
Cum se configurează fișierul robots.txt Magento 2 pentru SEO
Publicat: 2021-01-21Cuprins
SEO este un factor important pentru succesul magazinului dvs., iar un robots.txt configurat corespunzător contribuie nu în mică măsură la ușurarea sarcinii crawlerilor motoarelor de căutare.
Ce este robots.txt?
Pe scurt, robots.txt este un fișier care instruiește crawlerele motoarelor de căutare despre ce pot sau nu pot accesa cu crawlere. Fără un fișier robots.txt în directorul dvs. rădăcină, crawlerele motoarelor de căutare care vin prin magazinul dvs. vor accesa cu crawlere tot ceea ce pot, iar aceasta include pagini duplicate sau neimportante pe care nu doriți ca crawlerele motoarelor de căutare să-și irosească bugetul de accesare cu crawlere. Un robots.txt ar trebui să poată aborda acest lucru.
Notă : fișierul robots.txt nu trebuie utilizat pentru a ascunde paginile dvs. web de Google. Ar trebui să utilizați metaeticheta noindex în acest scop.
Instrucțiuni robots.txt implicite în Magento 2
În mod implicit, fișierul robots.txt generat de Magento conține doar câteva instrucțiuni de bază pentru crawler-ul web.
# Instrucțiuni implicite furnizate de Magento Agent utilizator: * Nu permiteți: /lib/ Nu permiteți: /*.php$ Nu permiteți: /pkginfo/ Nu permiteți: /raport/ Nu permiteți: /var/ Nu permiteți: /catalog/ Nu permite: /client/ Nu permiteți: /sendfriend/ Nu permiteți: /review/ Nu permiteți: /*SID=
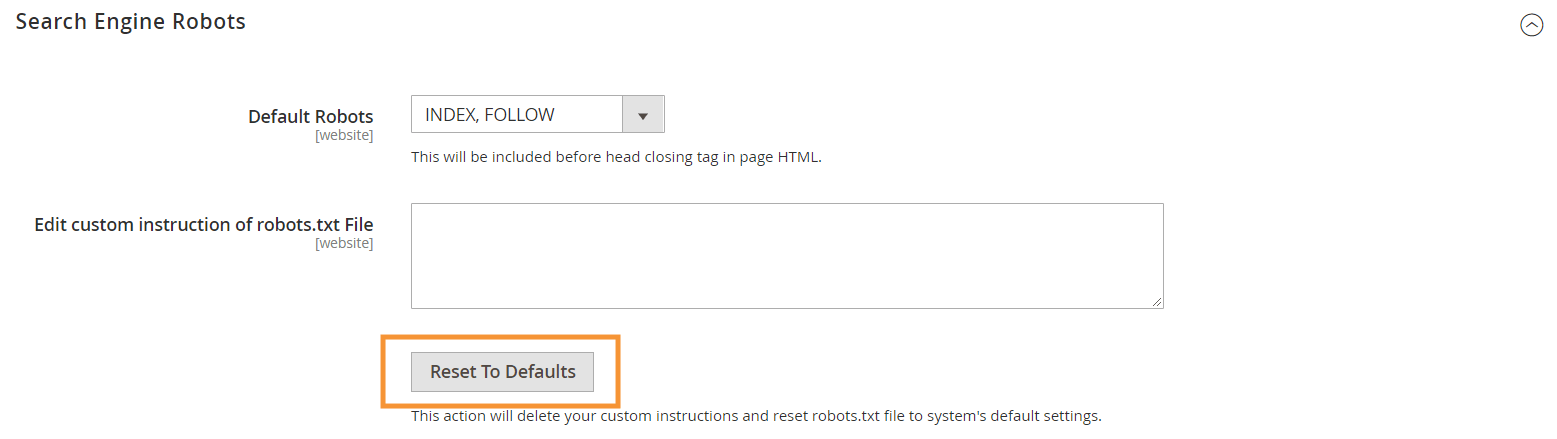
Pentru a genera aceste instrucțiuni implicite, apăsați butonul Reset to Defaults din configurația Search Engine Robots din backend-ul dvs. Magento.
De ce trebuie să creați instrucțiuni personalizate robots.txt în Magento 2
În timp ce instrucțiunile robots.txt implicite furnizate de Magento sunt necesare pentru a le spune crawlerilor să evite accesarea cu crawlere a anumitor fișiere care sunt utilizate intern de sistem, acestea nu sunt aproape suficiente pentru majoritatea magazinelor Magento.
Roboții motoarelor de căutare au doar o cantitate limitată de resurse pentru accesarea cu crawlere a paginilor web. Pentru ca un site cu mii sau chiar milioane de adrese URL de accesat cu crawlere (ceea ce este mai comun decât ați crede), va trebui să prioritizați tipul de conținut care trebuia accesat cu crawlere (cu un sitemap.xml) și să interziceți accesul cu crawlere. paginile de la accesarea cu crawlere (cu un fișier robots.txt). Ultima parte se realizează prin interzicerea accesării cu crawlere a paginilor duplicate, irelevante și inutile în robots.txt.
Formatul de bază al directivelor robots.txt
Instrucțiunile din robots.txt sunt prezentate într-o manieră coerentă, prietenoasă cu utilizatorii non-tehnici:
# Regula 1 Agent utilizator: Googlebot Nu permiteți: /nogooglebot/ # Regula 2 Agent utilizator: * Permite: / Harta site-ului: https://www.example.com/sitemap.xml
-
User-agent: indică crawler-ul specific pentru care se aplică regula. Unii agenți utilizatori obișnuiți suntGooglebot,Googlebot-Image,Mediapartners-Google,Googlebot-Video, etc. Pentru o listă extinsă a crawlerelor comune, consultați Prezentare generală a crawlerelor Google.
-
AllowșiDisallow: specificați căile pe care crawler-urile desemnate le pot sau nu le accesa. De exemplu,Allow: /înseamnă că crawler-ul poate accesa întregul site fără restricții.
-
Sitemap-ului : indică calea către harta site-ului pentru magazinul dvs. Sitemap-ul este o modalitate de a le spune crawlerilor motoarelor de căutare ce conținut să acorde prioritate, în timp ce restul conținutului din robots.txt le spune crawlerilor ce conținut pot sau nu pot accesa cu crawlere.
De asemenea, în robots.txt, puteți utiliza mai multe caractere metalice pentru valorile căii, cum ar fi:

-
*: Când este introdus înuser-agent, asteriscul (*) se referă la toate crawlerele motoarelor de căutare (cu excepția crawlerelor AdsBot) care vizitează site-ul. Când este utilizat în directiveleAllow/Disallow, înseamnă 0 sau mai multe instanțe ale oricărui caracter valid (de exemplu,Allow: /example*.cssse potrivește cu /example.css și, de asemenea, / example12345.css ). -
$: desemnează sfârșitul unei adrese URL. De exemplu,Disallow: /*.php$va bloca toate fișierele care se termină cu .php -
#: desemnează începutul unui comentariu, pe care crawlerele îl vor ignora.
Notă : cu excepția căii sitemap.xml, căile din robots.txt sunt întotdeauna relative , ceea ce înseamnă că nu puteți utiliza adrese URL complete (de exemplu, https://simicart.com/nogooglebot/) pentru a specifica căile.
Configurarea robots.txt în Magento 2
Pentru a accesa editorul de fișiere robots.txt, în administratorul Magento 2:
Pasul 1 : Accesați Conținut > Design > Configurare
Pasul 2 : Editați configurația globală în primul rând
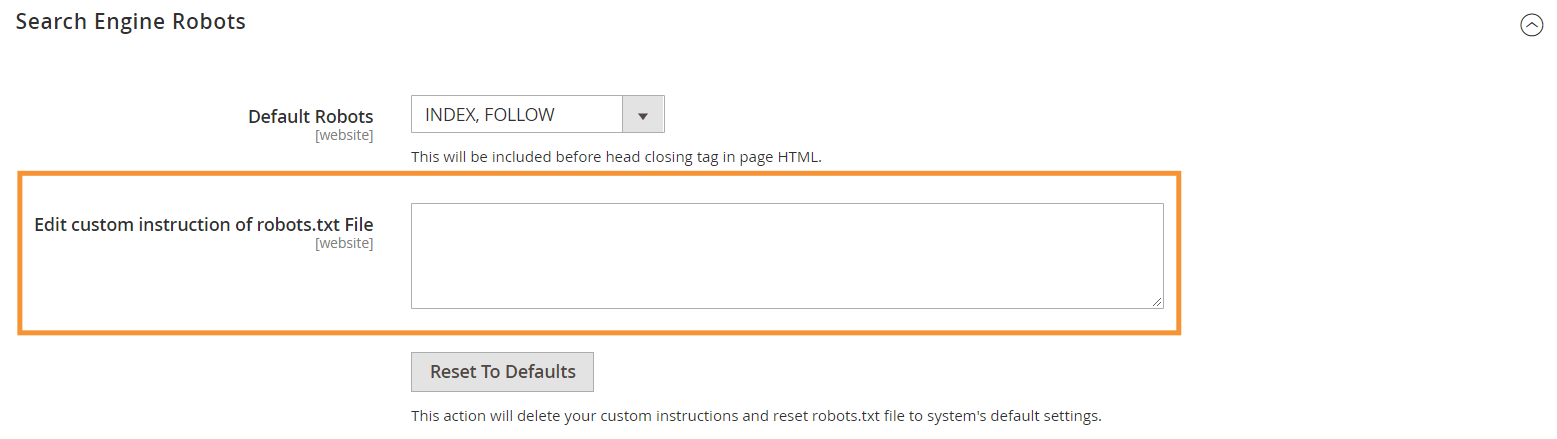
Pasul 3 : în secțiunea Roboti pentru motorul de căutare, editați instrucțiunile personalizate
Instrucțiuni recomandate pentru robots.txt
Iată instrucțiunile noastre recomandate, care ar trebui să se potrivească nevoilor generale. Desigur, fiecare magazin este diferit și ar putea fi necesar să modificați sau să adăugați câteva reguli pentru cele mai bune rezultate.
Agent utilizator: * # Instrucțiuni implicite: Nu permiteți: /lib/ Nu permiteți: /*.php$ Nu permiteți: /pkginfo/ Nu permiteți: /raport/ Nu permiteți: /var/ Nu permiteți: /catalog/ Nu permite: /client/ Nu permiteți: /sendfriend/ Nu permiteți: /review/ Nu permiteți: /*SID= # Nu permiteți fișierele Magento comune în directorul rădăcină: Nu permiteți: /cron.php Nu permiteți: /cron.sh Nu permiteți: /error_log Nu permiteți: /install.php Nu permiteți: /LICENSE.html Nu permiteți: /LICENSE.txt Nu permiteți: /LICENSE_AFL.txt Nu permiteți: /STATUS.txt # Nu permiteți contul de utilizator & Pagini de plată: Nu permiteți: /checkout/ Nu permiteți: /onestepcheckout/ Nu permite: /client/ Nu permiteți: /client/cont/ Nu permiteți: /client/cont/login/ # Nu permiteți paginile de căutare în catalog: Nu permiteți: /catalogsearch/ Nu permiteți: /catalog/product_compare/ Nu permiteți: /catalog/category/view/ Nu permiteți: /catalog/product/view/ # Nu permiteți căutările de filtru URL Disallow: /*?dir* Nu permite: /*?dir=desc Nu permite: /*?dir=asc Nu permite: /*?limit=all Nu permite: /*?mod* # Nu permiteți directoarele CMS: Nu permiteți: /app/ Nu permiteți: /bin/ Nu permiteți: /dev/ Nu permiteți: /lib/ Nu permiteți: /phpserver/ Nu permiteți: /pub/ # Nu permiteți conținut duplicat: Nu permiteți: /tag/ Nu permiteți: /review/ Nu permiteți: /*?*product_list_mode= Nu permiteți: /*?*product_list_order= Nu permiteți: /*?*product_list_limit= Nu permiteți: /*?*product_list_dir= # Setări server # Nu permiteți directoarele tehnice generale și fișierele de pe un server Nu permiteți: /cgi-bin/ Nu permiteți: /cleanup.php Nu permiteți: /apc.php Nu permiteți: /memcache.php Nu permiteți: /phpinfo.php # Nu permiteți folderele de control al versiunilor și altele Nu permiteți: /*.git Nu permite: /*.CVS Nu permiteți: /*.Zip$ Nu permite: /*.Svn$ Nu permite: /*.Idee$ Nu permiteți: /*.Sql$ Nu permite: /*.Tgz$ Harta site-ului: https://www.example.com/sitemap.xml
Concluzie
Crearea unui fișier robots.txt este doar unul dintre mulți pași din lista de verificare Magento SEO - și optimizarea corectă a unui magazin Magento pentru motoarele de căutare nu este o sarcină ușoară pentru majoritatea proprietarilor de magazine. Dacă nu dorești să te ocupi de asta, ne putem ocupa de totul pentru tine. Aici, la SimiCart, oferim servicii SEO și optimizare a vitezei care garantează cele mai bune rezultate pentru magazinul dvs.