
Cum să vă optimizați site-ul web pentru crawlerele motoarelor de căutare?
Publicat: 2023-04-27Crawlerele web trec în mod constant prin site-uri web pentru a determina despre ce este vorba în fiecare pagină. Datele pot fi indexate și modificate și găsite atunci când utilizatorul depune cererea. Unele site-uri web folosesc roboți de crawling pentru a actualiza conținutul site-ului lor.
Motoarele de căutare precum Google sau Bing utilizează un motor de căutare împreună cu colectarea de informații de către crawlerele web pentru a afișa site-uri web relevante și informații relevante ca rezultat al căutărilor utilizatorilor.
Dacă un web design Compania sau proprietarul site-ului dorește să vadă site-ul lor să apară în rezultatele căutării, acesta trebuie accesat cu crawlere și indexat. Dacă site-urile nu sunt accesate cu crawlere sau indexate, atunci motoarele de căutare nu le vor putea localiza organic.
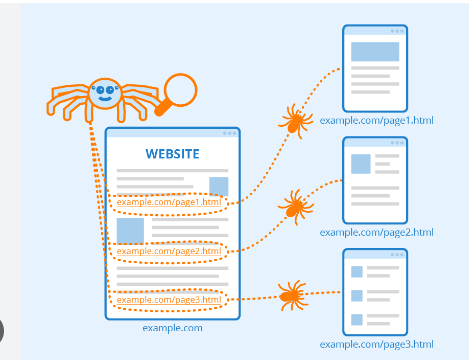
Crawlerele web încep prin a accesa cu crawlere anumite pagini și apoi urmând hyperlinkuri de pe pagini către altele noi.
Site-urile web care nu doresc să fie accesate cu crawlere sau descoperite de motoarele de căutare pot folosi instrumente precum cele găsite în fișierul robots.txt pentru a instrui roboții să nu indexeze un site web sau să indexeze doar o mică parte din acesta.
Efectuarea inspecțiilor site-ului cu instrumente de accesare cu crawlere poate ajuta proprietarii de site-uri web să identifice hyperlinkuri sparte sau conținut duplicat. Titluri care lipsesc sau sunt prea lungi sau scurte față de un titlu.
Cuprins
Rolul motoarelor de căutare în crawling-ul web:
1. Crunching: Căutați informații pe Internet și apoi codul sursă/conținutul pentru fiecare URL pe care o întâlnesc.
2. Indexare: Gestionați și stocați informațiile adunate în procesul de crawling. După ce o pagină este inclusă în index, care o arată ca rezultat al căutărilor pertinente poate fi un proces continuu.
3. Clasament: Prezentați porțiunile de informații cele mai susceptibile de a satisface cerințele utilizatorului.
Ce este exact crawling-ul în Google?
Crawling-ul este metoda de a găsi pe care motoarele de căutare o folosesc pentru a distribui un set de roboți (păianjeni și crawler) pentru a găsi conținut proaspăt și actualizat.
Conținutul poate fi în diferite formate, cum ar fi imagini, pagini web sau videoclipuri, PDF-uri etc. Indiferent de tipul de format, conținutul se găsește prin hyperlink-uri.
Googlebot începe prin a căuta anumite site-uri web; după aceea, scanează hyperlinkurile paginilor pentru a găsi URL-uri noi.
În timp ce parcurge hyperlinkurile, crawler-ul poate descoperi conținut nou pe care îl poate include în indexul său numit Coffeine.
Este o bază de date masivă de adrese URL descoperite recent, care poate fi preluată atunci când cineva caută informații pe un site al cărui conținut URL se potrivește perfect.
Clasamentul motoarelor de căutare:
Când cineva efectuează o căutare pe Google, motoarele de căutare își scanează indexurile pentru a găsi conținut pertinent și apoi aranjează conținutul pentru a rezolva întrebarea.
Ordinea în care rezultatele căutării sunt aranjate în funcție de relevanță este cunoscută sub denumirea de clasare.
Puteți bloca crawlerele motoarelor de căutare să nu acceseze cu crawlere o anumită parte sau chiar tot site-ul dvs. sau puteți instrui motoarele de căutare să nu includă anumite site-uri web în indexul lor.
Dacă doriți să vedeți site-ul dvs. web indexat prin rezultatele motoarelor de căutare, ar trebui să vă asigurați că este accesibil crawlerelor și indexabil.
Motoarele de căutare cu crawlere:
După cum ați văzut, este vital să vă asigurați că site-ul dvs. este accesat cu crawlere, indexat și accesat cu crawlere pentru ca acesta să apară în rezultatele căutării. Dacă compania dvs site-ul se află în indexul site-ului pe care îl căutați, este o idee grozavă să începeți prin a vă uita la numărul de pagini din rezultatele căutării.

Acest lucru vă poate oferi o perspectivă excelentă asupra modului în care Google a accesat cu crawlere site-ul dvs. web pentru a găsi fiecare pagină către care doriți să faceți linkuri, dar să nu descoperiți paginile pe care nu le aveți.
Rezultate: numărul de rezultate afișate de Google nu este exact. Cu toate acestea, vă oferă o înțelegere a paginilor găsite pe site-ul dvs. și a modului în care acestea sunt afișate în paginile cu rezultatele căutării.
Instrumentul permite tendințelor de design web să încarce sitemap-uri pe site-ul dvs. și să urmărească numărul de pagini trimise pentru a fi adăugate la indexul Google și alte aspecte.
Dacă site-ul dvs. nu apare pe pagina Rezultate, există multe motive pentru care să vă uitați:
- Site-ul dvs. este nou și încă urmează să fie accesat cu crawlere.
- Navigarea site-ului dvs. îngreunează navigarea eficientă pentru crawlere.
- Site-ul dvs. are un cod elementar numit directive crawler care blochează instrucțiunile crawler-ului de la motoarele de căutare.
- Site-ul dvs. a fost eliminat din listă de Google deoarece folosea metode de spam.
Informați motoarele de căutare cum pot accesa site-ul dvs .:
Dacă ați încercat Google Search Console sau motorul de căutare avansat „site: domain.com” și ați descoperit că unele dintre paginile dvs. importante nu sunt listate în index sau că anumite pagini care nu sunt la fel de importante nu au fost indexate corect , atunci există câteva modalități de a gestiona Googlebot în modul în care ați dori ca conținutul site-ului dvs. web să fie accesat cu crawlere.
Mulți se concentrează pe a se asigura că Google își va găsi cele mai importante site-uri web, dar este ușor să treceți cu vederea ceea ce este cel mai probabil să fie câteva pagini pe care doriți să evitați să le găsească Googlebot.
Acestea pot fi adrese URL mai vechi, fără informații și numeroase adrese URL (cum ar fi filtre și parametri de sortare pentru comerțul electronic), coduri promoționale, pagini de punere în scenă sau de testare și multe altele.
Concluzie:
Google face o treabă excelentă de a determina adresa URL corectă pentru site-ul dvs. web.
Cu toate acestea, puteți utiliza și această funcție în interiorul Search Console pentru a spune Google exact cum ați prefera ca acestea să gestioneze site-urile dvs. web.
Dacă utilizați această funcție pentru a spune Googlebot „explorați cu crawlere pentru a găsi adrese URL care nu conțin parametrul ____”, acesta încearcă să convingă Google să păstreze aceste informații departe de Googlebot și, astfel, să elimine aceste pagini din rezultatele căutării.
Acesta este ceea ce cauți atunci când acești parametri duc la pagini duplicate. Există, totuși, alternative mai bune la aceasta dacă doriți ca aceste pagini să fie incluse.
Întrebări frecvente:
Considerați că conținutul site-ului dvs. web dispare atunci când utilizați formularul de autentificare?
Motoarele de căutare nu vor putea accesa paginile protejate atunci când solicitați utilizatorilor să se înscrie și să completeze formulare sau chestionare înainte de a accesa anumite site-uri web. Un crawler este obligat să necesite asistență pentru autentificare.
Ar trebui să folosiți pagina de căutare Google?
Formularele de căutare nu sunt accesibile roboților. Unii oameni cred că dacă includ opțiuni de căutare pe site-ul lor, motoarele de căutare pot găsi ceea ce caută utilizatorii.
Pot motoarele de căutare să urmeze direcția site-ului dvs.?
Un crawler trebuie să găsească site-ul dvs. prin hyperlinkuri către alte site-uri web și să solicite o listă de link-uri care direcționează utilizatorul de la o pagină la alta. Dacă aveți o pagină pe care ați dori ca motoarele de căutare să o găsească, dar nu este conectată la o altă pagină, este mult mai eficient decât să nu fiți observat.