
Profitați la maximum de Apache Solr: O explorare tehnică a indexării căutărilor
Publicat: 2023-02-21O funcție de căutare îmbunătățește experiența utilizatorului a unui site web, permițându-i utilizatorului să găsească ceea ce caută ușor și rapid. Mai mult pentru site-uri web mari, site-uri de comerț electronic și site-uri cu conținut dinamic (site-uri de știri, bloguri).
Apache Solr este una dintre cele mai populare platforme de căutare utilizate de site-uri web de toate dimensiunile. Este un motor de căutare open-source bazat pe Java, care vă permite să căutați prin cantități mari de date, cum ar fi articole, produse, recenzii ale clienților și multe altele. Aruncă o privire mai profundă asupra Apache Solr în acest articol.
Consultați acest articol pentru a afla cum să configurați Apache Solr în Drupal

De ce este Apache Solr atât de popular?
Apache Solr este rapid și flexibil și permite căutarea textului integral, evidențierea hit-ului (evidențiază termenul de căutare potrivit), căutarea fațete (o căutare mai rafinată), indexarea în timp real (permite indexarea imediată a noului conținut), gruparea dinamică ( organizează rezultatele căutării în grupuri), integrarea bazelor de date, caracteristici NoSQL (bază de date non-relațională) și gestionarea bogată a documentelor (pentru a indexa o mare varietate de formate de documente, cum ar fi PDF, MS Office, Open office).
Câteva fapte bune de știut despre Apache Solr:
- A fost dezvoltat inițial de CNET networks, inc. ca motor de căutare pentru site-urile și articolele lor. Mai târziu, a fost open-source și a devenit un proiect Apache de nivel superior.
- Suportă mai multe limbaje de programare precum PHP, Java, Python și Ruby. De asemenea, oferă API-uri pentru aceste limbi.
- Are suport încorporat pentru căutarea geospațială, permițând căutarea conținutului în funcție de locația sa. Util în special pentru site-uri precum site-uri imobiliare, site-uri de călătorie etc.
- Acceptă funcții avansate de căutare, cum ar fi verificarea ortografică, completarea automată și căutarea personalizată prin API-uri și pluginuri.
- Utilizează Lucene pentru indexare și căutare.
Ce este Lucene
Apache Lucene este o bibliotecă de căutare Java cu sursă deschisă care vă permite să adăugați cu ușurință căutarea sau recuperarea informațiilor în aplicație. Este versatil, puternic, precis și funcționează pe un algoritm de căutare eficient.
Deși este cunoscut pentru capabilitățile sale de căutare full-text, Lucene poate fi folosit și pentru clasificarea documentelor, analiza datelor și regăsirea informațiilor. De asemenea, acceptă multe alte limbi decât engleza, cum ar fi germană, franceză, spaniolă, chineză, japoneză și multe altele.
Ce este indexarea?
Toate motoarele de căutare încep cu indexarea. Indexarea este procesarea datelor originale într-o căutare încrucișată extrem de eficientă pentru a facilita căutarea rapidă.
Motoarele de căutare nu indexează datele direct. Textele sunt mai întâi împărțite în jetoane (elemente atomice). Căutarea este procesul de consultare a indexului de căutare și de preluare a documentului care se potrivește interogării.
Avantajele indexării
- Preluare rapidă și precisă a informațiilor (colectează, analizează și stochează)
- Fără indexare, motorul de căutare necesită mai mult timp pentru a scana fiecare document
Flux de indexare
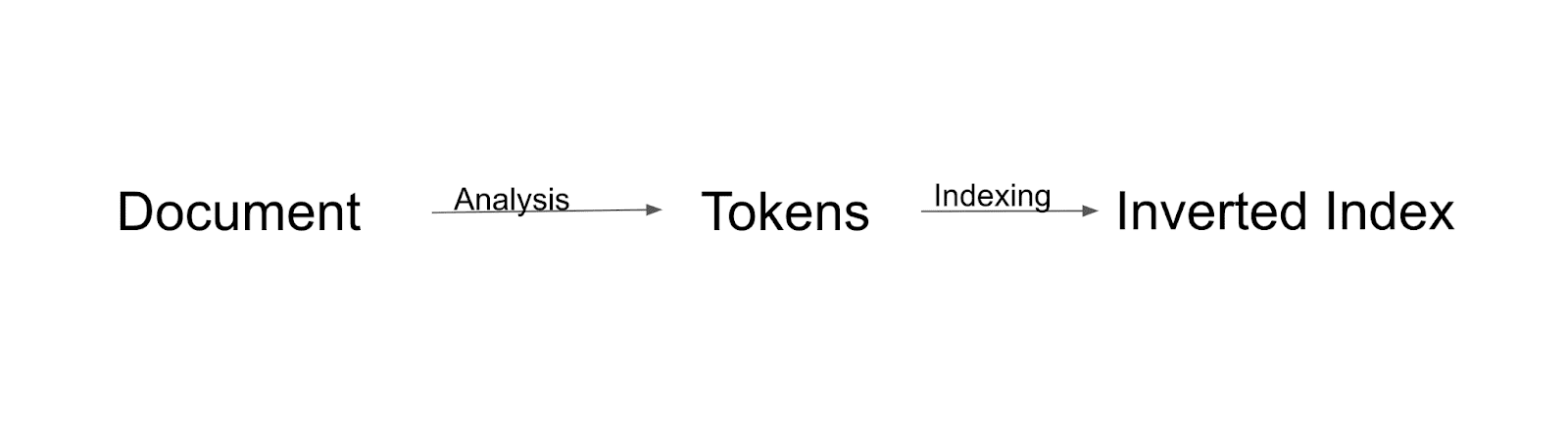
În primul rând, documentul va fi analizat și împărțit în jetoane. Toate acele jetoane vor fi indexate la indexul inversat. Indexul inversat este o modalitate prin care Solr construiește indicele.
Cum funcționează indexarea inversată
Să considerăm că avem 3 documente:
- Iubesc ciocolata (D 1)
- Am comandat tort de ciocolata (D 2)
- Am pregatit prajitura mare de vanilie (D 3)
Modul în care este tokenizat este așa cum se arată în a doua coloană a tabelului de mai jos.

„Ciocolata” este disponibilă în D1 și D2
„Cake” este disponibil în D2 și D3
„Big” este disponibil în D3
„Comandat” este disponibil în D2
„Pregătit” este disponibil în D3
„Vanilla” este disponibil în D3
Veți observa că cuvinte precum „eu”, „dragoste” nu sunt simbolizate. Acestea se numesc cuvinte stop care nu vor fi indexate sau căutate de Solr.
Deci, atunci când cineva caută termenul „Prăjitură de ciocolată”, motorul se uită în index. În loc să caute documentul, se uită mai întâi în index pentru a vedea în ce documente se încadrează cuvintele „Ciocolată” și „Prăjitură”. Acest lucru face mai ușor și mai rapid preluarea doar a unui anumit document. Aceasta se numește indexare inversată.
Schema de stocare
Apache Solr utilizează o schemă de stocare bazată pe documente și stochează fiecare bucată de date ca document separat într-o colecție. Acest lucru permite stocarea și recuperarea eficientă și flexibilă a datelor.
În Drupal, fiecare nod este considerat ca un document. Deci, atunci când vă indexați nodul la Apache Solr, acesta este considerat un document. Fiecare document poate conține mai multe câmpuri. Lucene nu are o schemă globală comună. Ceea ce înseamnă că puteți indexa orice tip de câmp din fiecare document în Apache Solr.

Cum se instalează Apache Solr
- În primul rând, asigurați-vă că aveți Java instalat pe sistemul dvs.
- Apoi, să instalăm Solr de aici: https://solr.apache.org/downloads.html
- Descărcați și extrageți Solr.
- Rulați această comandă în folderul Solr.
◦ bin/solr -e techproducts
Acest lucru va crea un nucleu inactiv pentru demonstrație și va porni și serverul Solr.
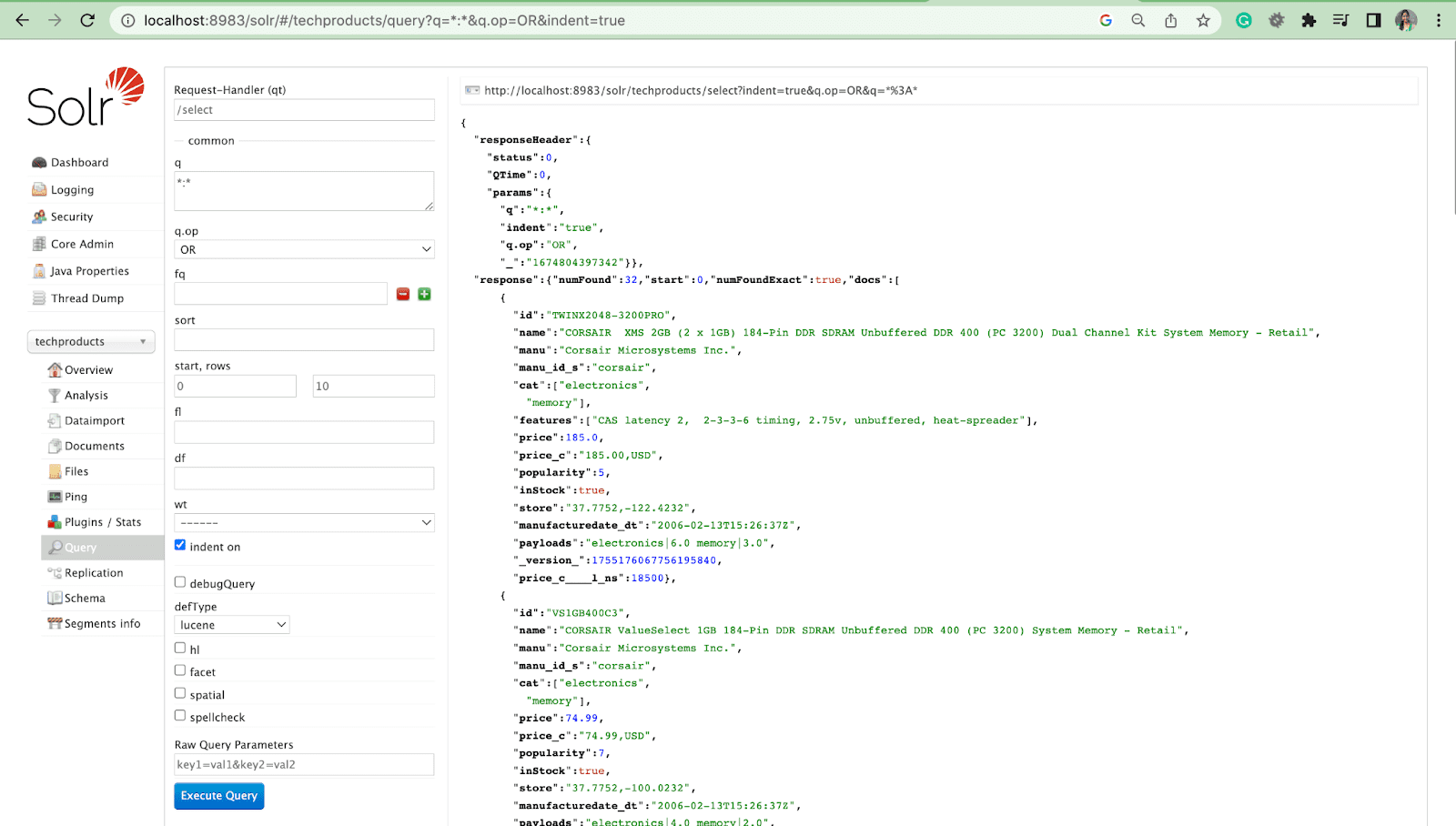
- Odată ce serverul a pornit, accesați browserul și tastați „http://localhost:8983/”.
- Asigurați-vă că Solr este instalat cu succes cu miez fals.
Structura directorului
După ce ați instalat Solr, veți vedea multe foldere precum:
Docs - conține documentație despre Solr
Dist - fișierul principal .jar Solr
Contrib - conține pluginuri suplimentare și funcții specializate ale Solr
Bin - scripturi de Solr
Exemplu - conține demonstrarea capacităților solr
Server - inima lui Solr. Conține aplicația web Solr, jurnalele, nucleul Solr

Fișiere de configurare
Pentru a crea un nucleu, avem nevoie de două fișiere obligatorii.
- Schema.xml
- Solrconfig.xml
Schema.xml
- Acesta va conține tipurile de câmpuri pe care intenționați să le susțineți și modul în care aceste tipuri ar trebui analizate.
Solrconfig.xml
- Conține diverse setări care controlează comportamentul unui nucleu Solr, cum ar fi handler de solicitări, dispecer de solicitări, componente de interogare, handlere de actualizare etc.
Interogarea în Solr
Acum să vedem cum să interogăm rezultatele Solr în interfața de utilizare a administratorului Solr.
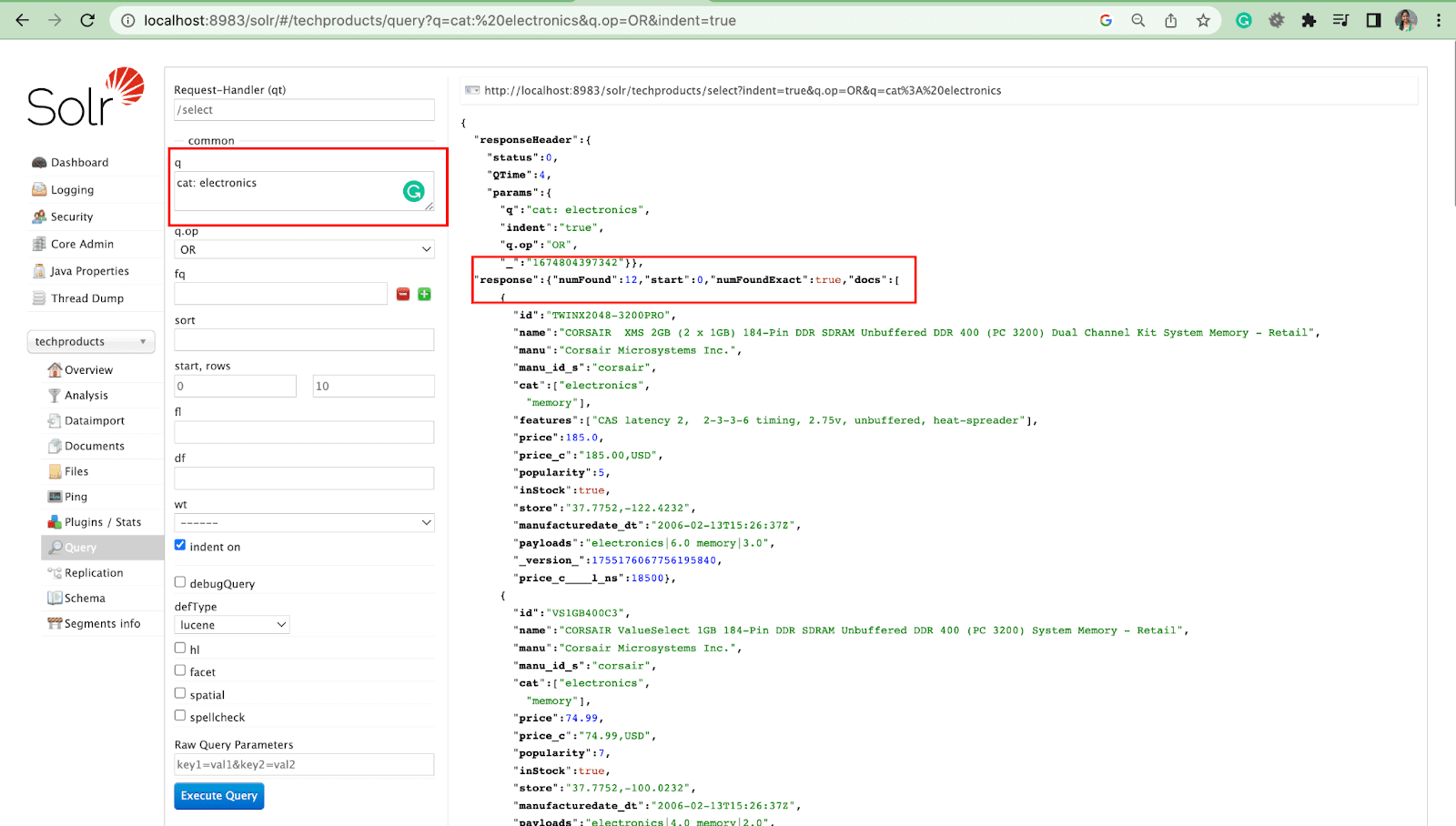
Parametru de interogare
- Parametrii locali sunt argumente dintr-o cerere Solr care sunt specifice unui parametru de interogare.
De exemplu: pisica: electronice
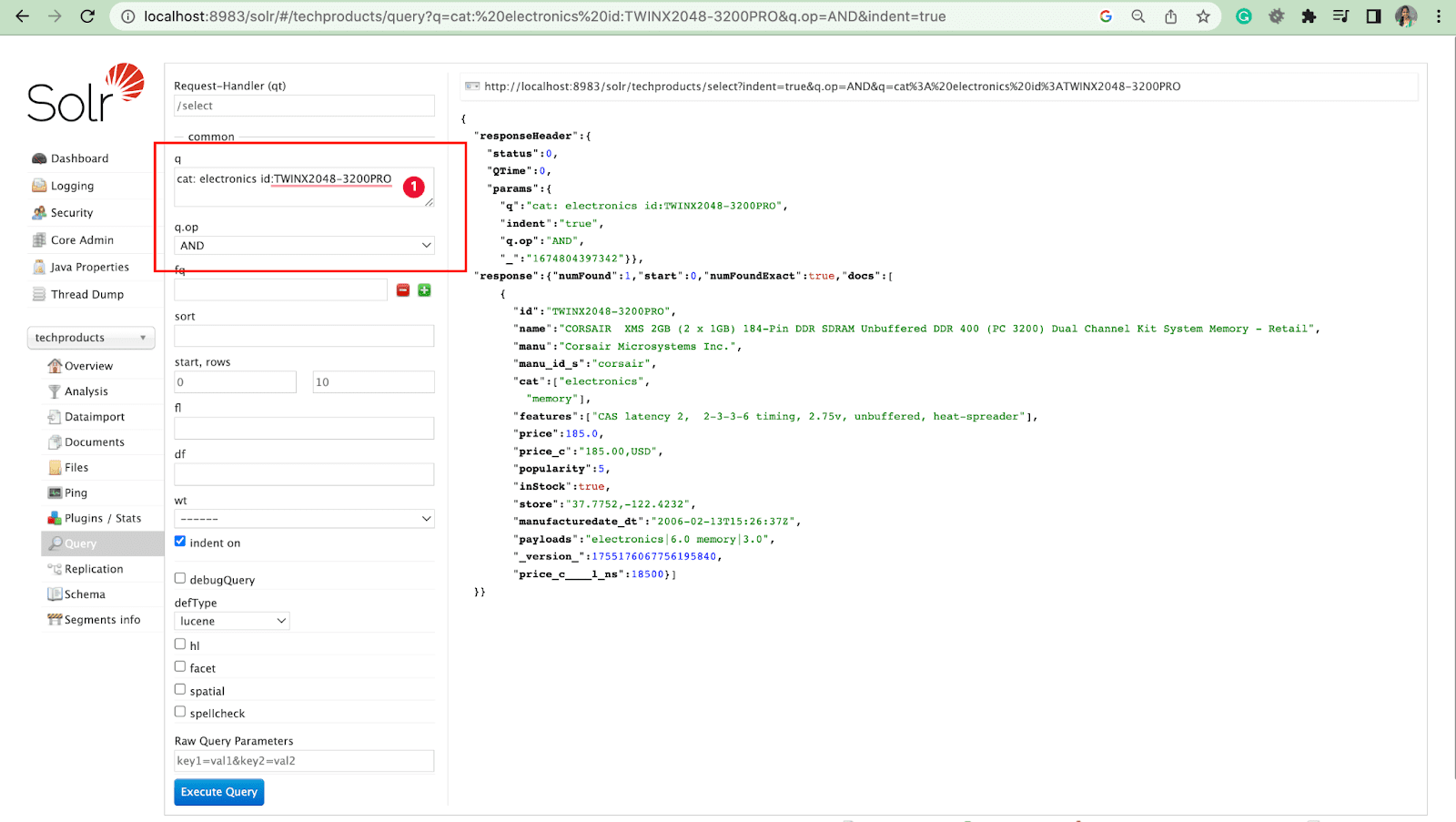
Parametru de interogare cu operații
- Putem interoga mai multe câmpuri cu operație.
De exemplu: cat: electronics id:TWINX2048-3200PRO cu q.op AND
[SAU]
cat: electronica SI id:TWINX2048-3200PRO
[SAU]
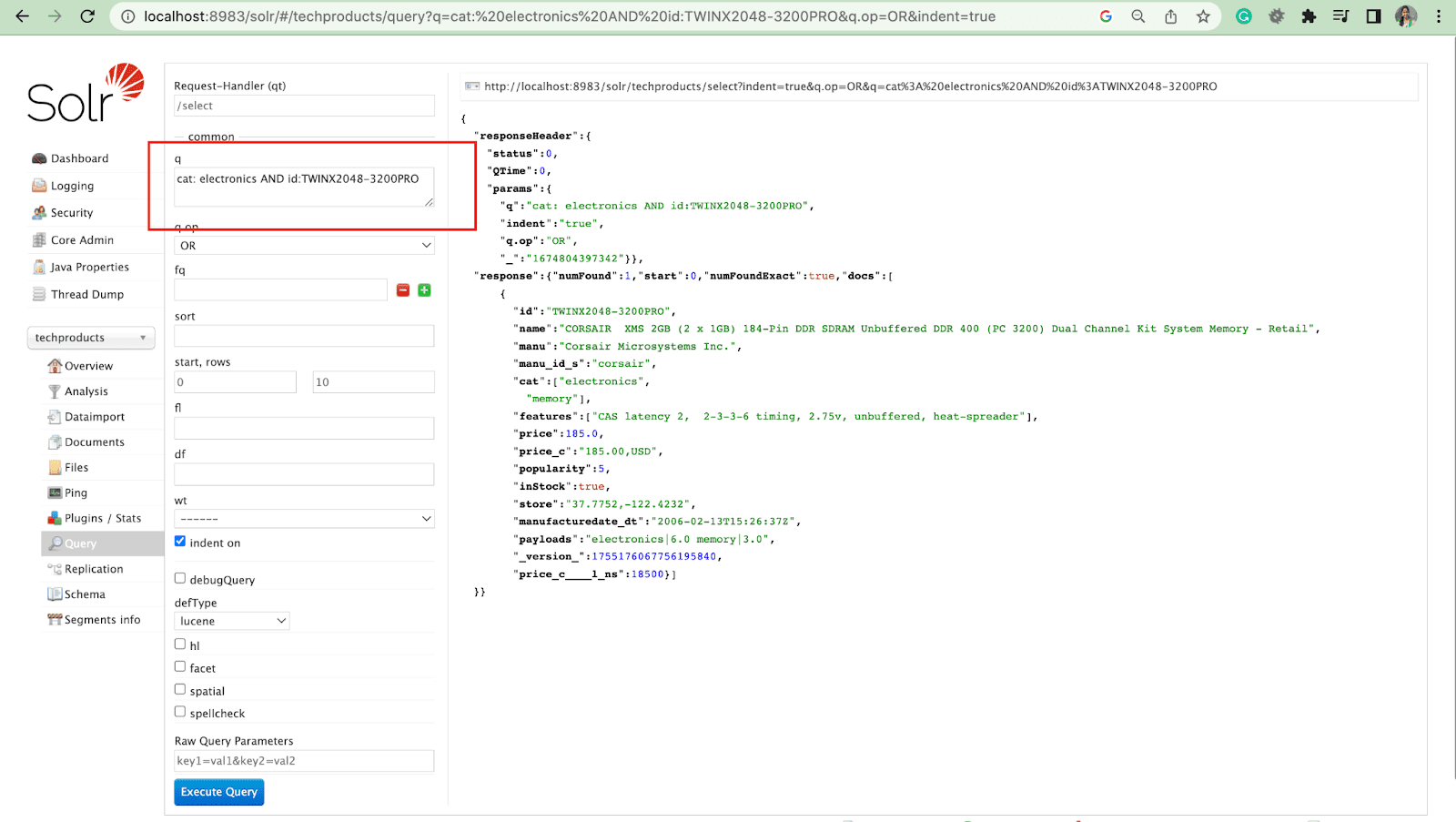
Interogare de filtrare
O interogare de filtru ajută la restrângerea rezultatelor unei căutări. O interogare poate fi specificată de parametrul fq pentru a restricționa ce documente sunt returnate în superset, fără a afecta scorul.
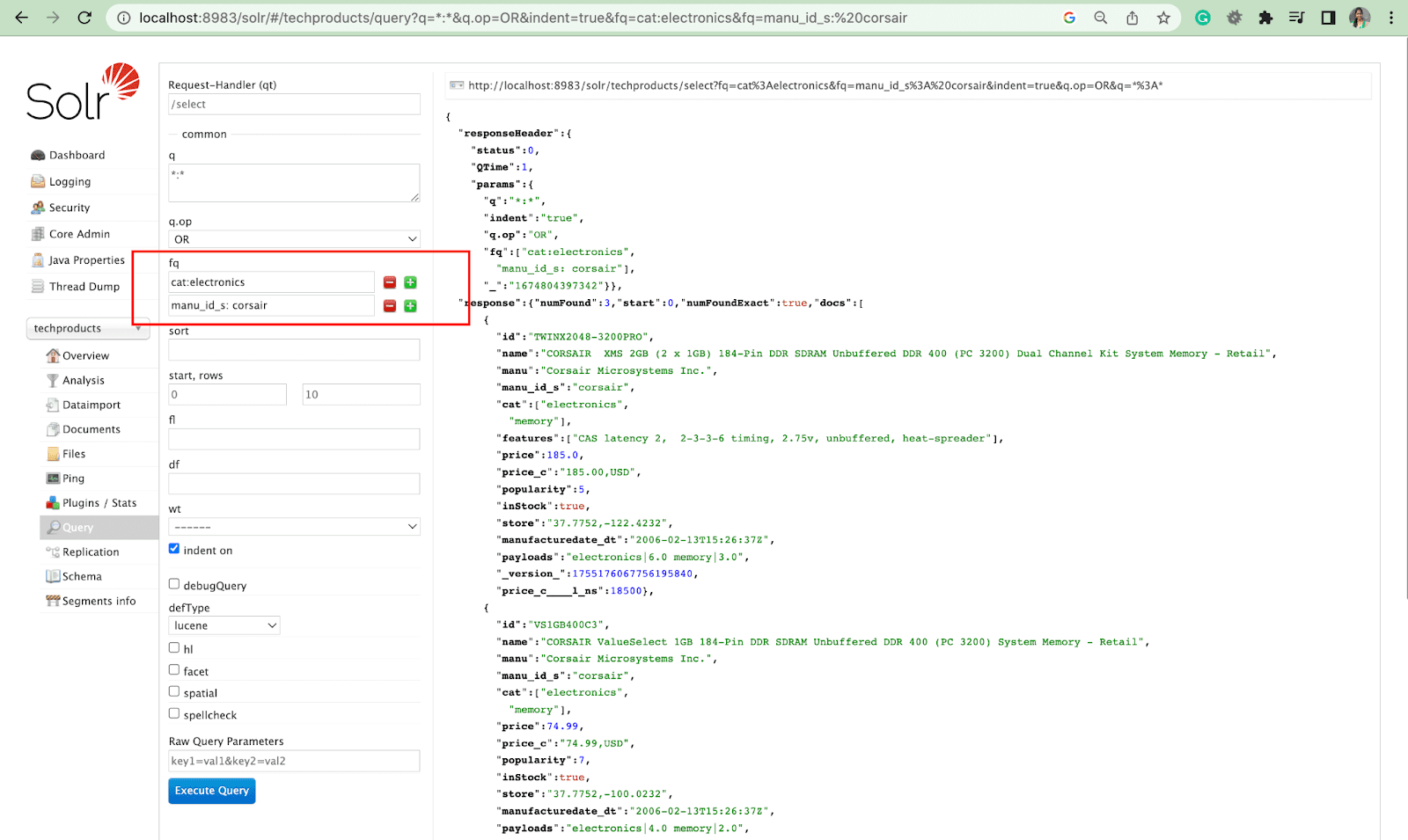
Parametrul de sortare
Parametrul de sortare aranjează rezultatele căutării fie în ordine crescătoare (asc) fie descrescătoare (desc). În funcție de conținut, parametrul poate fi utilizat fie numeric, fie alfabetic.
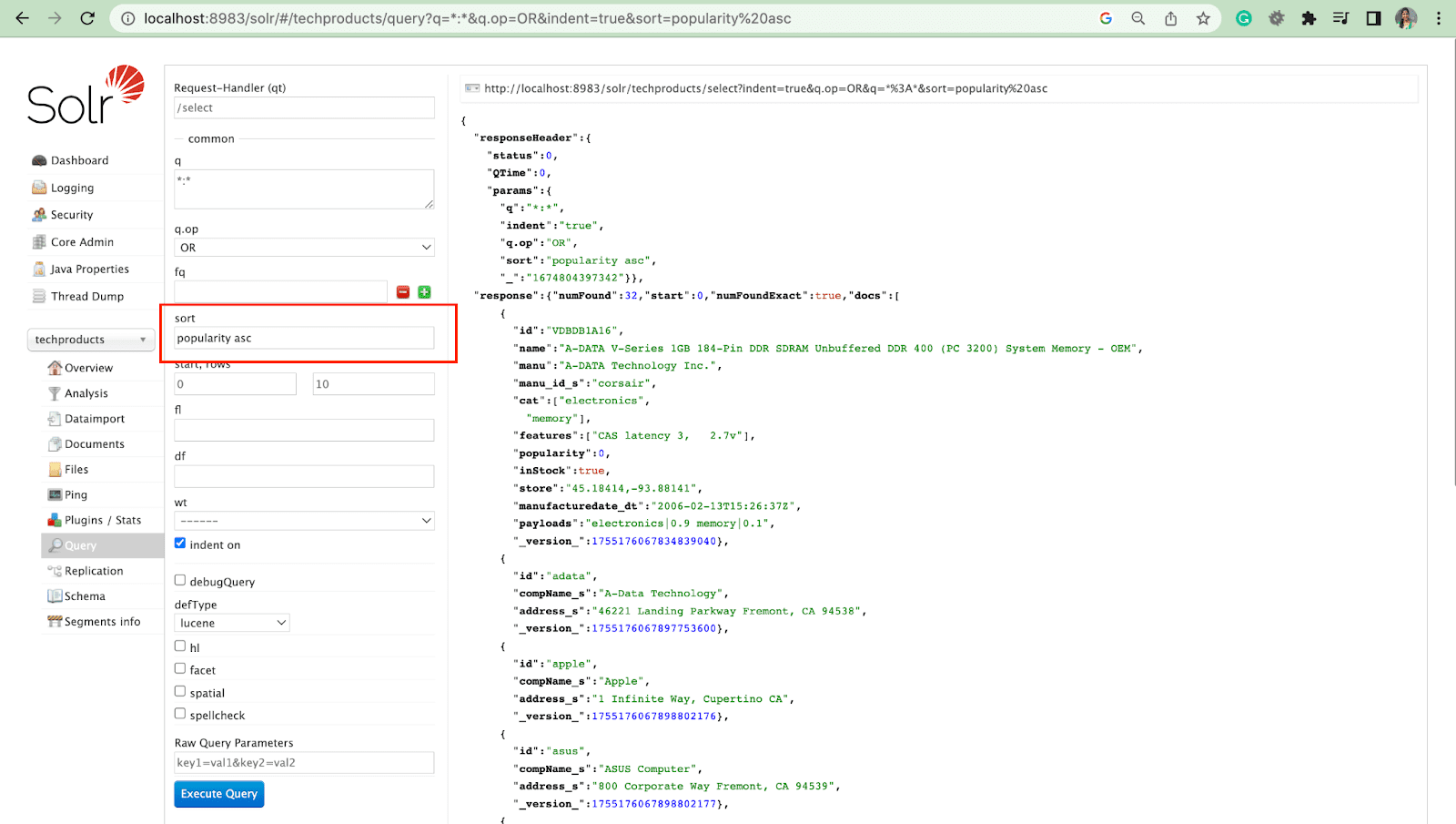
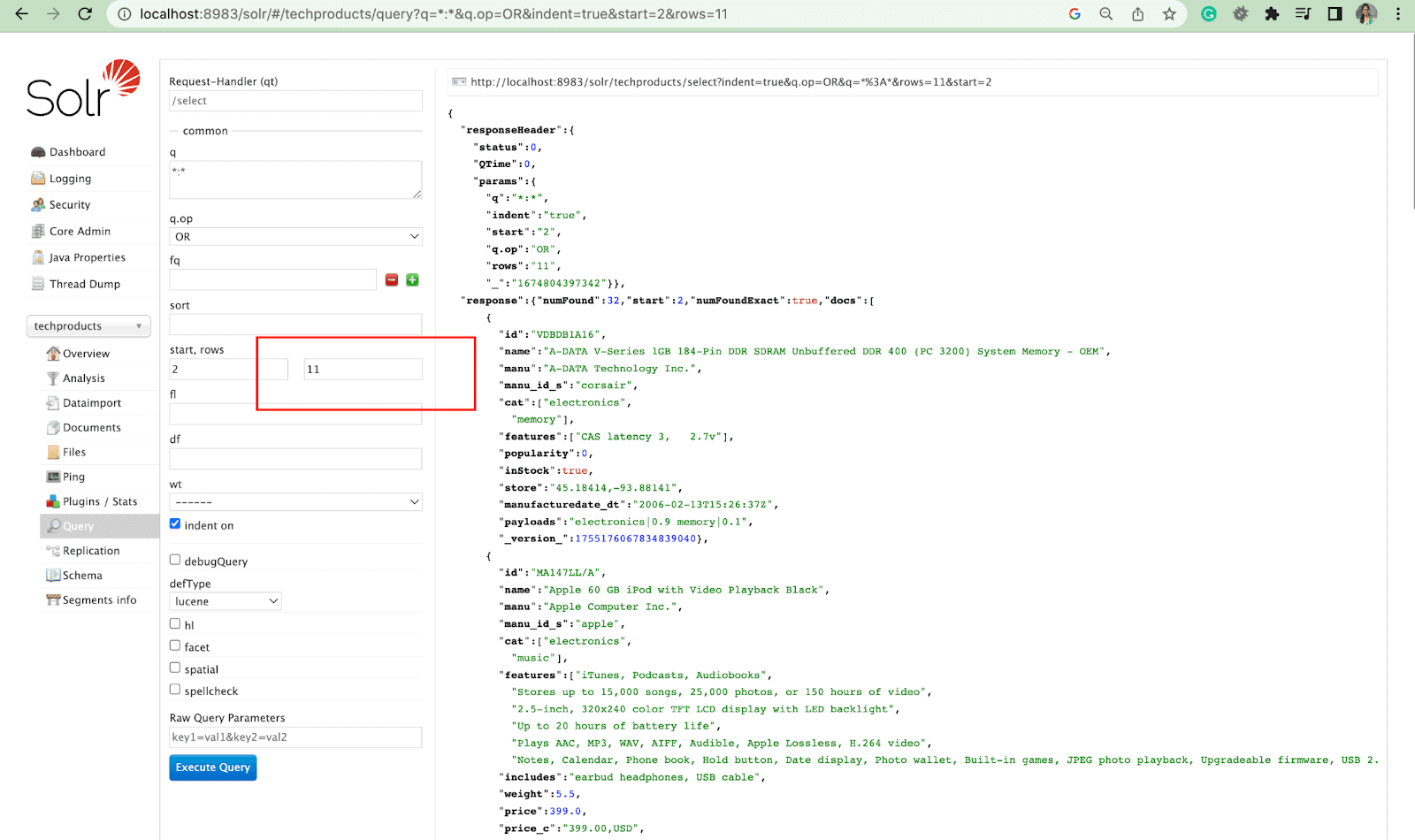
Parametru de rânduri
Parametrul rows vă permite să paginați rezultatele dintr-o interogare.
Parametru Listă de câmpuri
Parametrul fl limitează informațiile incluse într-un răspuns la o interogare la o listă specificată de câmpuri.
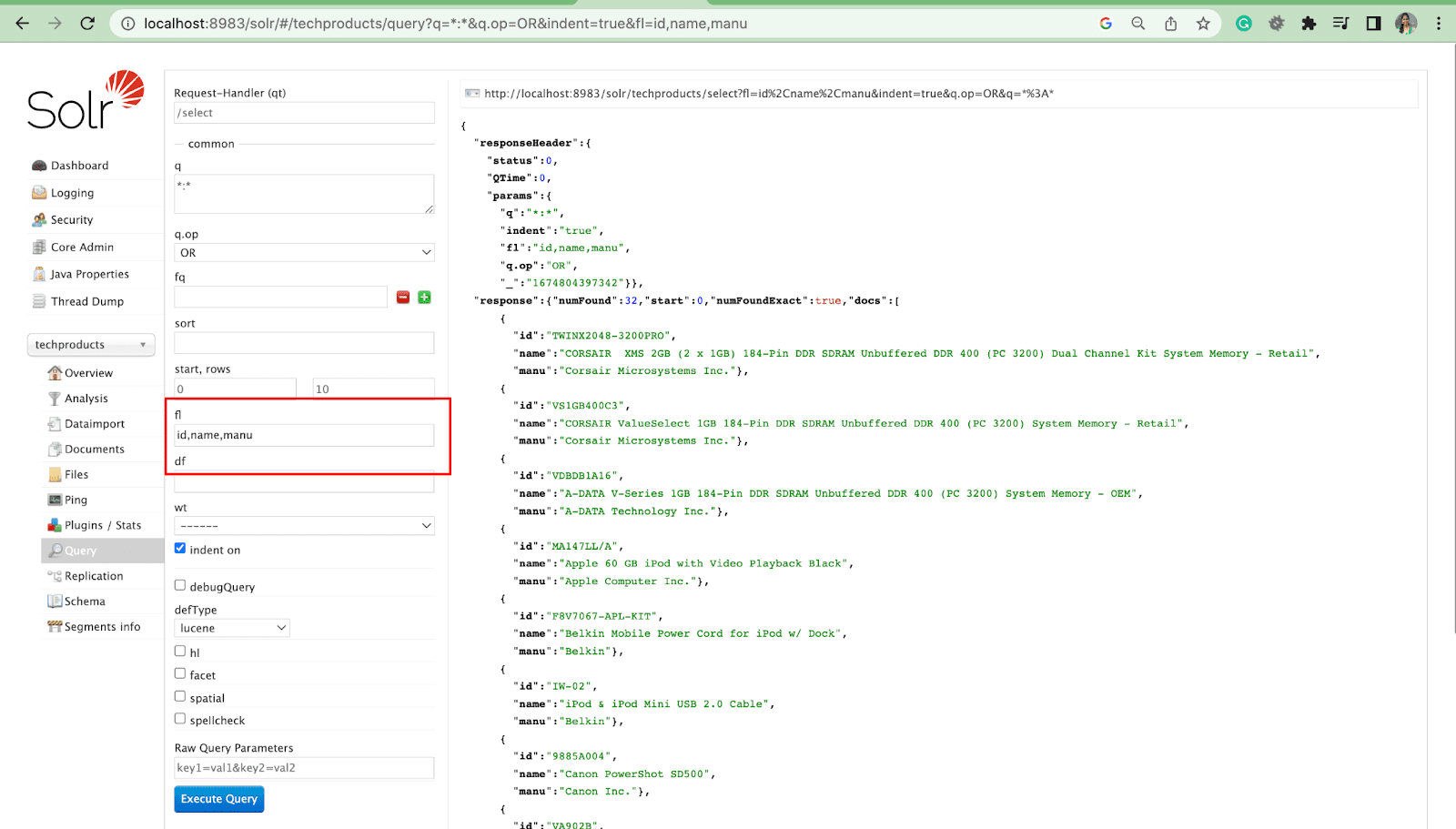
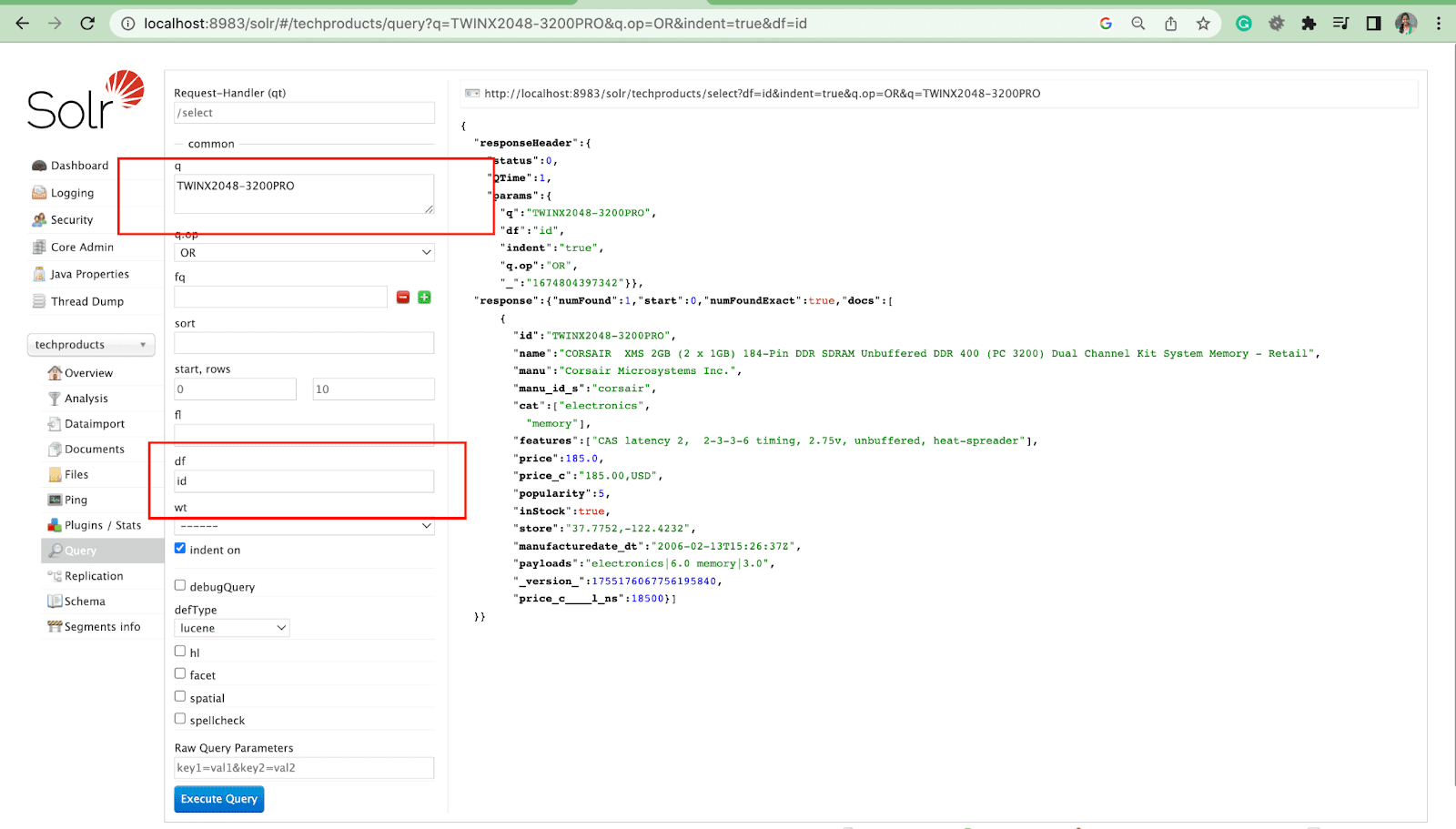
Câmp implicit Parametru
Parametrul de câmp implicit este câmpul implicit pentru parametrul de interogare.
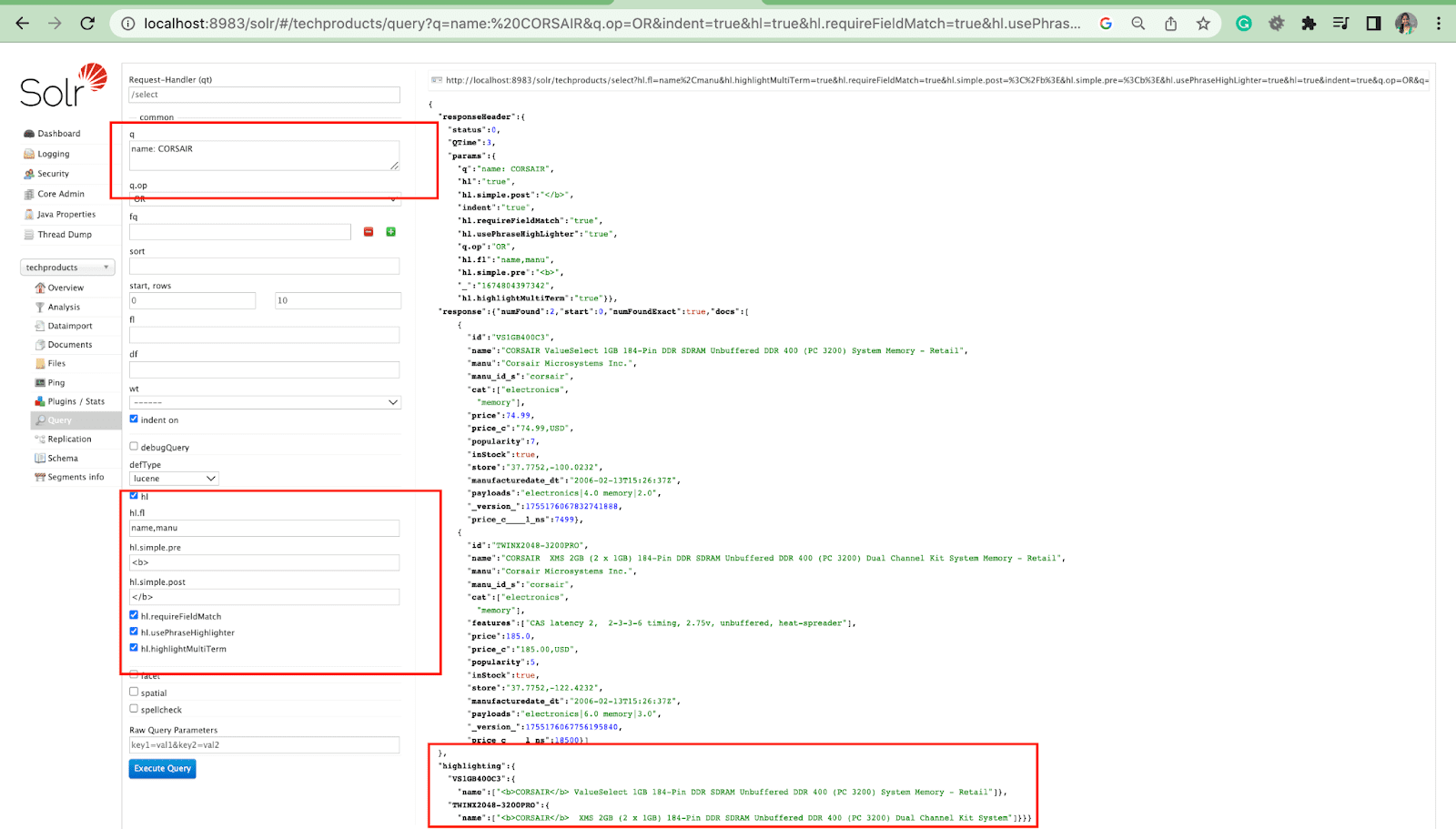
Parametrul evidențiază
Caracteristica de evidențiere din Solr permite includerea de fragmente de documente care se potrivesc cu o interogare.
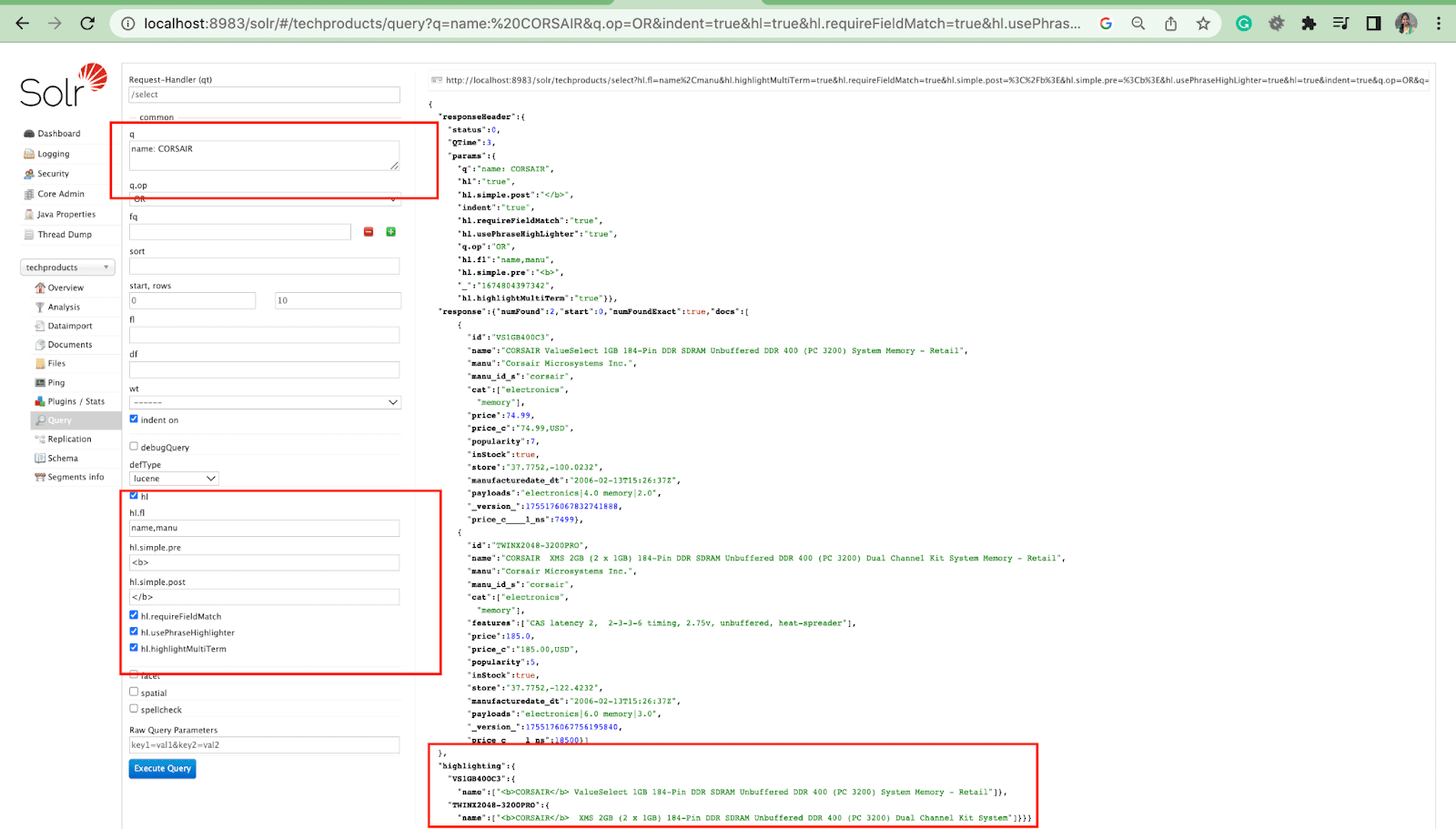
Unii dintre cei mai comuni parametri de evidențiere sunt:
- Hl.fl - Evidențiază o listă de câmpuri.
- Hl.simple.pre - Specifică ce „etichetă” trebuie utilizată înaintea unui cuvânt evidențiat.
- Hl.simple.post - Specifică ce „etichetă” trebuie utilizată după un termen evidențiat.
- hl.highlightMultiTerm - Dacă este setat la true , Solr va evidenția interogările wildcard. Dacă sunt false , nu vor fi evidențiate deloc.
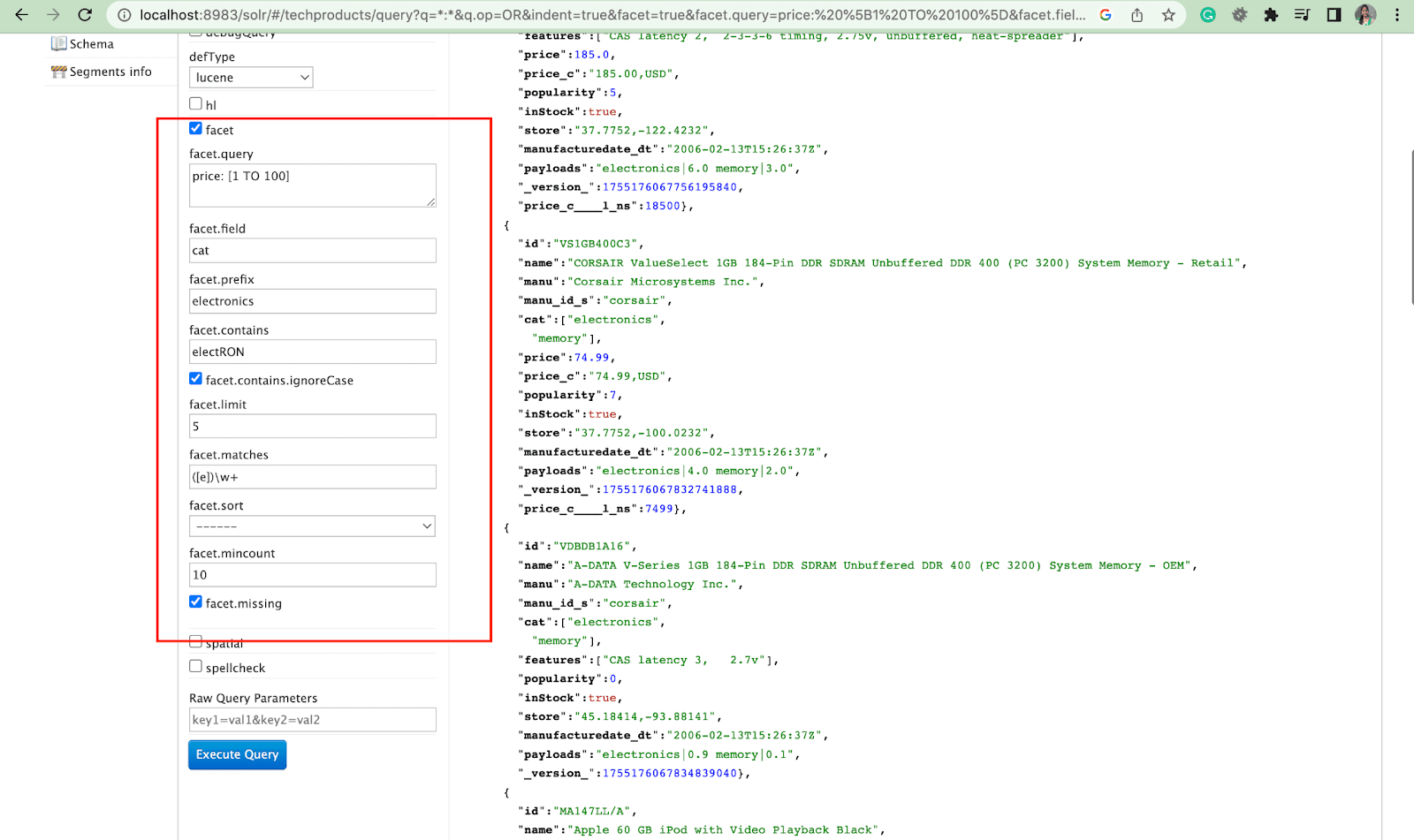
Faţetă:
Fațetele le permit utilizatorilor să exploreze și să rafineze seturi mari de rezultate ale căutării. Sunt afișate într-o interfață de utilizare ca casete de selectare, meniuri derulante sau alte comenzi. Cei doi parametri generali pentru controlul fațetelor sunt:
- Parametru de fațetă
Folosind parametrul fațetă, utilizatorii pot genera fațete pe baza valorilor unuia sau mai multor câmpuri din indexul lor de căutare. În rezultatele căutării, parametrul fațete poate fi configurat pentru a controla modul în care sunt generate și afișate fațetele.
2. Parametru fațetă.interogare
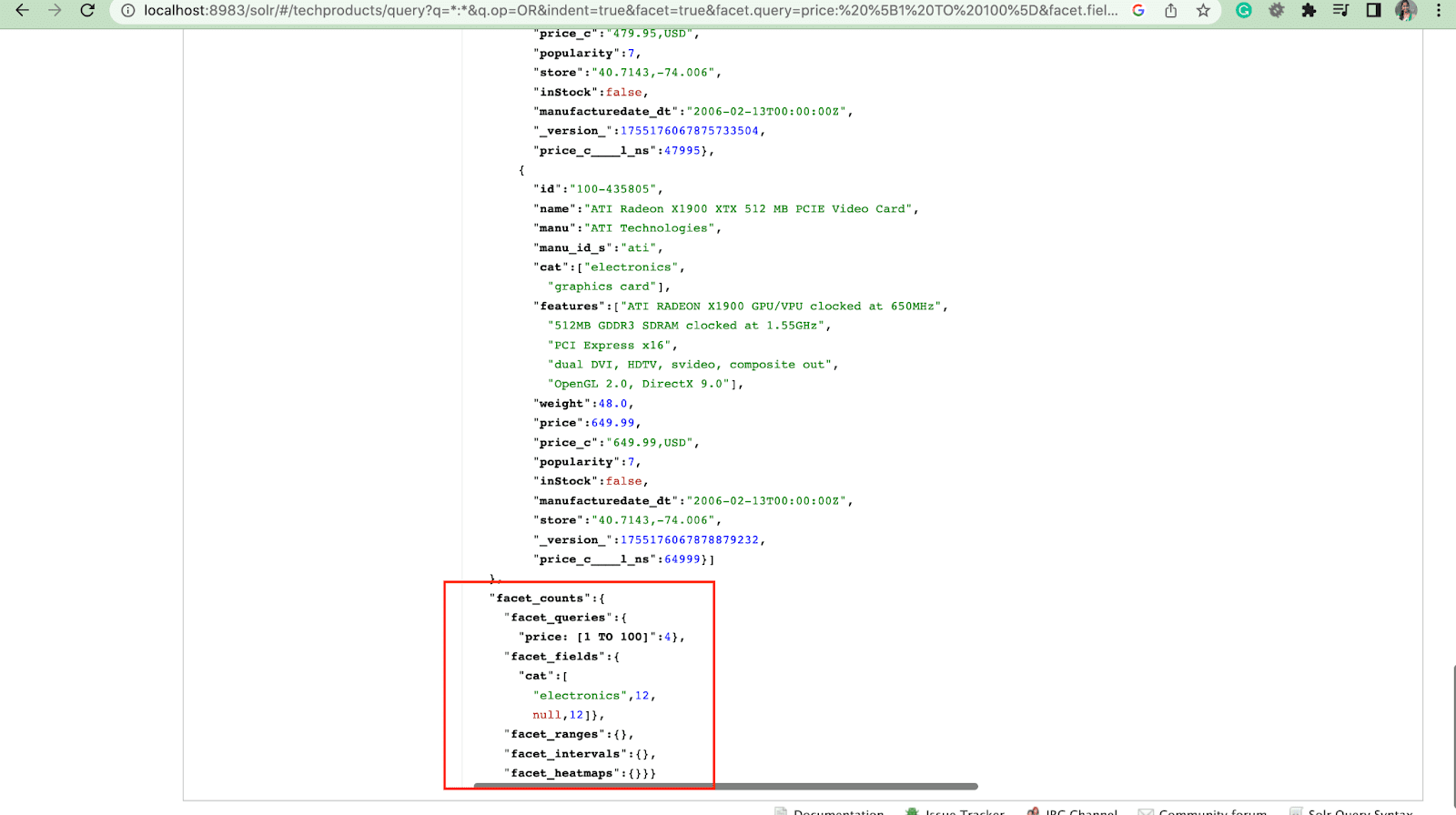
Când un utilizator include un parametru facet.query în interogarea sa Solr, Solr va genera o listă de numere de fațete care corespund numărului de documente din index care se potrivesc cu fiecare interogare. Facet.query este util atunci când doriți să generați fațete pe baza unor criterii de căutare complexe care nu pot fi reprezentate cu ușurință folosind o valoare de câmp simplă.
Există câțiva alți parametri de fațetă, cum ar fi facet.field (pentru a specifica câmpurile care ar trebui utilizate pentru a genera fațete) , facet.limit (numărul maxim de fațete de afișat pentru fiecare câmp) , facet.mincount (numărul minim de document necesar pentru fațeta care urmează să fie inclusă în răspuns) , facet.sort (specifică ordinea în care ar trebui să se afișeze valorile fațetei) .
Gânduri finale
Apache Solr este un motor de căutare extrem de versatil, care vine cu multe caracteristici interesante care pot fi personalizate în funcție de cerințele dumneavoastră. Drupal funcționează extrem de bine cu Apache Solr. Dacă sunteți în căutarea experților Drupal pentru a configura un motor de căutare puternic pentru noul dvs. proiect, ne-ar plăcea să-l ducem mai departe!