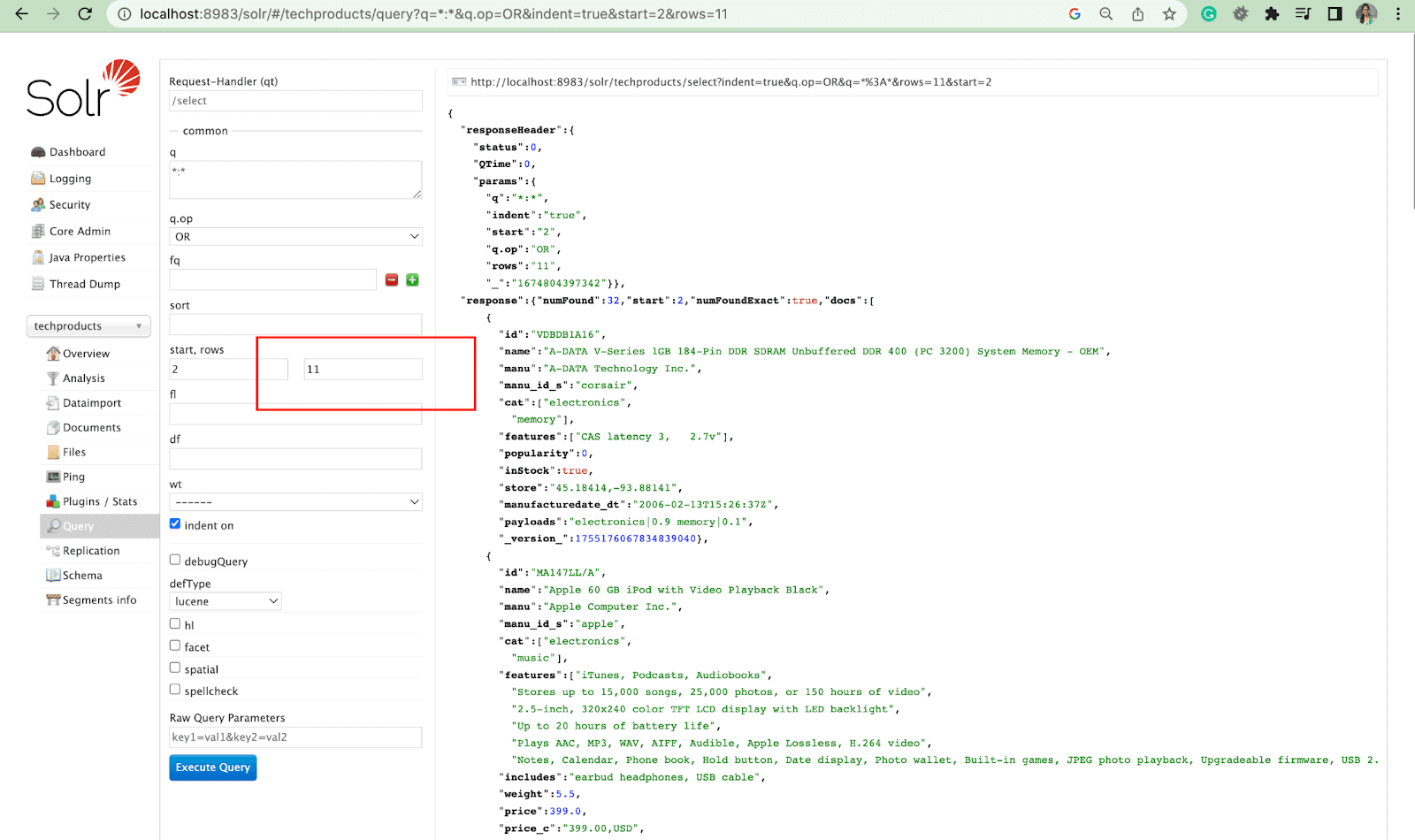
Satırlar Parametresi
Rows parametresi, bir sorgudan sonuçları sayfalandırmanıza izin verir.
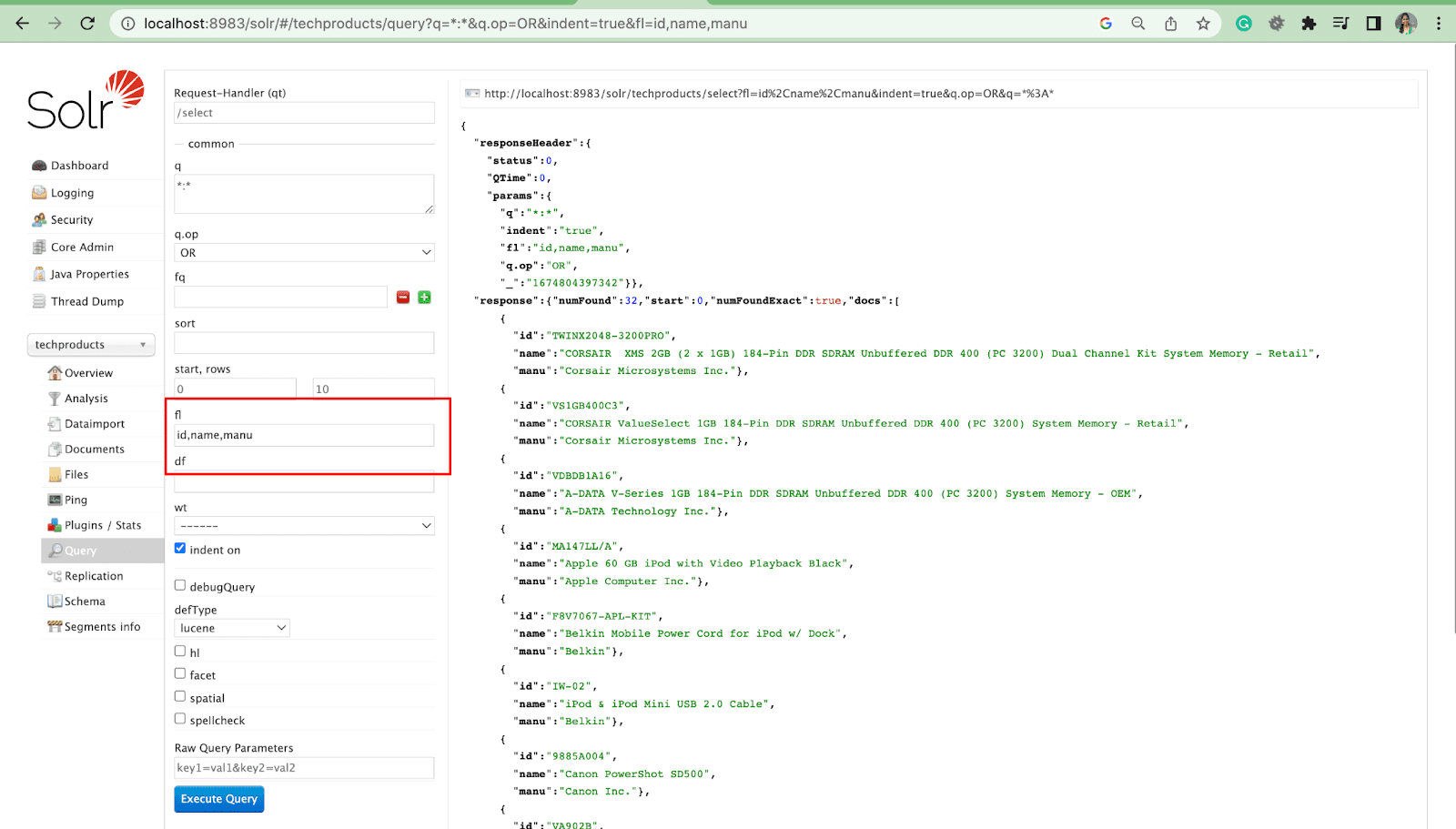
Alan Listesi Parametresi
fl parametresi, bir sorgu yanıtında bulunan bilgileri belirli bir alan listesiyle sınırlar.
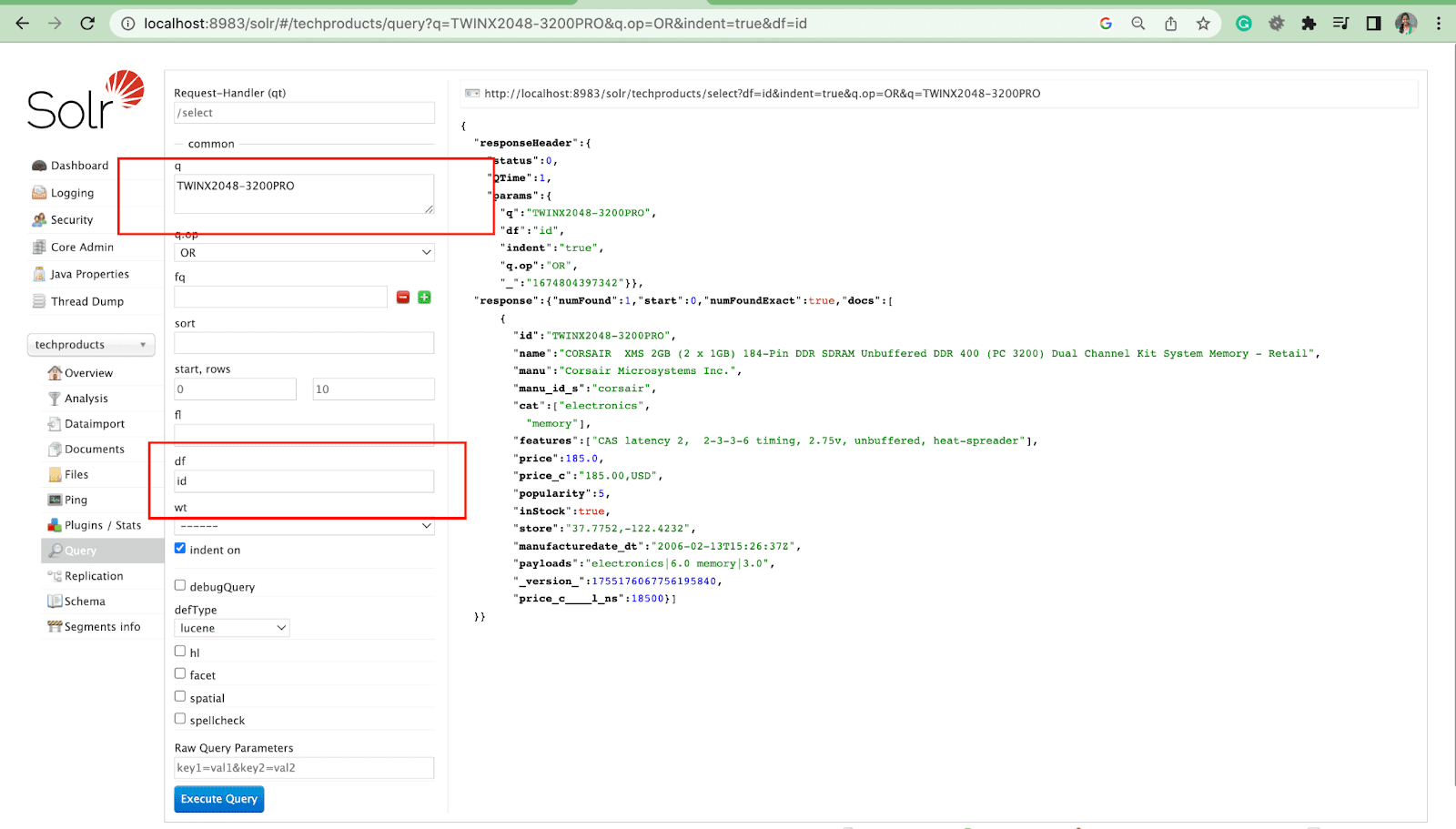
Varsayılan alan Parametre
Varsayılan alan parametresi, sorgu parametresi için varsayılan alandır.
Öne Çıkanlar Parametresi
Solr'daki vurgulama özelliği, bir sorguyla eşleşen belge parçalarının dahil edilmesini sağlar.
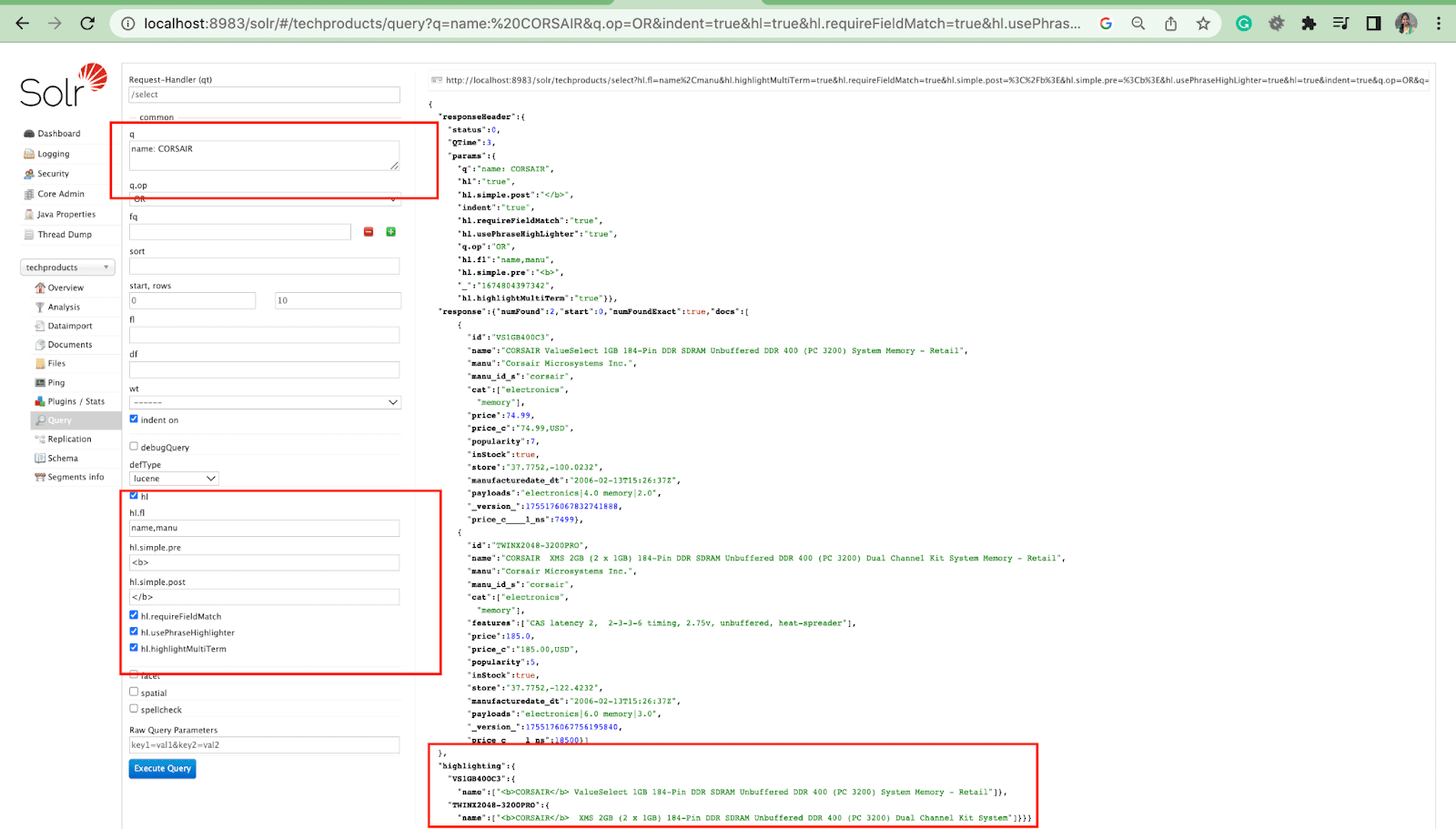
En yaygın vurgulama parametrelerinden bazıları şunlardır:
- Hl.fl - Bir alan listesini vurgular.
- Hl.simple.pre - Vurgulanan bir kelimeden önce hangi "etiketin" kullanılması gerektiğini belirtir.
- Hl.simple.post - Vurgulanan bir terimden sonra hangi "etiketin" kullanılması gerektiğini belirtir.
- hl.highlightMultiTerm - true olarak ayarlanırsa Solr, joker karakter sorgularını vurgulayacaktır. false ise, hiç vurgulanmazlar.
Yön:
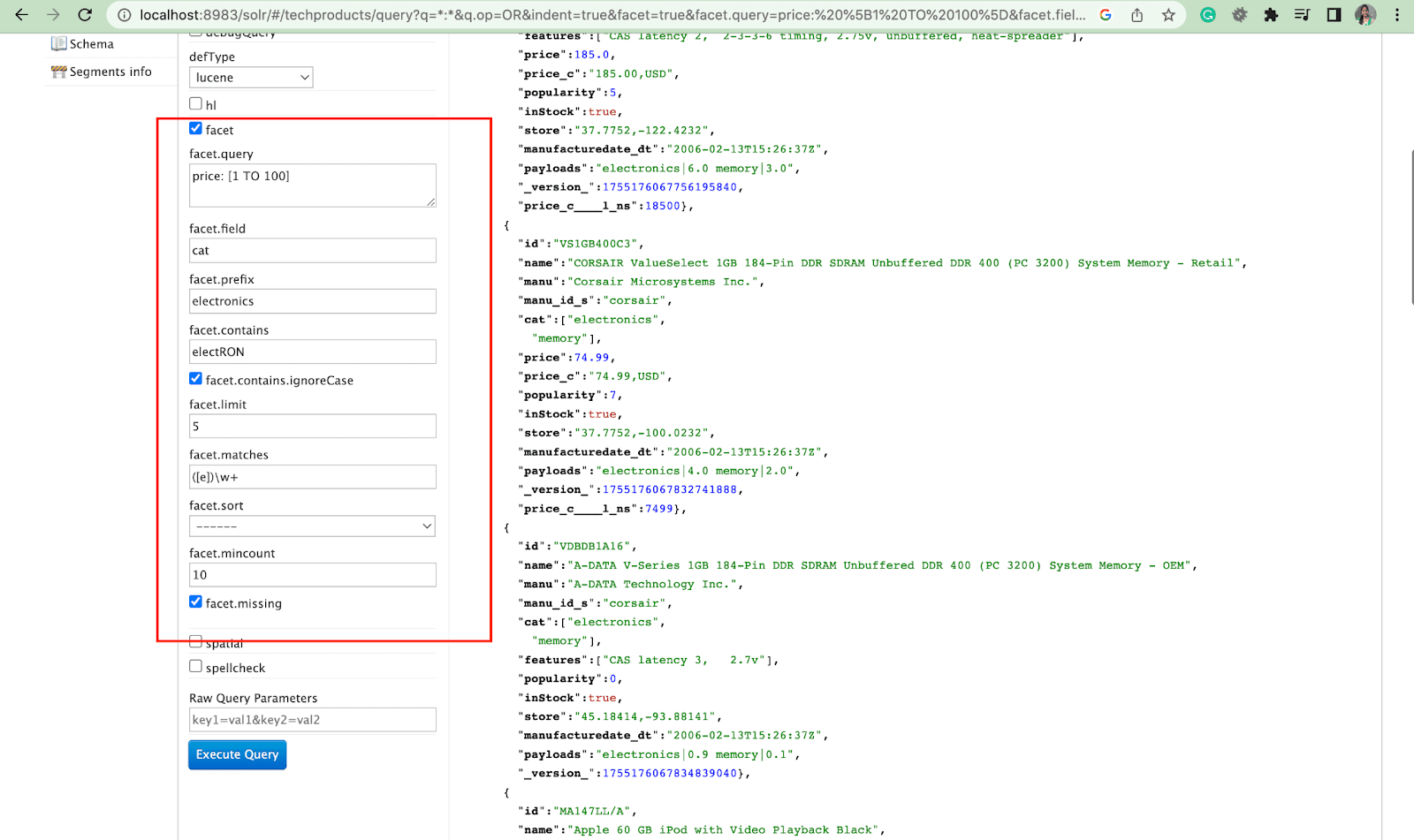
Yönler, kullanıcıların büyük arama sonuçları kümelerini keşfetmesine ve hassaslaştırmasına olanak tanır. Bir kullanıcı arayüzünde onay kutuları, açılır menüler veya diğer kontroller olarak görüntülenirler. Yönleri kontrol etmek için iki genel parametre şunlardır:
- model parametresi
Model parametresini kullanarak kullanıcılar, arama dizinlerindeki bir veya daha fazla alanın değerlerine dayalı olarak özellikler oluşturabilir. Arama sonuçlarında, model parametresi, modellerin nasıl oluşturulduğunu ve görüntülendiğini kontrol etmek için yapılandırılabilir.
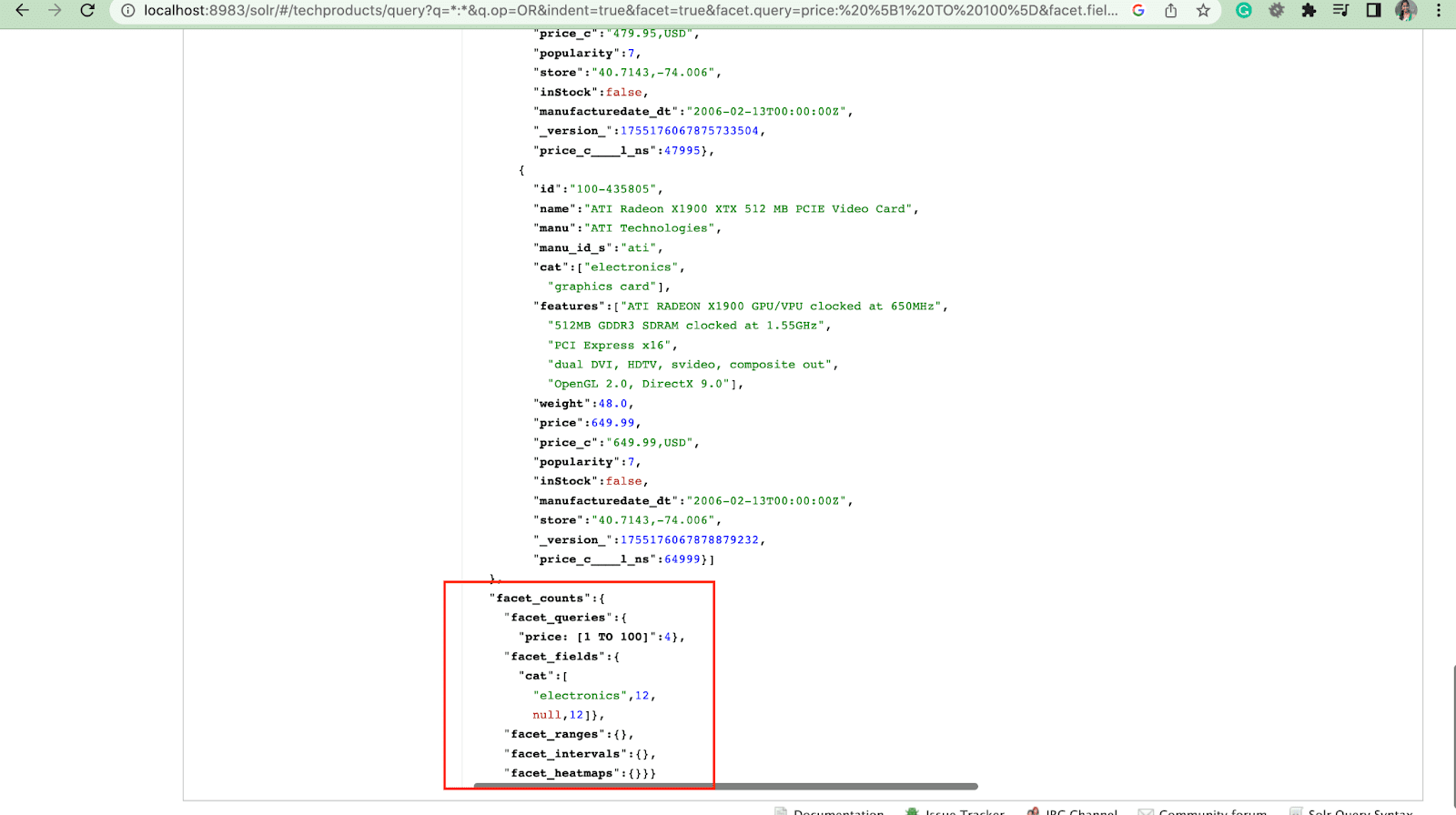
2. Facet.query parametresi
Bir kullanıcı, Solr sorgusuna bir facet.query parametresi eklediğinde, Solr, dizindeki her sorguyla eşleşen belgelerin sayısına karşılık gelen bir model sayıları listesi oluşturur. Facet.query, basit bir alan değeri kullanılarak kolayca temsil edilemeyen karmaşık arama ölçütlerine dayalı özellikler oluşturmak istediğinizde kullanışlıdır.
facet.field ( fasetleri oluşturmak için kullanılması gereken alanları belirtmek için) , facet.limit (her alan için görüntülenecek maks . yanıta dahil edilecek model) , facet.sort (faset değerlerinin görüntülenmesi gereken sırayı belirtir) .
Son düşünceler
Apache Solr, gereksinimlerinize göre özelleştirilebilen birçok ilginç özellikle gelen çok yönlü bir arama motorudur. Drupal, Apache Solr ile son derece iyi çalışır. Yeni projeniz için güçlü bir arama motoru yapılandırmak üzere Drupal uzmanları arıyorsanız, bunu daha da ileri götürmek isteriz!