
การทำคลัสเตอร์ล้มเหลวคืออะไร? มันทำงานอย่างไร + โซลูชั่น
เผยแพร่แล้ว: 2023-09-22บริษัทที่ต้องการทำธุรกรรมออนไลน์ไม่สามารถยอมให้เซิร์ฟเวอร์พังได้ ด้วยเหตุนี้ ธุรกิจเหล่านี้จึงมองหาวิธีสร้างขั้นตอนความปลอดภัยเมื่อเกิดเหตุขัดข้องเพื่อรักษาข้อมูลให้ปลอดภัยแม้ว่าเซิร์ฟเวอร์จะล่มก็ตาม วิธีหนึ่งดังกล่าวคือการทำคลัสเตอร์ล้มเหลว
การทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดสามารถควบคุมได้โดยโซลูชันผู้ให้บริการระบบชื่อโดเมนที่ได้รับการจัดการ (DNS) อย่างไรก็ตาม การทำความเข้าใจกลไกและคุณสมบัติหลักสามารถช่วยจำกัดความท้าทายในการเฟลโอเวอร์ได้
การทำคลัสเตอร์ล้มเหลวคืออะไร?
การทำคลัสเตอร์ล้มเหลวทำงานบนกลุ่มของเซิร์ฟเวอร์คอมพิวเตอร์เพื่อรับประกันความพร้อมใช้งานสูง (HA) หรือความพร้อมใช้งานต่อเนื่อง (CA) สำหรับแอปพลิเคชันเซิร์ฟเวอร์ เทคโนโลยีนี้ช่วยให้แน่ใจว่าหากเซิร์ฟเวอร์หรือโหนดหนึ่งล้มเหลว โหนดคลัสเตอร์อื่นก็พร้อมที่จะรับภาระงานโดยไม่หยุดชะงัก
แนวทางนี้ช่วยให้ปริมาณงานเซิร์ฟเวอร์ของคุณปรับขนาดได้และพร้อมใช้งาน โปรแกรมเซิร์ฟเวอร์หลักหลายโปรแกรม เช่น Microsoft Exchange , Microsoft SQL Server และ Hyper-V อาศัยการทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดเพื่อปกป้องตนเอง
คลัสเตอร์ ล้มเหลว บางคลัสเตอร์ใช้เซิร์ฟเวอร์จริง ในขณะที่คลัสเตอร์อื่นๆ ใช้ เครื่องเสมือน (VM) ทุกคนเลือกประเภทของคลัสเตอร์ที่ต้องการโดยอิงตามข้อกำหนดของแอปพลิเคชันเซิร์ฟเวอร์ของตน
คลัสเตอร์ประกอบด้วยโหนดตั้งแต่สองโหนดขึ้นไปที่แลกเปลี่ยนข้อมูลและซอฟต์แวร์เพื่อประมวลผลผ่านสายเคเบิลจริงหรือเครือข่ายที่ปลอดภัยเฉพาะทาง เทคโนโลยีการทำคลัสเตอร์หลายประเภทสามารถใช้สำหรับการทำโหลดบาลานซ์ การจัดเก็บ และการประมวลผลพร้อมกันหรือแบบขนาน ในบางกรณี คลัสเตอร์เฟลโอเวอร์จะถูกรวมเข้ากับเทคโนโลยีการทำคลัสเตอร์เพิ่มเติม
ฟังก์ชันหลักของคลัสเตอร์ล้มเหลวคือการจัดเตรียม CA หรือ HA สำหรับแอปพลิเคชันและบริการ คลัสเตอร์ CA หรือที่เรียกว่าคลัสเตอร์ที่ทนต่อความล้มเหลว (FT) ช่วยให้ผู้ใช้ปลายทางใช้แอปพลิเคชันและบริการต่อไปได้ แม้ว่าเซิร์ฟเวอร์จะล้มเหลวก็ตาม คุณอาจพบว่าบริการหยุดชะงักช่วงสั้นๆ ที่เกิดจากคลัสเตอร์ HA แต่ระบบสามารถกู้คืนได้โดยไม่มีข้อมูลสูญหายและมีเวลาหยุดทำงานเพียงเล็กน้อย
เหตุใดการทำคลัสเตอร์ล้มเหลวจึงมีความสำคัญ
ด้วยการทำคลัสเตอร์ล้มเหลว คุณสามารถซ่อมแซมโหนดที่ไม่ได้ใช้งานโดยไม่ต้องปิดฐานข้อมูลของคุณ หลีกเลี่ยงปัญหาการหยุดทำงานในขณะที่ซ่อมแซมเซิร์ฟเวอร์ที่เสียหายอย่างรวดเร็ว นอกจากนี้ ในกรณีที่ฮาร์ดแวร์ขัดข้อง เทคนิคนี้จะยุติฐานข้อมูลเพื่อปกป้องโหนดที่ใช้งานอยู่
การทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดยังทำให้การกู้คืนข้อมูลเป็นอัตโนมัติในกรณีที่เกิดความล้มเหลว ซึ่งจะช่วยลดการพึ่งพาทีมงานเทคโนโลยีสารสนเทศ (IT) และช่วยให้เซิร์ฟเวอร์ของคุณสามารถกู้คืนได้อย่างรวดเร็ว นอกจากนี้ยังมอบความพร้อมใช้งานของคลัสเตอร์ภาษาคิวรีที่มีโครงสร้าง (SQL) ที่ยอดเยี่ยมโดยมีเวลาหยุดทำงานน้อยที่สุด ฟังก์ชันการทำงานเฟลโอเวอร์แบบอัตโนมัติของการทำคลัสเตอร์เฟลโอเวอร์จะรักษาฟังก์ชันของฐานข้อมูลของคุณ แม้ว่าฮาร์ดแวร์จะพังก็ตาม
คลัสเตอร์เฟลโอเวอร์ทำงานอย่างไร
การทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดประกอบด้วยกระบวนการพื้นฐานสองกระบวนการ ได้แก่ HA และ CA สำหรับแอปพลิเคชันเซิร์ฟเวอร์
แม้ว่าคลัสเตอร์ล้มเหลวของ CA จะพยายามเข้าถึงความพร้อมใช้งาน 100% แต่คลัสเตอร์ HA พยายามอย่างเต็มที่เพื่อให้ได้ 99.999% หรือที่เรียกกันทั่วไปว่า Five Nines เวลาหยุดทำงานนี้รวมไม่เกิน 5.26 นาทีในแต่ละปี คลัสเตอร์ CA มีความพร้อมใช้งานสูงกว่าแต่ต้องใช้ฮาร์ดแวร์มากขึ้นในการทำงาน ส่งผลให้ต้นทุนโดยรวมเพิ่มขึ้น
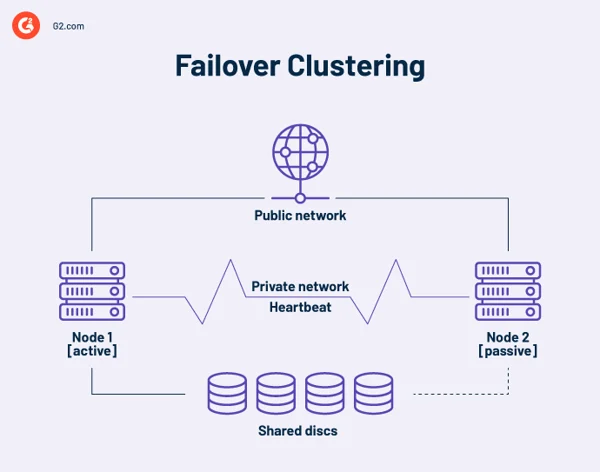
คลัสเตอร์ล้มเหลวความพร้อมใช้งานสูง
คลัสเตอร์ความพร้อมใช้งานสูงคือชุดของคอมพิวเตอร์อิสระที่ใช้ทรัพยากรและข้อมูลร่วมกัน โหนดของคลัสเตอร์ล้มเหลวสามารถเข้าถึงพื้นที่เก็บข้อมูลที่ใช้ร่วมกัน ลิงก์การตรวจสอบยังรวมอยู่ในคลัสเตอร์ที่มีความพร้อมใช้งานสูงเพื่อตรวจสอบการเต้นของ หัวใจ หรือความสมบูรณ์ของเซิร์ฟเวอร์อื่น ฮาร์ทบีทคือเครือข่ายส่วนตัวที่ใช้ร่วมกันโดยโหนดในคลัสเตอร์เท่านั้น ไม่สามารถเข้าถึงได้จากภายนอก
ณ จุดใดก็ตาม อย่างน้อยหนึ่งโหนดในคลัสเตอร์จะทำงานอยู่ และอย่างน้อยหนึ่งโหนดอยู่เฉยๆ หรืออยู่เฉยๆ
ในการจัดเรียงสองโหนดพื้นฐาน หากโหนด 1 ล้มเหลว โหนด 2 จะรับรู้ถึงความล้มเหลวผ่านการเชื่อมต่อฮาร์ทบีท และกำหนดค่าตัวเองเป็นโหนดที่ใช้งานอยู่ ซอฟต์แวร์การทำคลัสเตอร์ในแต่ละโหนดรับประกันว่าไคลเอนต์จะเชื่อมต่อกับโหนดที่ใช้งานอยู่
การติดตั้งขนาดใหญ่อาจใช้เซิร์ฟเวอร์เฉพาะเพื่อจัดการคลัสเตอร์ เซิร์ฟเวอร์การจัดการคลัสเตอร์จะส่งสัญญาณฮาร์ทบีทเพื่อระบุโหนดที่ล้มเหลวเสมอ และหากเป็นเช่นนั้น จะแจ้งให้โหนดอื่นรับงานแทน
เครื่องมือซอฟต์แวร์การจัดการคลัสเตอร์บางตัวจัดการ HA สำหรับ VM โดยการจัดกลุ่มเครื่องและเซิร์ฟเวอร์ลงในคลัสเตอร์ หากโฮสต์ล้มเหลว โฮสต์อื่นจะดำเนินต่อ VM
เนื่องจากจุดล้มเหลวจุดเดียวที่เป็นไปได้ พื้นที่เก็บข้อมูลที่ใช้ร่วมกันจึงมีความเสี่ยง อย่างไรก็ตาม การรวมอาร์เรย์สำรองของดิสก์อิสระ 6 และ 10 หรือที่เรียกว่า RAID 6 และ RAID 10 เข้าด้วยกัน สามารถช่วยรักษาบริการได้แม้ว่าฮาร์ดไดรฟ์สองตัวจะล้มเหลวก็ตาม
พลังงานไฟฟ้าอาจเป็นอีกจุดหนึ่งของความล้มเหลวหากเซิร์ฟเวอร์ทั้งหมดเชื่อมต่อกับกริดเดียวกัน การจัดหาเครื่องสำรองไฟ (UPS) ของตัวเองให้กับแต่ละโหนดจะช่วยปกป้องโหนดเหล่านั้น
คลัสเตอร์ล้มเหลวความพร้อมใช้งานอย่างต่อเนื่อง
คลัสเตอร์ที่ทนต่อข้อผิดพลาดต่างจากกระบวนทัศน์ HA ประกอบด้วยคอมพิวเตอร์จำนวนมากที่ใช้สำเนา ระบบปฏิบัติการ (OS) ของคอมพิวเตอร์ชุดเดียว คำสั่งซอฟต์แวร์ที่ให้กับระบบหนึ่งจะถูกดำเนินการบนระบบอื่นด้วย
CA ยืนยันว่าองค์กรใช้อุปกรณ์คอมพิวเตอร์ที่ได้รับการฟอร์แมตและ UPS สำรอง CA ต้องการแบบจำลองของระบบจริงหรือเสมือนที่ใช้บริการอยู่ตลอดเวลาและเกือบจะสมบูรณ์แบบ แบบจำลองความซ้ำซ้อนนี้เรียกว่า 2N
ระบบ CA สามารถชดเชยข้อผิดพลาดได้หลากหลาย ระบบที่ทนทานต่อข้อผิดพลาดอาจระบุการทำงานผิดปกติของ:
- ฮาร์ดดิสก์ไดรฟ์
- หน่วยประมวลผลในคอมพิวเตอร์
- ระบบย่อยสำหรับอินพุตและเอาต์พุต (I/O)
- แหล่งพลังงาน
- ส่วนประกอบของเครือข่าย
จุดที่เกิดความล้มเหลวอาจถูกค้นพบได้ทันที และส่วนประกอบหรือวิธีการสำรองสามารถเข้ามาแทนที่ได้ทันทีโดยไม่กระทบต่อบริการถัดไป
ซอฟต์แวร์การทำคลัสเตอร์สามารถเชื่อมต่อเซิร์ฟเวอร์ตั้งแต่สองเครื่องขึ้นไปเพื่อให้ทำงานเป็นเซิร์ฟเวอร์เสมือนเครื่องเดียว หรือสร้างการกำหนดค่าคลัสเตอร์ล้มเหลวของ CA ทางเลือกต่างๆ ตัวอย่างเช่น หากเซิร์ฟเวอร์เสมือนตัวใดตัวหนึ่งล้มเหลว เซิร์ฟเวอร์อื่นจะตอบสนองโดยการลบเซิร์ฟเวอร์เสมือนออกจากควอรัมของคลัสเตอร์ชั่วคราว เซิร์ฟเวอร์เสมือนจะกระจายภาระไปยังเซิร์ฟเวอร์อื่น ๆ จนกว่าเซิร์ฟเวอร์ที่เสียหายจะพร้อมที่จะรีสตาร์ท
เซิร์ฟเวอร์ฮาร์ดแวร์ คู่ ที่มีส่วนประกอบทางกายภาพทั้งหมดถูกจำลองแบบเป็นทางเลือกแทนคลัสเตอร์ล้มเหลวของ CA โดยจะคำนวณแยกกันและพร้อมกันบนแพลตฟอร์มฮาร์ดแวร์ต่างๆ และซิงโครไนซ์โดยใช้โหนดเฉพาะที่ตรวจสอบผลลัพธ์จากเซิร์ฟเวอร์จริงทั้งสองเครื่อง แม้ว่าโซลูชันนี้จะให้การปกป้อง แต่ก็อาจมีราคาแพงกว่า
คุณสมบัติการทำคลัสเตอร์ล้มเหลว
องค์กรจำนวนมากใช้การทำคลัสเตอร์ล้มเหลวสำหรับแอปพลิเคชันที่มีภารกิจสำคัญ เนื่องจากคุณลักษณะต่อไปนี้ทำให้การทำคลัสเตอร์ล้มเหลวเป็นเทคนิคที่สำคัญ
- ความสามารถในการปรับขนาด : เนื่องจากการทำคลัสเตอร์ล้มเหลวจะขึ้นอยู่กับกลุ่มของคลัสเตอร์ที่ทำงานร่วมกันเพื่อป้องกันความล้มเหลวของเซิร์ฟเวอร์ คุณจึงสามารถปรับขนาดได้อย่างง่ายดายและพร้อมตามต้องการโดยการเพิ่มคลัสเตอร์ใหม่
- ความเสถียร: เซิร์ฟเวอร์แบบคลัสเตอร์เชื่อมต่อผ่านสาย คลัสเตอร์ที่เหลือยังสามารถให้บริการได้ แม้ว่าอย่างน้อยหนึ่งคลัสเตอร์จะล้มเหลวเนื่องจากปัจจัยภายนอก
- การตรวจสอบแบบเรียลไทม์: โหนดคลัสเตอร์ได้รับการตรวจสอบอย่างต่อเนื่องเพื่อให้แน่ใจว่าทำงานได้อย่างถูกต้อง เมื่อคลัสเตอร์เริ่มต้นใหม่หรือถ่ายโอนไปยังโหนดอื่น
- ไดรฟ์ข้อมูลที่ใช้ร่วมกันของคลัสเตอร์ (CSV): คุณลักษณะนี้มอบเนมสเปซที่สอดคล้องและกระจายสำหรับโหนดที่จะใช้ในขณะที่ทำงานกับพื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกัน จำเป็นอย่างยิ่งที่จะต้องทำให้แอปพลิเคชันเซิร์ฟเวอร์ทำงานโดยไม่หยุดชะงักตั้งแต่ต้นจนจบ
ประเภทของคลัสเตอร์เฟลโอเวอร์
ความก้าวหน้าที่สำคัญในการทำคลัสเตอร์ล้มเหลวเกิดขึ้นในช่วงทศวรรษที่ผ่านมา โดยหลายองค์กรกำลังนำเสนอโซลูชันการทำคลัสเตอร์เวอร์ชันของตนเอง บริการคลัสเตอร์ทั่วไปบางส่วนมีรายละเอียดอยู่ที่นี่

คลัสเตอร์ล้มเหลวของ VMware
VMware นำเสนอเทคโนโลยีเวอร์ช่วลไลเซชั่นมากมายสำหรับคลัสเตอร์ VM สถาปัตยกรรม CA ของ vSphere vMotion จำลองเครื่องเสมือน VMware และเครือข่ายระหว่างเครือข่ายศูนย์ข้อมูลจริงได้อย่างแม่นยำ
VMware vSphere HA ซึ่งเป็นผลิตภัณฑ์ตัวที่สองมอบ HA สำหรับ VM โดยการจัดกลุ่มพวกเขาและโฮสต์ลงในคลัสเตอร์สำหรับการเฟลโอเวอร์อัตโนมัติ นอกจากนี้ โปรแกรมไม่ต้องอาศัยส่วนประกอบภายนอก เช่น DNS ซึ่งช่วยลดจุดที่เกิดความล้มเหลวที่อาจเกิดขึ้นได้
คลัสเตอร์ล้มเหลวเซิร์ฟเวอร์ Windows
วิธีการคลัสเตอร์ล้มเหลวเซิร์ฟเวอร์ Windows (WSFC) สนับสนุนการสร้างเซิร์ฟเวอร์ล้มเหลว Hyper-V ระหว่างปี 2559 ถึง 2562 กลยุทธ์นี้ได้รับความนิยมในหมู่ผู้ใช้ Microsoft Windows WSFC อนุญาตให้มีการตรวจสอบคลัสเตอร์และนำเสนอกลไกการเฟลโอเวอร์ที่จำเป็นโดยอัตโนมัติ ในกรณีที่เซิร์ฟเวอร์สูญเสีย WFSC จะย้ายคลัสเตอร์ไปยังโหนดที่แยกจากกันหรือพยายามรีสตาร์ทคลัสเตอร์ นอกจากนี้ เทคโนโลยี CSV ยังมีเนมสเปซแบบกระจายที่ช่วยให้หลายโหนดสามารถแชร์หน่วยความจำได้
เซิร์ฟเวอร์ SQL
ผลิตภัณฑ์ Microsoft นี้เปิดตัวพร้อมกับ SQL Server 2017 มีโซลูชัน HA ที่มีประสิทธิภาพซึ่งใช้เทคโนโลยี WSFC ส่วนประกอบเซิร์ฟเวอร์ SQL ถือเป็นทรัพยากรคลัสเตอร์ WSFC ในบริบทนี้ มีการบูรณาการเพิ่มเติมกับทรัพยากรอื่นๆ ที่ขึ้นกับ WSFC ด้วยเหตุนี้ WSFC จึงมีอำนาจในการระบุและสื่อสารคำสั่งเพื่อรีสตาร์ทอินสแตนซ์เซิร์ฟเวอร์ SQL หรือย้ายอินสแตนซ์ที่คล้ายกันไปยังโหนดใหม่
เรดแฮทลินุกซ์
นอกเหนือจาก Microsoft แล้ว ผู้จำหน่ายระบบปฏิบัติการรายอื่นยังมาพร้อมกับโซลูชันคลัสเตอร์ล้มเหลวของตนเอง ตัวอย่างเช่น แฟน ๆ ของ Red Hat Enterprise Linux (RHEL) สามารถใช้ส่วนขยาย HA และ Red Hat Global File System (GFS/GFS2) เพื่อสร้างคลัสเตอร์เฟลโอเวอร์ HA รองรับคลัสเตอร์แบบคลัสเตอร์เดี่ยวที่ครอบคลุมหลายตำแหน่งและคลัสเตอร์ ที่ทนทานต่อภัยพิบัติ หลายไซต์ การจำลองแบบการจัดเก็บข้อมูลเครือข่ายพื้นที่จัดเก็บข้อมูล (SAN) มักใช้ในคลัสเตอร์หลายไซต์
การประยุกต์ใช้การจัดกลุ่มเมื่อเกิดข้อผิดพลาด
กลไกที่แข็งแกร่งนี้อำนวยความสะดวกในการใช้งานแบบเรียลไทม์ต่อไปนี้
ความพร้อมใช้งานของแอปพลิเคชันที่สำคัญต่อภารกิจ
คอมพิวเตอร์ประมวลผลธุรกรรมออนไลน์ (OLTP) ต้องมีระบบป้องกันข้อผิดพลาด OLTP ซึ่งจำเป็นต้องมีความพร้อมโดยสมบูรณ์ ใช้สำหรับระบบการจองสายการบิน การซื้อขายหุ้นทางอิเล็กทรอนิกส์ และ ATM Banking
อุตสาหกรรมจำนวนมาก เช่น การผลิต การขนส่ง และการค้าปลีก ใช้คลัสเตอร์ CA หรือคอมพิวเตอร์ที่ทนทานต่อความล้มเหลวสำหรับแอปพลิเคชันที่สำคัญต่อภารกิจ อีคอมเมิร์ซ การจัดการคำสั่งซื้อ และระบบนาฬิกาบอกเวลาของพนักงานถือเป็นตัวอย่าง
คลัสเตอร์ที่มีความพร้อมใช้งานสูงมักจะยอมรับได้สำหรับการจัดคลัสเตอร์แอปพลิเคชันและบริการที่ต้องการเวลาทำงานเพียงห้าเก้าเท่านั้น
บรรเทาสาธารณภัย
การกู้คืนความเสียหายยังได้รับประโยชน์จากการทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดอีกด้วย ขอแนะนำอย่างยิ่งให้โฮสต์เซิร์ฟเวอร์เฟลโอเวอร์ที่ไซต์ระยะไกล เนื่องจากภัยพิบัติ เช่น ไฟไหม้หรือน้ำท่วมทำลายฮาร์ดแวร์และซอฟต์แวร์ทางกายภาพทั้งหมด
Storage Replica ซึ่งเป็นเทคโนโลยีที่ทำซ้ำโวลุ่มระหว่างเซิร์ฟเวอร์สำหรับ การกู้คืนระบบ รวมอยู่ใน Windows Server 2016 และ 2019 การยืดเวลาเฟลโอเวอร์เป็นคุณสมบัติเทคโนโลยีที่ช่วยให้คลัสเตอร์เฟลโอเวอร์ขยายได้สองตำแหน่ง
องค์กรสามารถ จำลองข้อมูล บนศูนย์ต่างๆ ได้โดยการขยายคลัสเตอร์เฟลโอเวอร์ หากเกิดโศกนาฏกรรมที่จุดหนึ่ง ข้อมูลทั้งหมดจะถูกเก็บรักษาไว้บนเซิร์ฟเวอร์สำรองที่จุดอื่น
การจำลองแบบของฐานข้อมูล
ตามข้อมูลของ Microsoft WSFC เปิดตัวครั้งแรกใน Windows Server 2016 เพื่อปกป้องบริการ "ภารกิจสำคัญ" เช่นฐานข้อมูลเซิร์ฟเวอร์ SQL และเซิร์ฟเวอร์การสื่อสาร Microsoft Exchange
สำหรับการจำลอง ฐานข้อมูล ผู้จำหน่ายรายอื่นจัดหาเทคโนโลยีคลัสเตอร์ล้มเหลว ตัวอย่างเช่น MySQL Cluster มีวิธีการแบบฮาร์ทบีทที่ช่วยให้สามารถตรวจจับความล้มเหลวได้อย่างรวดเร็วไปยังโหนดอื่นๆ ในคลัสเตอร์ ซึ่งมักจะใช้เวลาเพียงเสี้ยววินาที โดยที่บริการไม่หยุดชะงักกับไคลเอ็นต์
ฐานข้อมูลอาจถูกจำลองไปยังไซต์ที่อยู่ห่างไกลโดยใช้ความสามารถในการจำลองแบบทางภูมิศาสตร์
ประโยชน์ของคลัสเตอร์เฟลโอเวอร์
แนวคิดของคลัสเตอร์เฟลโอเวอร์คือเพื่อให้แน่ใจว่าผู้ใช้ประสบปัญหาการหยุดชะงักในบริการน้อยที่สุด อย่างไรก็ตาม ประโยชน์เพิ่มเติมอื่นๆ ของการทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดมีอธิบายไว้ด้านล่าง
- ความพร้อมใช้งานของทรัพยากรที่เพิ่มขึ้น: หากเซิร์ฟเวอร์อัจฉริยะเครื่องหนึ่งล้มเหลว เซิร์ฟเวอร์อื่นๆ ในคลัสเตอร์จะรับภาระ ซึ่งจะช่วยประหยัดเวลาและข้อมูลที่สำคัญ
- การจัดสรรทรัพยากรเชิงกลยุทธ์: คุณสามารถกระจายโปรเจ็กต์ระหว่างโหนดได้ตามที่คุณต้องการ วิธีนี้จะช่วยลดค่าใช้จ่ายให้เหลือน้อยที่สุด เนื่องจากคอมพิวเตอร์บางเครื่องไม่จำเป็นต้องดำเนินโครงการทั้งหมดพร้อมกัน ทำให้คุณใช้ทรัพยากรได้อย่างอิสระมากขึ้น
- พลังการประมวลผลที่เพิ่มขึ้น: เครื่องจักรมากขึ้น พลังงานมากขึ้น
- ความสามารถในการปรับขนาดได้มากขึ้น: เมื่อฐานผู้ใช้และความซับซ้อนของรายงานของคุณขยายตัว ทรัพยากรของคุณก็สามารถขยายออกไปได้เช่นกัน
- การจัดการที่ง่ายขึ้น: การจัดกลุ่มทำให้การจัดการระบบที่สำคัญหรือเปลี่ยนแปลงอย่างรวดเร็วทำได้ง่ายขึ้น
ข้อจำกัดของการทำคลัสเตอร์ล้มเหลว
แม้จะมีความสำคัญพอๆ กับการทำคลัสเตอร์ล้มเหลว แต่ก็มาพร้อมกับข้อจำกัดต่อไปนี้
- การกำหนดค่าที่ซับซ้อน: การกำหนดค่าการทำคลัสเตอร์ล้มเหลวสำหรับ Windows กำหนดให้คุณต้องจัดการเครือข่ายและการ์ดเครือข่ายจำนวนมากในคราวเดียว เป็นผลให้การปรับใช้วิธีนี้เป็นเรื่องยากโดยเฉพาะสำหรับผู้เริ่มต้น
- การรวมเครื่องมือ: การทำคลัสเตอร์ Windows Failover และ Hyper-V จะต้องบูรณาการอย่างใกล้ชิดยิ่งขึ้น คุณต้องปรับแต่ละรายการ เพื่อทำคลัสเตอร์เฟลโอเวอร์ให้สำเร็จ
- เว็บอินเตอร์เฟส: ไม่มี เว็บอินเตอร์เฟส สำหรับปรับพารามิเตอร์คลัสเตอร์ ในการเข้าถึงคุณสมบัติตัวจัดการคลัสเตอร์ คุณต้องล็อกอินเข้าสู่เดสก์ท็อประยะไกลด้วยตนเอง
โซลูชันการทำคลัสเตอร์เมื่อเกิดข้อผิดพลาด: ผู้ให้บริการ DNS ที่มีการจัดการ
ด้วยการทำงานร่วมกับระบบการทำคลัสเตอร์เฟลโอเวอร์ ผู้ให้บริการ DNS ที่มีการจัดการเปลี่ยนเส้นทางการรับส่งข้อมูลไปยังเซิร์ฟเวอร์หรือศูนย์ข้อมูลอื่นในระหว่างเหตุการณ์เฟลโอเวอร์ ทำให้มั่นใจได้ว่าการเข้าถึงบริการของคุณจะไม่หยุดชะงักเพื่อให้คุณมีความพร้อมใช้งานสูงและลดเวลาหยุดทำงานให้เหลือน้อยที่สุด
ผู้ให้บริการ DNS ที่มีการจัดการห้าอันดับแรก:
- DNS คลาวด์แฟลร์
- Azure DNS
- อินโฟบ็อกซ์ NIOS
- นักพัฒนา WPMU
- ตัวจัดการ DNS
* ด้านบนคือซอฟต์แวร์ผู้ให้บริการ DNS ที่มีการจัดการชั้นนำ 5 อันดับแรกจากรายงาน Grid Report ประจำฤดูใบไม้ร่วงปี 2023 ของ G2

ปรับปรุงความน่าเชื่อถือให้ทันสมัย
การทำคลัสเตอร์เมื่อเกิดข้อผิดพลาดกลายเป็นตัวเลือกที่เชื่อถือได้และจำเป็นสำหรับความพร้อมใช้งานสูงและความทนทานต่อข้อผิดพลาดภายในโครงสร้างพื้นฐานด้านไอทีในปัจจุบัน ให้การดำเนินงานอย่างต่อเนื่องแม้ว่าฮาร์ดแวร์จะล้มเหลวหรือการบำรุงรักษาตามกำหนดเวลาโดยการกระจายปริมาณงานและทรัพยากรไปยังโหนดเครือข่ายจำนวนมากโดยอัตโนมัติ เทคโนโลยีนี้ให้อีกวิธีหนึ่งในการจัดการกับส่วนที่สำคัญที่สุดของธุรกิจของคุณ ทำให้ประสบการณ์ของลูกค้าแต่ละรายปลอดภัยและมีความสุข
การเสริมความยืดหยุ่นให้กับระบบของคุณก็ไม่ทำให้เสียหายเช่นกัน!
เริ่มต้นด้วยคำแนะนำด้านความปลอดภัย DNS สำหรับกลยุทธ์ระบบที่แข็งแกร่ง