
Como configurar o arquivo robots.txt do Magento 2 para SEO
Publicados: 2021-01-21Índice
SEO é um fator importante para o sucesso de sua loja, e um robots.txt configurado corretamente contribui em grande parte para facilitar o trabalho dos rastreadores de mecanismos de pesquisa.
O que é robots.txt?
Em poucas palavras, o robots.txt é um arquivo que instrui os rastreadores de mecanismos de pesquisa sobre o que eles podem ou não rastrear. Sem um robots.txt em seu diretório raiz, os rastreadores de mecanismos de pesquisa que chegam à sua loja rastrearão tudo o que puderem, e isso inclui páginas duplicadas ou sem importância nas quais você não deseja que os rastreadores de mecanismos de pesquisa desperdicem seu orçamento de rastreamento. Um robots.txt deve ser capaz de resolver isso.
Observação : o arquivo robots.txt não deve ser usado para ocultar suas páginas da web do Google. Você deve usar a metatag noindex para essa finalidade.
Instruções padrão do robots.txt no Magento 2
Por padrão, o arquivo robots.txt gerado pelo Magento contém apenas algumas instruções básicas para o web crawler.
# Instruções padrão fornecidas pelo Magento Agente de usuário: * Não permitir: /lib/ Não permitir: /*.php$ Não permitir: /pkginfo/ Não permitir: /relatório/ Não permitir: /var/ Não permitir: /catálogo/ Não permitir: /cliente/ Não permitir: /sendfriend/ Não permitir: /revisão/ Não permitir: /*SID=
Para gerar essas instruções padrão, clique no botão Reset to Defaults na configuração do Search Engine Robots em seu backend Magento.
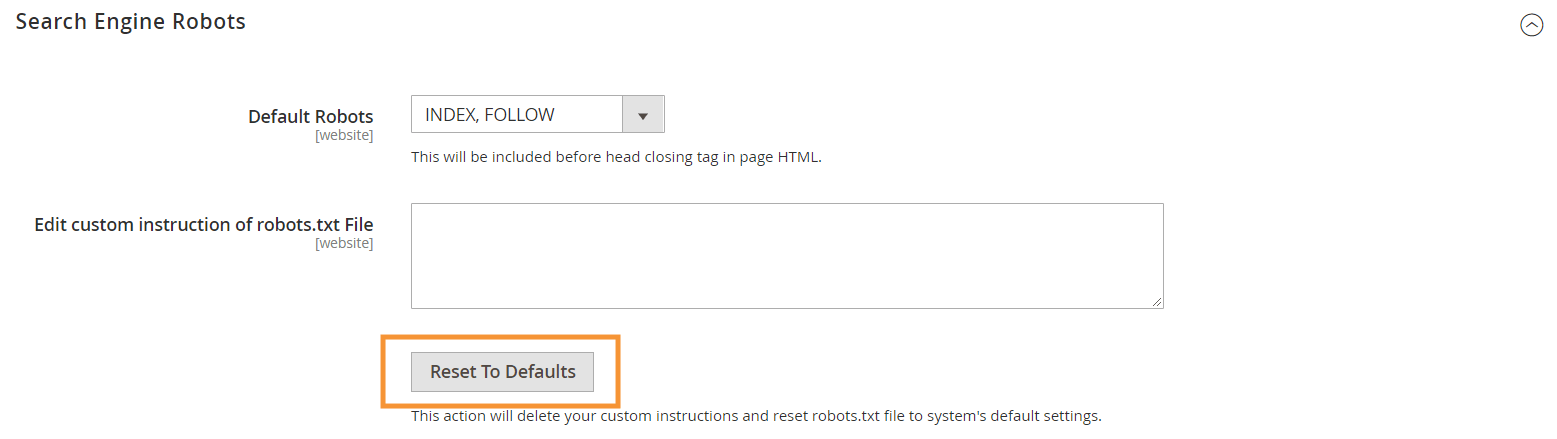
Por que você precisa criar instruções personalizadas de robots.txt no Magento 2
Embora as instruções padrão do robots.txt fornecidas pelo Magento sejam necessárias para informar aos rastreadores para evitar o rastreamento de certos arquivos que são usados internamente pelo sistema, elas não são suficientes para a maioria das lojas Magento.
Os robôs do mecanismo de pesquisa têm apenas uma quantidade finita de recursos para rastrear páginas da web. Para um site com milhares ou até milhões de URLs para rastrear (o que é mais comum do que você imagina), você precisará priorizar o tipo de conteúdo que precisa ser rastreado (com um sitemap.xml) e não permitir conteúdo irrelevante páginas sejam rastreadas (com um robots.txt). A última parte é feita ao não permitir que páginas duplicadas, irrelevantes e desnecessárias sejam rastreadas em seu robots.txt.
Formato básico das diretivas robots.txt
As instruções no robots.txt são apresentadas de forma coerente, amigável para usuários não técnicos:
# Regra 1 Agente do usuário: Googlebot Não permitir: /nogooglebot/ # Regra 2 Agente de usuário: * Permitir: / Mapa do site: https://www.example.com/sitemap.xml
-
User-agent: indica o rastreador específico para o qual a regra se destina. Alguns agentes de usuário comuns sãoGooglebot,Googlebot-Image,Mediapartners-Google,Googlebot-Video, etc. Para obter uma lista extensa de rastreadores comuns, consulte Visão geral dos rastreadores do Google.
-
Allowe nãoDisallow: especifique os caminhos que os rastreadores designados podem ou não acessar. Por exemplo,Allow: /significa que o rastreador pode acessar todo o site sem restrições.
-
Sitemap: indica o caminho para o sitemap de sua loja. O Sitemap é uma maneira de informar aos rastreadores do mecanismo de pesquisa qual conteúdo priorizar, enquanto o restante do conteúdo no robots.txt informa aos rastreadores qual conteúdo eles podem ou não rastrear.
Também em robots.txt, você pode usar vários curingas para valores de caminho, como:

-
*: Quando colocado emuser-agent, o asterisco (*) refere-se a todos os rastreadores de mecanismos de pesquisa (exceto rastreadores AdsBot) que visitam o site. Quando usado nas diretivasAllow/Disallow, significa 0 ou mais instâncias de qualquer caractere válido (por exemplo,Allow: /example*.csscorresponde a /example.css e também / example12345.css ). -
$: designa o final de uma URL. Por exemplo,Disallow: /*.php$bloqueará todos os arquivos que terminam com .php -
#: designa o início de um comentário, que os rastreadores ignorarão.
Observação : exceto para o caminho sitemap.xml, os caminhos em robots.txt são sempre relativos , o que significa que você não pode usar URLs completos (por exemplo, https://simicart.com/nogooglebot/) para especificar caminhos.
Configurando o robots.txt no Magento 2
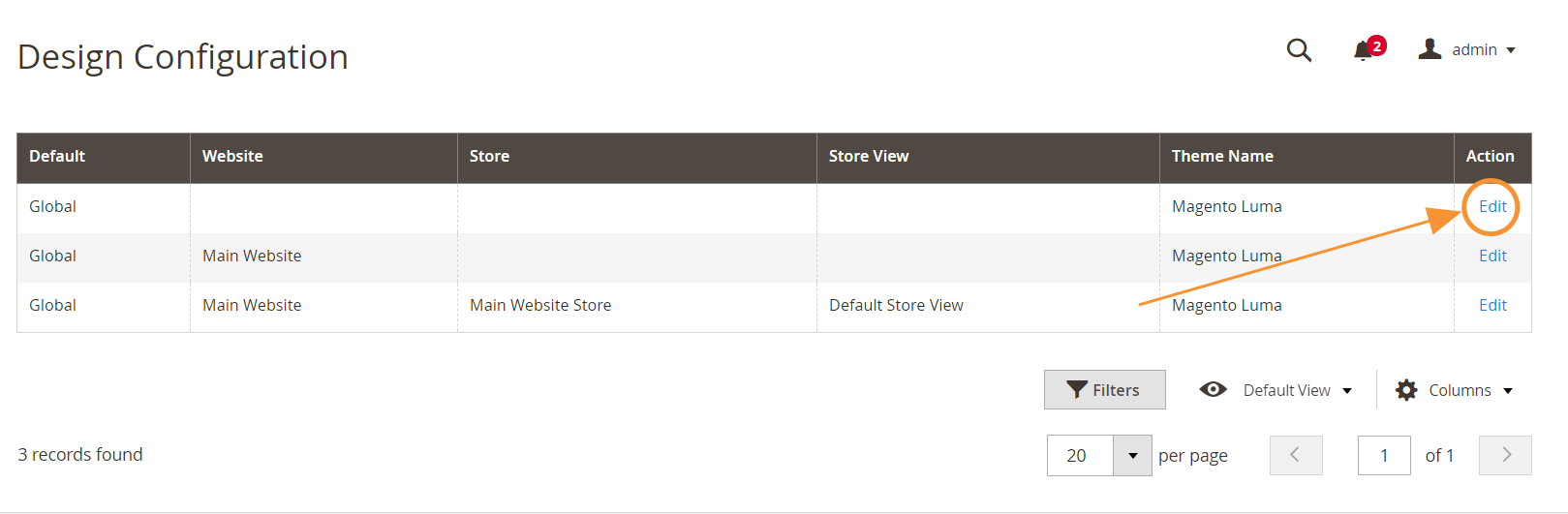
Para acessar o editor de arquivos robots.txt, no seu administrador do Magento 2:
Etapa 1 : Vá para Conteúdo > Design > Configuração
Etapa 2 : Edite a configuração global na primeira linha
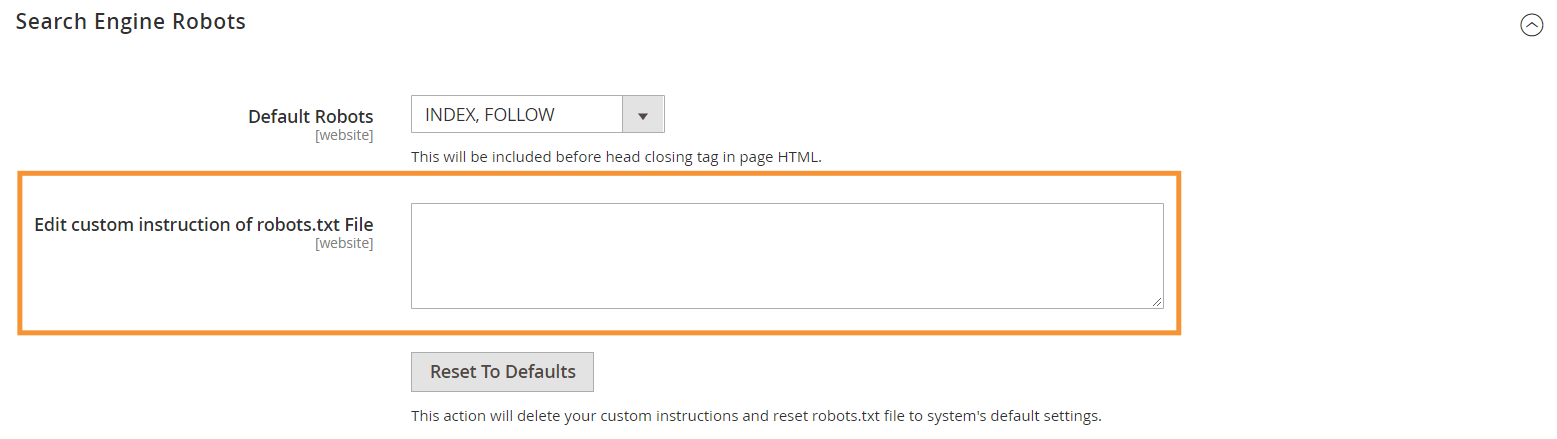
Etapa 3 : na seção Robôs do mecanismo de pesquisa, edite as instruções personalizadas
Instruções recomendadas para o robots.txt
Aqui estão nossas instruções recomendadas que devem atender às necessidades gerais. Claro, cada loja é diferente e você pode precisar ajustar ou adicionar mais algumas regras para obter os melhores resultados.
Agente de usuário: * # Instruções padrão: Não permitir: /lib/ Não permitir: /*.php$ Não permitir: /pkginfo/ Não permitir: /relatório/ Não permitir: /var/ Não permitir: /catálogo/ Não permitir: /cliente/ Não permitir: /sendfriend/ Não permitir: /revisão/ Não permitir: /*SID= # Não permita arquivos Magento comuns no diretório raiz: Não permitir: /cron.php Não permitir: /cron.sh Não permitir: /error_log Não permitir: /install.php Não permitir: /LICENSE.html Não permitir: /LICENSE.txt Não permitir: /LICENSE_AFL.txt Não permitir: /STATUS.txt # Não permitir conta de usuário & Páginas de checkout: Não permitir: /checkout/ Não permitir: /onestepcheckout/ Não permitir: /cliente/ Não permitir: /cliente/conta/ Não permitir: /cliente/conta/login/ # Não permitir páginas de pesquisa de catálogo: Não permitir: /catalogsearch/ Não permitir: /catalog/product_compare/ Não permitir: /catalog/category/view/ Não permitir: /catalog/product/view/ # Não permitir pesquisas de filtro de URL Não permitir: /*?dir* Não permitir: /*?dir=desc Não permitir: /*?dir=asc Não permitir: /*?limit=all Não permitir: /*?modo* # Não permitir diretórios do CMS: Não permitir: /app/ Não permitir: /bin/ Não permitir: /dev/ Não permitir: /lib/ Não permitir: /phpserver/ Não permitir: /pub/ # Não permitir conteúdo duplicado: Não permitir: /tag/ Não permitir: /revisão/ Não permitir: /*?*product_list_mode= Não permitir: /*?*product_list_order= Não permitir: /*?*product_list_limit= Não permitir: /*?*product_list_dir= # Configurações do servidor # Proibir diretórios e arquivos técnicos gerais em um servidor Não permitir: /cgi-bin/ Não permitir: /cleanup.php Não permitir: /apc.php Não permitir: /memcache.php Não permitir: /phpinfo.php # Não permitir pastas de controle de versão e outros Não permitir: /*.git Não permitir: /*.CVS Não permitir: /*.Zip$ Não permitir: /*.Svn$ Não permitir: /*.Idea$ Não permitir: /*.Sql$ Não permitir: /*.Tgz$ Mapa do site: https://www.example.com/sitemap.xml
Conclusão
Criar um arquivo robots.txt é apenas uma das muitas etapas na lista de verificação do Magento SEO - e otimizar adequadamente uma loja Magento para os mecanismos de pesquisa com certeza não é uma tarefa fácil para a maioria dos proprietários de lojas. Se você não quiser lidar com isso, podemos cuidar de tudo para você. Aqui no SimiCart, fornecemos serviços de SEO e otimização de velocidade que garantem os melhores resultados para sua loja.