
Obtenha o máximo do Apache Solr: uma exploração técnica da indexação de pesquisa
Publicados: 2023-02-21Um recurso de pesquisa aprimora a experiência do usuário de um site, permitindo que o usuário encontre o que está procurando com facilidade e rapidez. Mais ainda para grandes sites, sites de comércio eletrônico e sites com conteúdo dinâmico (sites de notícias, blogs).
O Apache Solr é uma das plataformas de pesquisa mais populares usadas por sites de todos os tamanhos. É um mecanismo de pesquisa de código aberto baseado em Java que permite pesquisar grandes quantidades de dados, como artigos, produtos, análises de clientes e muito mais. Dê uma olhada mais profunda no Apache Solr neste artigo.
Confira este artigo para saber como configurar o Apache Solr no Drupal

Por que o Apache Solr é tão popular?
O Apache Solr é rápido e flexível e permite pesquisa de texto completo, realce de hits (destaca o termo de pesquisa correspondente), pesquisa facetada (uma pesquisa mais refinada), indexação em tempo real (permite que o novo conteúdo seja indexado imediatamente), agrupamento dinâmico ( organiza os resultados da pesquisa em grupos), integração de banco de dados, recursos NoSQL (banco de dados não relacional) e manipulação avançada de documentos (para indexar uma ampla variedade de formatos de documentos como PDF, MS Office, Open office).
Alguns fatos interessantes sobre o Apache Solr:
- Foi inicialmente desenvolvido pela CNET Networks, Inc. como um motor de busca para seus sites e artigos. Mais tarde, tornou-se de código aberto e tornou-se um projeto Apache de alto nível.
- Suporta várias linguagens de programação como PHP, Java, Python e Ruby. Ele também fornece APIs para esses idiomas.
- Possui suporte integrado para pesquisa geoespacial, permitindo pesquisar conteúdo com base em sua localização. Especialmente útil para sites como sites imobiliários, sites de viagens, etc.
- Oferece suporte a recursos de pesquisa avançada, como verificação ortográfica, preenchimento automático e pesquisa personalizada por meio de APIs e plug-ins.
- Usa Lucene para indexação e pesquisa.
o que é lucene
Apache Lucene é uma biblioteca de pesquisa Java de software livre que permite adicionar facilmente pesquisa ou recuperação de informações ao aplicativo. É versátil, poderoso, preciso e funciona com um algoritmo de pesquisa eficiente.
Embora conhecido por seus recursos de pesquisa de texto completo, o Lucene também pode ser usado para classificação de documentos, análise de dados e recuperação de informações. Ele também oferece suporte a muitos idiomas além do inglês, como alemão, francês, espanhol, chinês, japonês e muito mais.
O que é indexação?
Todos os mecanismos de pesquisa começam com a indexação. A indexação é o processamento de dados originais em pesquisa de referência cruzada altamente eficiente para facilitar a pesquisa rápida.
Os mecanismos de pesquisa não indexam os dados diretamente. Os textos são primeiro divididos em tokens (elementos atômicos). Pesquisar é o processo de consultar o índice de pesquisa e recuperar o documento correspondente à consulta.
Vantagens da indexação
- Recuperação de informações rápida e precisa (coleta, analisa e armazena)
- Sem indexação, o mecanismo de pesquisa requer mais tempo para digitalizar todos os documentos
Fluxo de indexação
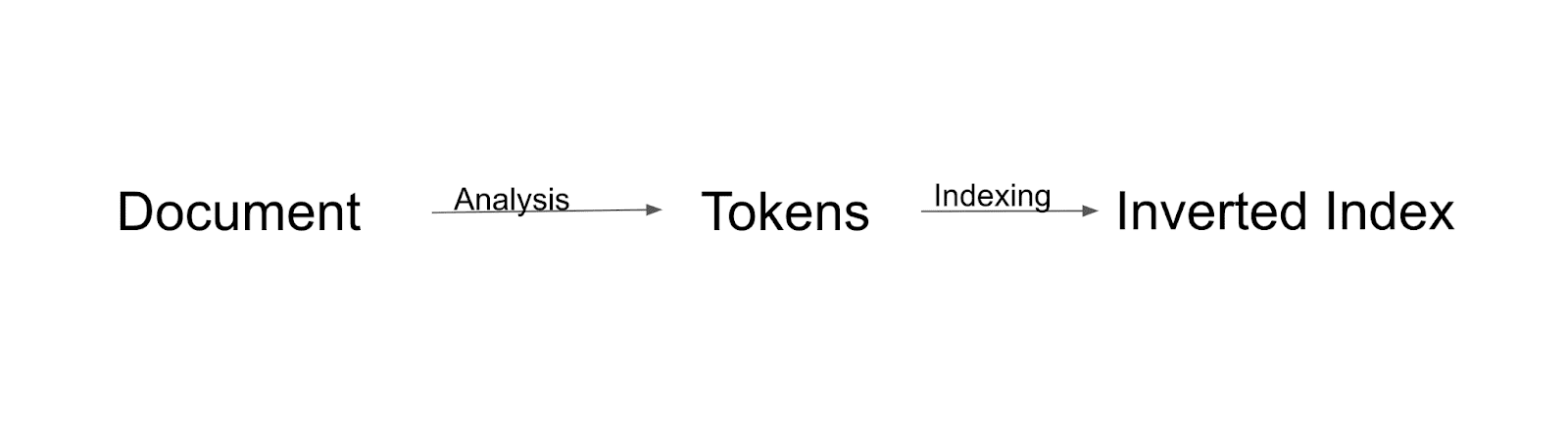
Primeiro, o documento será analisado e dividido em tokens. Todos esses tokens serão indexados ao índice invertido. O índice invertido é uma maneira pela qual o Solr cria o índice.
Como funciona a indexação invertida
Vamos considerar que temos 3 documentos:
- Eu amo chocolate (D 1)
- Eu pedi bolo de chocolate (D 2)
- Fiz bolo grande de baunilha (D 3)
A forma como é tokenizada é mostrada na 2ª coluna da tabela abaixo.

“Chocolate” está disponível em D1 e D2
“Bolo” está disponível em D2 e D3
“Grande” está disponível em D3
“Ordenado” está disponível em D2
“Preparado” está disponível em D3
“Vanilla” está disponível em D3
Você notará que palavras como “eu”, “amor” não são simbolizadas. Estas são chamadas de palavras de parada que não serão indexadas ou pesquisáveis pelo Solr.
Então, quando alguém procura pelo termo “Bolo de Chocolate”, o mecanismo procura no índice. Em vez de procurar o documento, ele primeiro examina o índice para ver em quais documentos as palavras “Chocolate” e “Bolo” se enquadram. Isso torna mais fácil e rápido buscar apenas o documento específico. Isso é chamado de indexação invertida.
Esquema de armazenamento
O Apache Solr usa um esquema de armazenamento baseado em documento e armazena todos os dados como um documento separado dentro de uma coleção. Isso permite armazenamento e recuperação de dados eficientes e flexíveis.
No Drupal, cada nó é considerado um documento. Portanto, quando você indexa seu nó no Apache Solr, ele é considerado um documento. Cada documento pode conter vários campos. O Lucene não possui um esquema global comum. O que significa que você pode indexar qualquer tipo de campo em cada documento no Apache Solr.

Como instalar o Apache Solr
- Primeiro, certifique-se de ter o Java instalado em seu sistema.
- Em seguida, vamos instalar o Solr daqui: https://solr.apache.org/downloads.html
- Baixe e extraia Solr.
- Execute este comando na pasta Solr.
◦ bin/solr -e techproducts
Isso criará um núcleo fictício para demonstração e também iniciará o servidor Solr.
- Uma vez iniciado o servidor, vá ao seu navegador e digite “http://localhost:8983/”.
- Certifique-se de que o Solr foi instalado com sucesso com o núcleo fictício.
Estrutura de Diretórios
Depois de instalar o Solr, você verá muitas pastas como:
Docs - contém documentação sobre o Solr
Dist - Arquivo .jar principal do Solr
Contrib - contém plug-ins complementares e recursos especializados do Solr
Bin - scripts do Solr
Exemplo - contém demonstrar recursos solr
Servidor - coração do Solr. Contém aplicativo da web Solr, logs, núcleo Solr

Arquivos de configuração
Para criar um núcleo, precisamos de dois arquivos obrigatórios.
- Schema.xml
- Solrconfig.xml
Schema.xml
- Ele conterá os tipos de campos que você planeja oferecer suporte e como esses tipos devem ser analisados.
Solrconfig.xml
- Contém várias configurações que controlam o comportamento de um núcleo Solr, como manipulador de solicitação, despachante de solicitação, componentes de consulta, manipuladores de atualização, etc.
Consultando no Solr
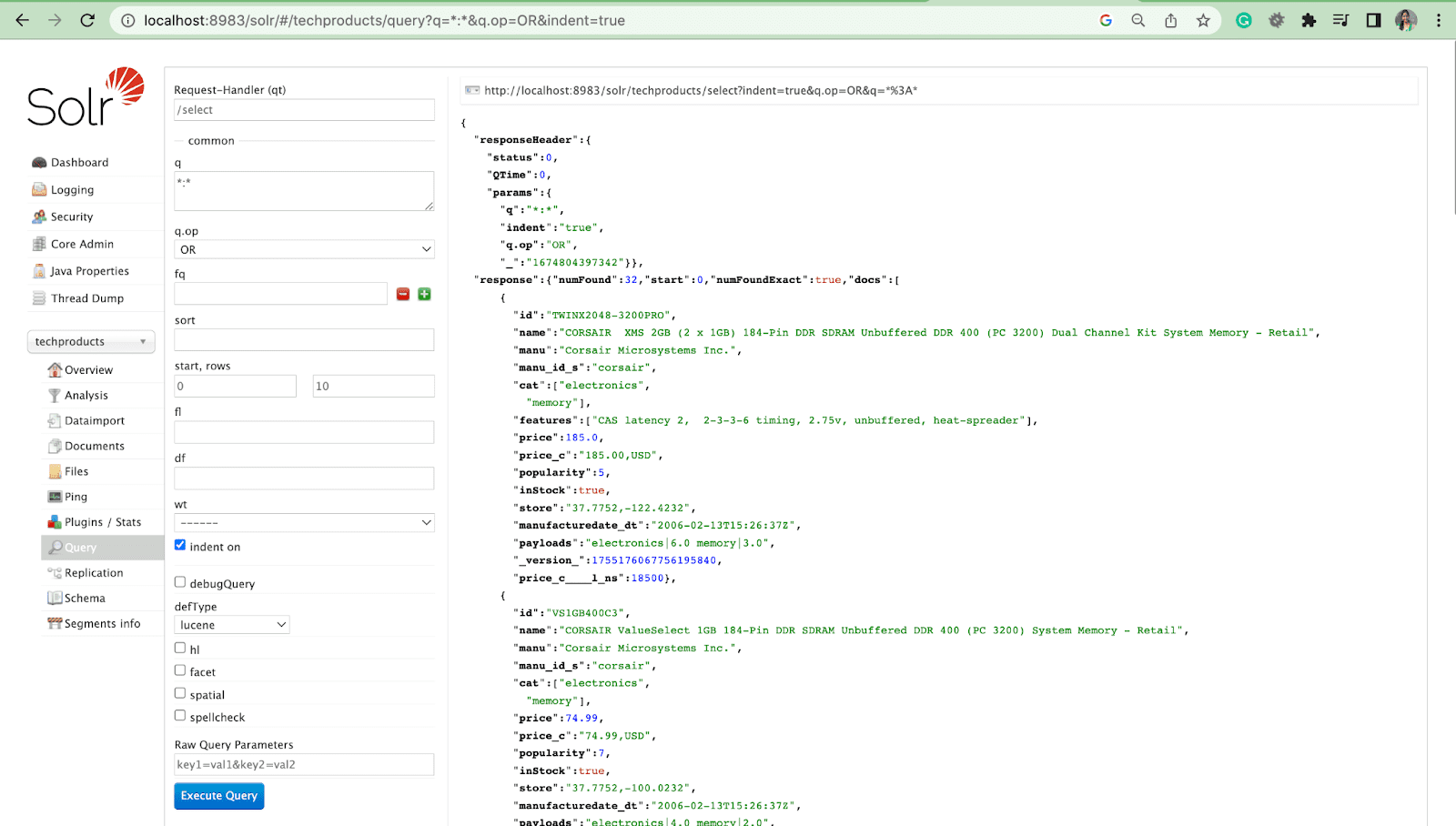
Agora vamos ver como consultar os resultados do Solr na interface do administrador do Solr.
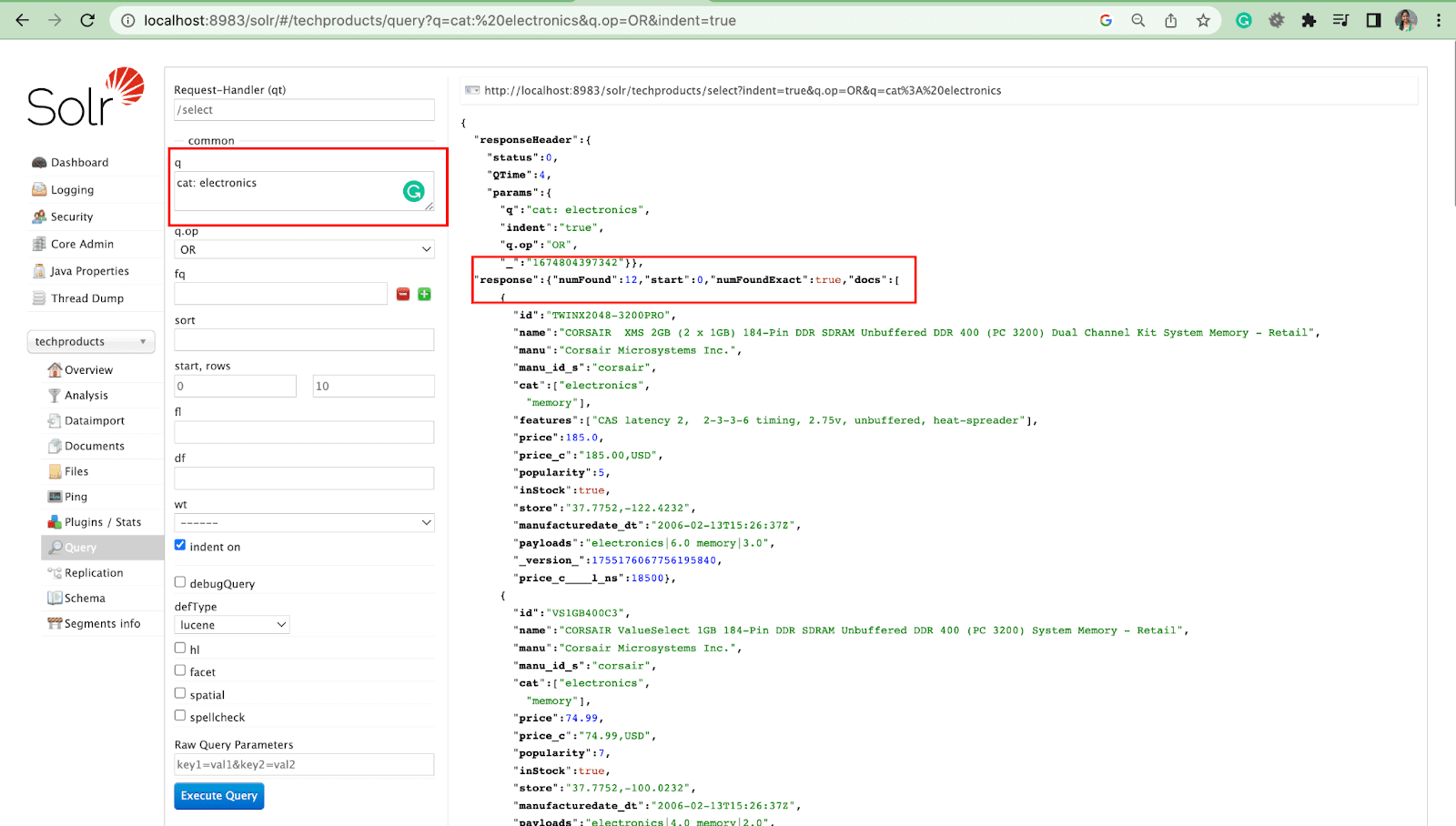
Parâmetro de Consulta
- Parâmetros locais são argumentos em uma solicitação Solr que são específicos para um parâmetro de consulta.
Por exemplo: gato: eletrônicos
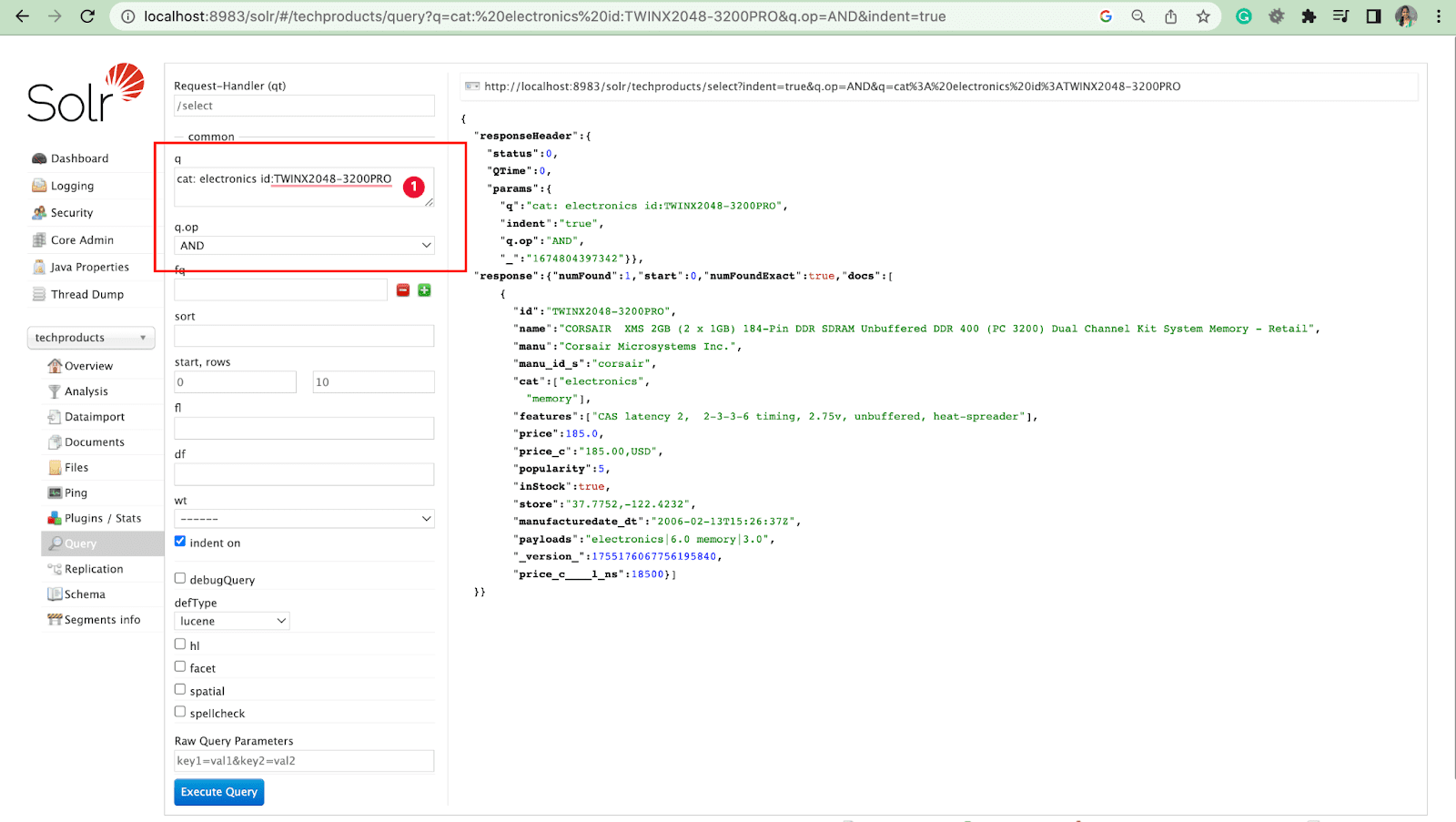
Parâmetro de consulta com operações
- Podemos consultar vários campos com operação.
Por exemplo: cat: electronics id:TWINX2048-3200PRO with q.op AND
[OU]
gato: eletrônica E id:TWINX2048-3200PRO
[OU]
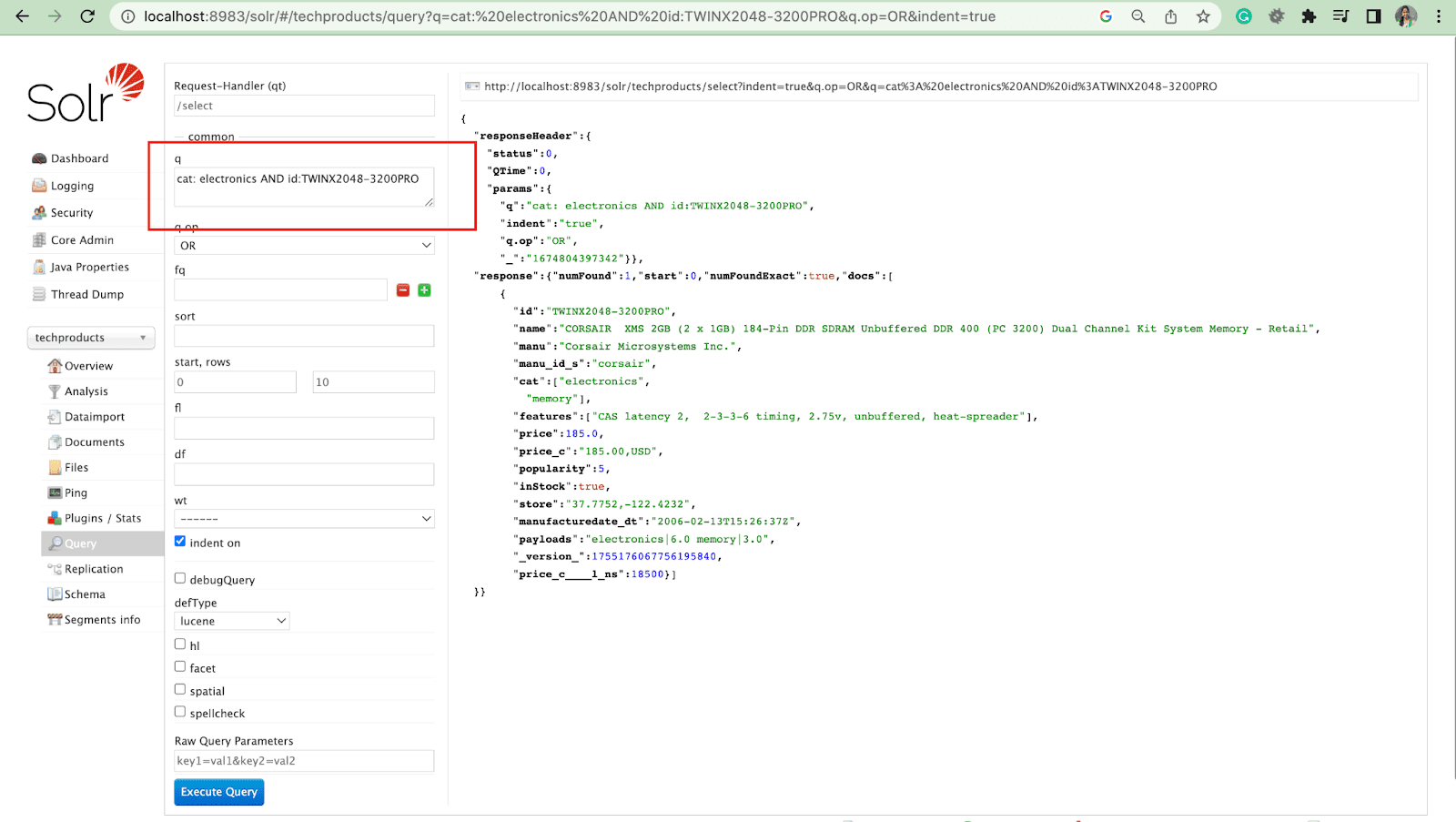
Consulta de filtro
Uma consulta de filtro ajuda a restringir os resultados de uma pesquisa. Uma consulta pode ser especificada pelo parâmetro fq para restringir quais documentos são retornados no superconjunto, sem afetar a pontuação.
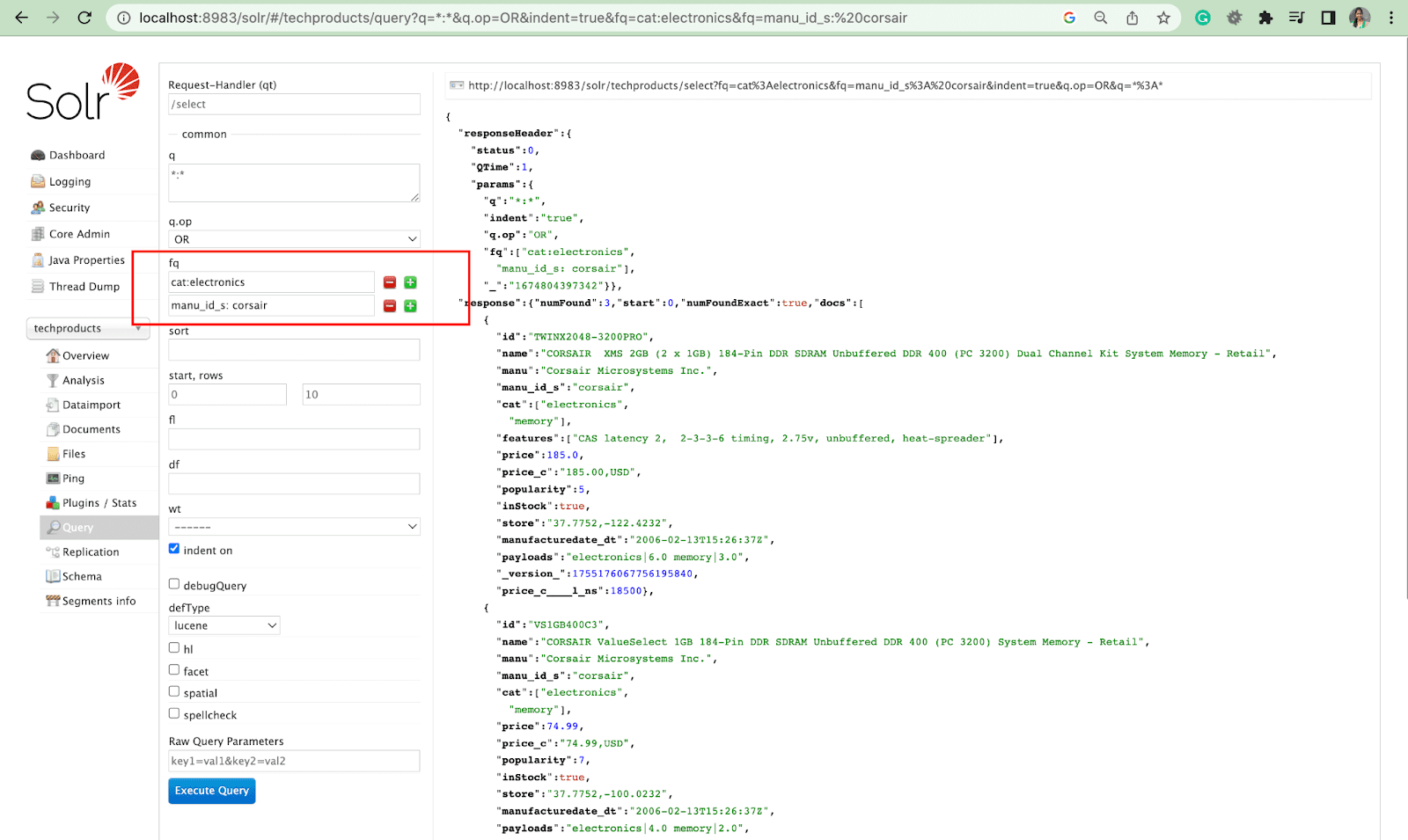
Parâmetro de classificação
O parâmetro sort organiza os resultados da pesquisa em ordem crescente (asc) ou decrescente (desc). Dependendo do conteúdo, o parâmetro pode ser usado em ordem numérica ou alfabética.
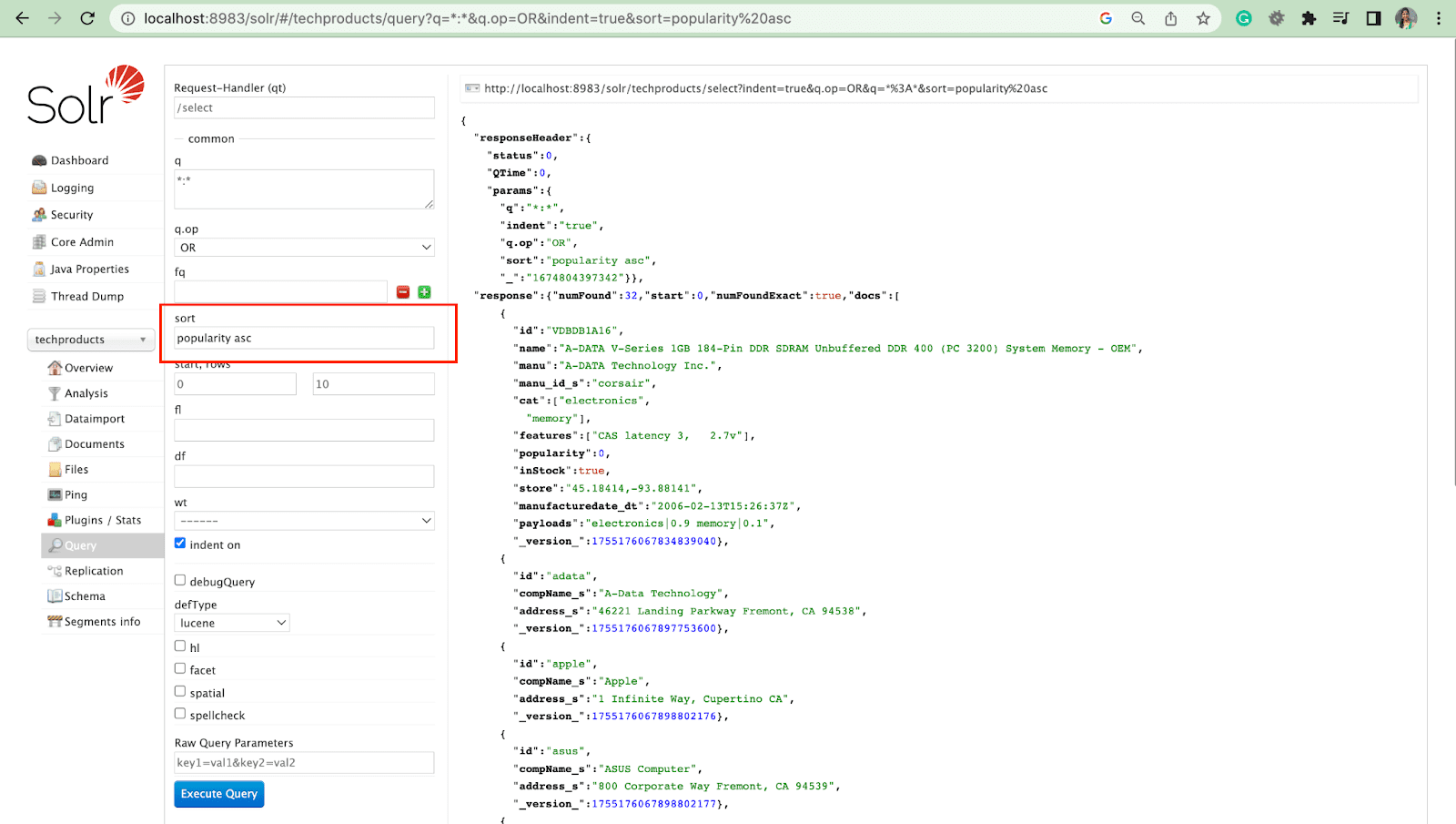
Parâmetro de linhas
O parâmetro linhas permite paginar os resultados de uma consulta.
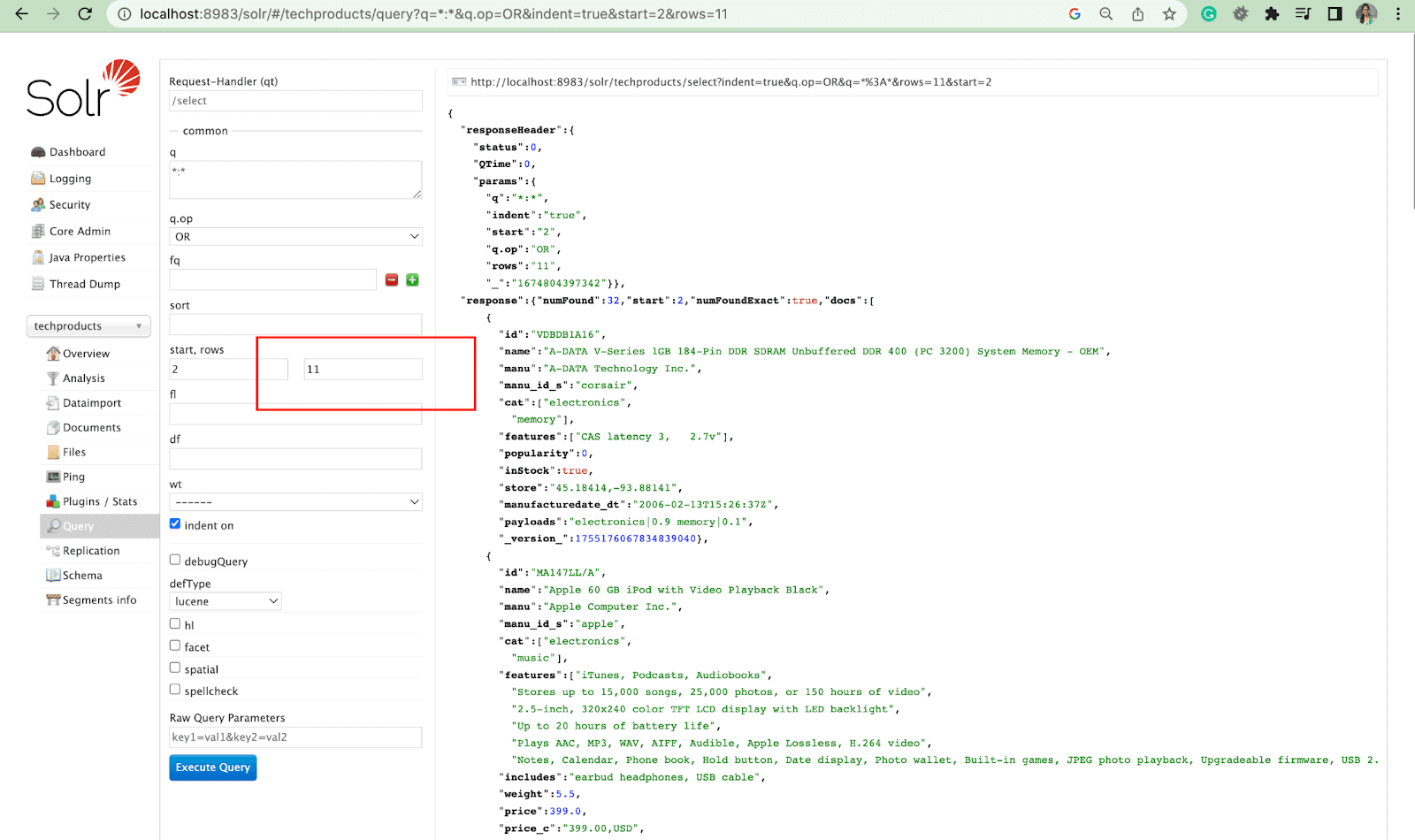
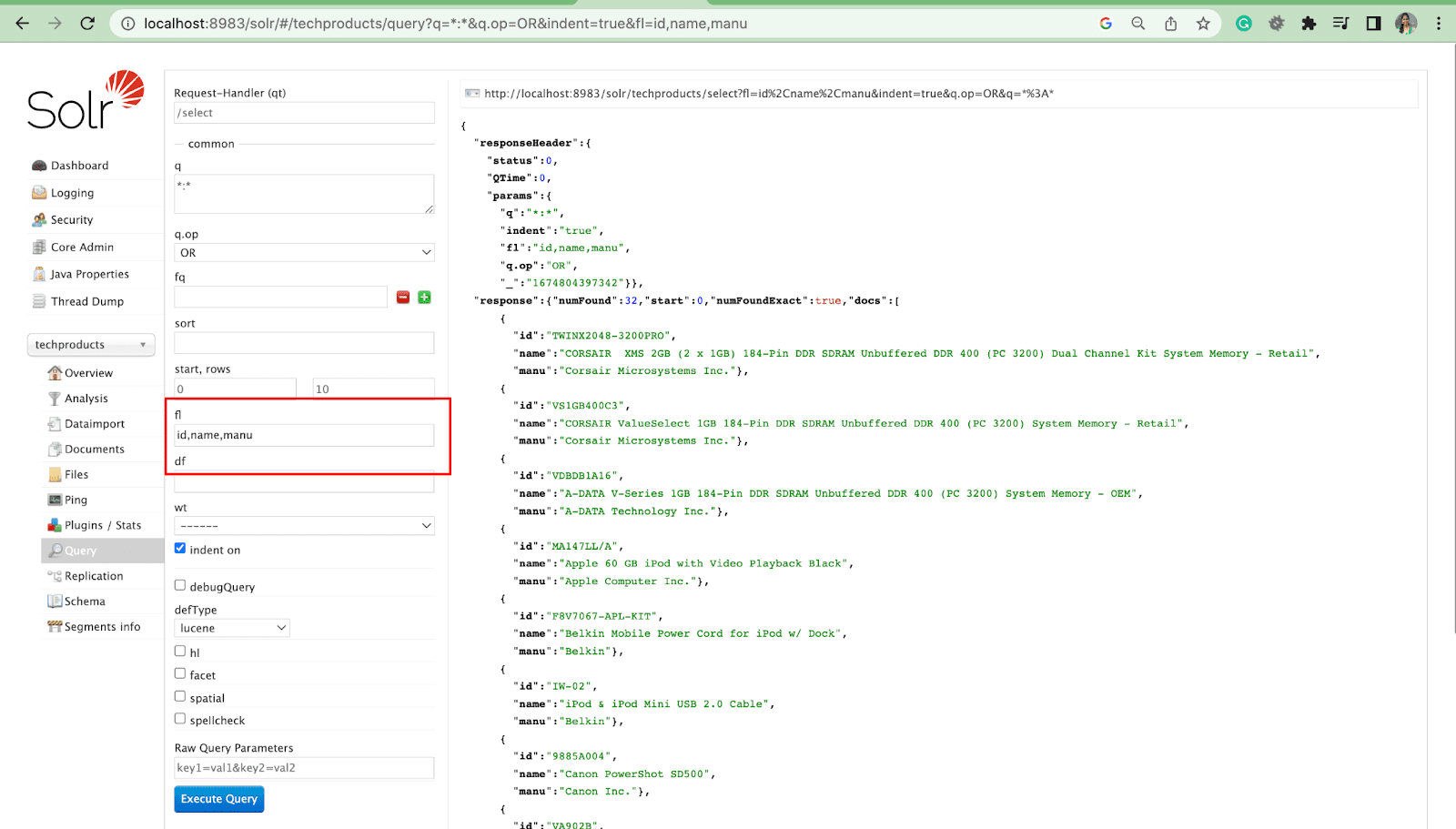
Parâmetro da lista de campos
O parâmetro fl limita as informações incluídas em uma resposta de consulta a uma lista especificada de campos.
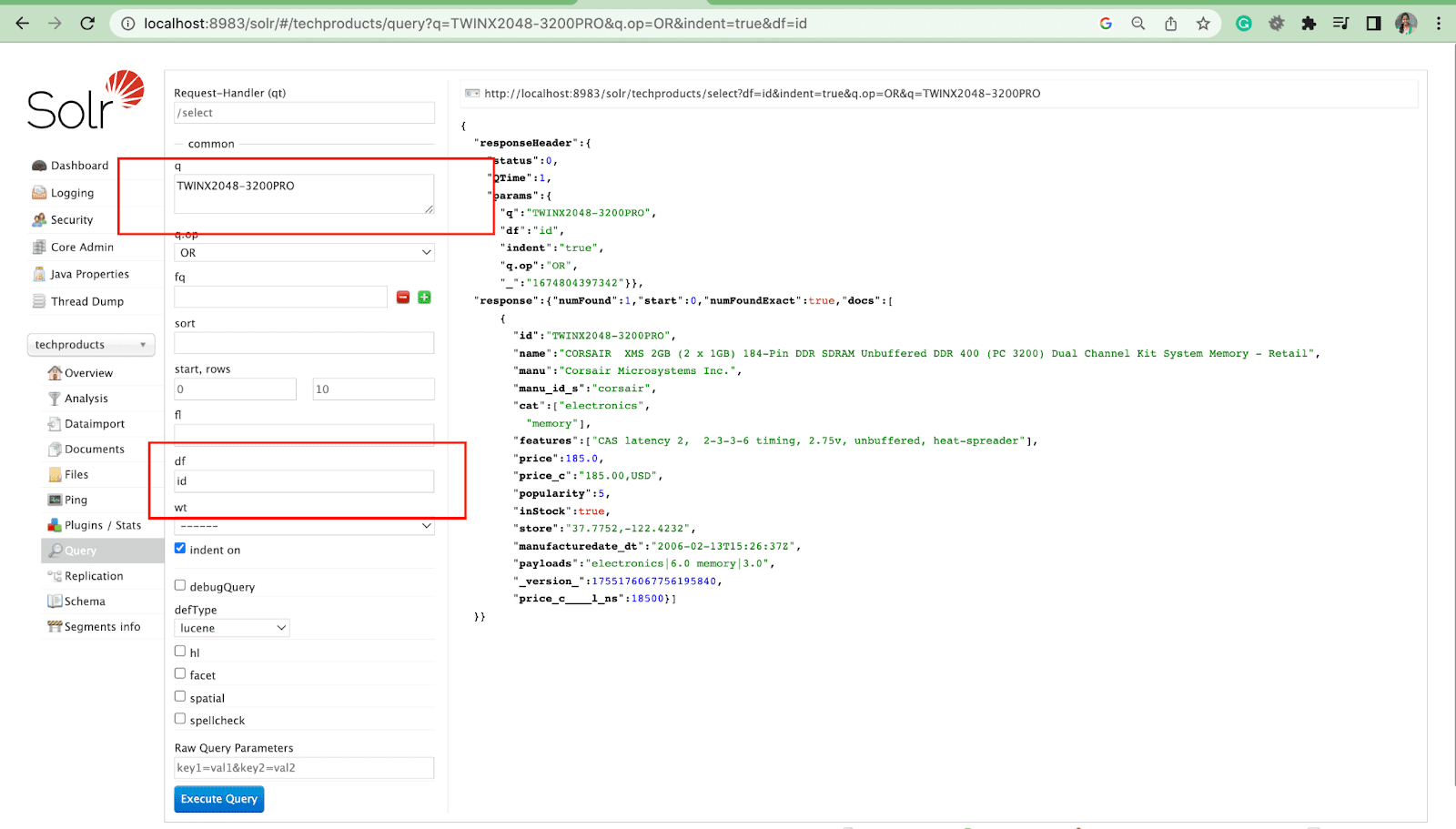
Parâmetro de campo padrão
O parâmetro de campo padrão é o campo padrão para o parâmetro de consulta.
Parâmetro de Destaques
O recurso de destaque no Solr permite a inclusão de fragmentos de documentos que correspondam a uma consulta.
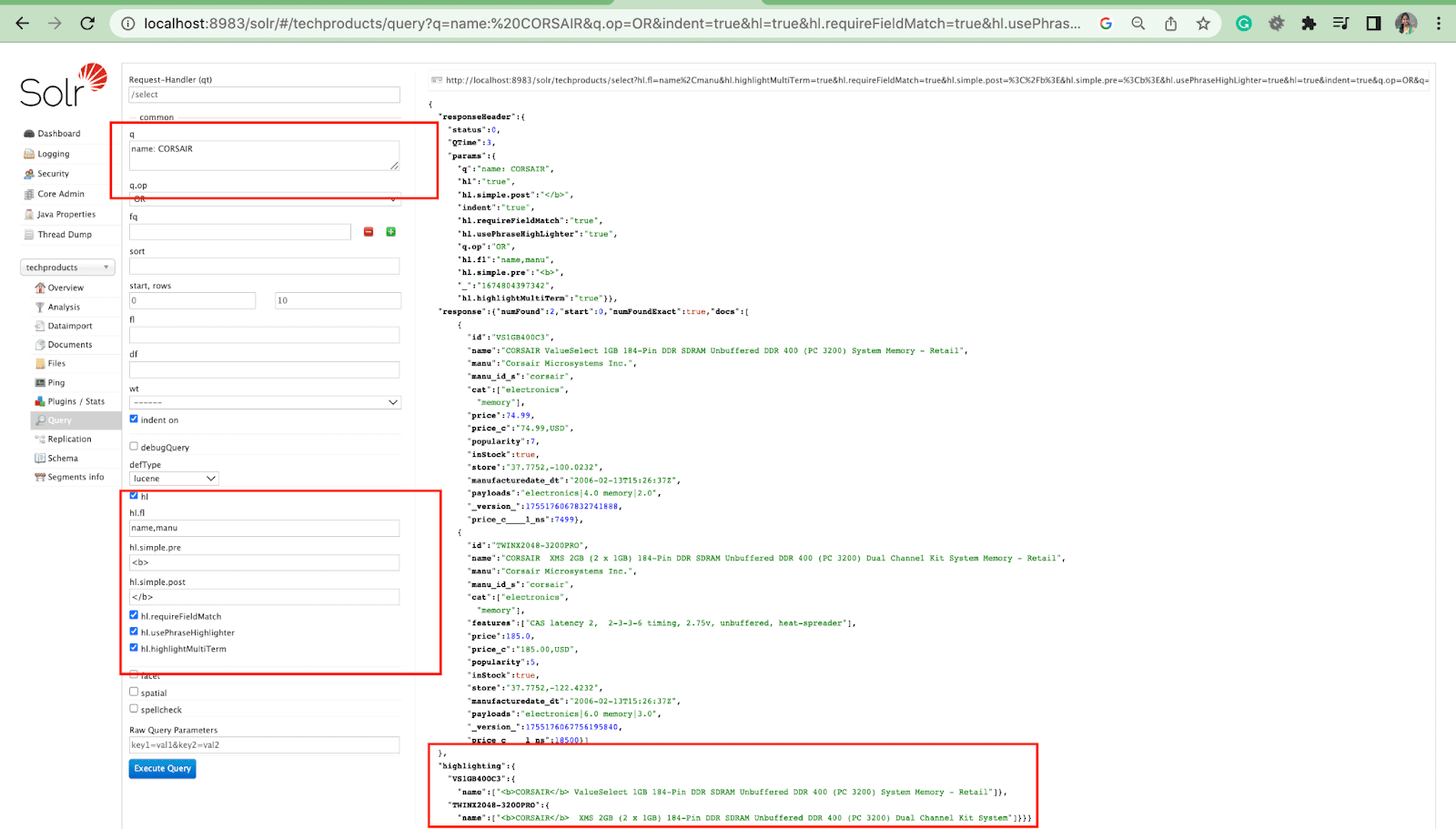
Alguns dos parâmetros de destaque mais comuns são:
- Hl.fl - Destaca uma lista de campos.
- Hl.simple.pre - Especifica qual "tag" deve ser usada antes de uma palavra destacada.
- Hl.simple.post - Especifica qual “tag” deve ser usada após um termo destacado.
- hl.highlightMultiTerm - Se for definido como true , o Solr destacará as consultas curinga. Se false , eles não serão realçados.
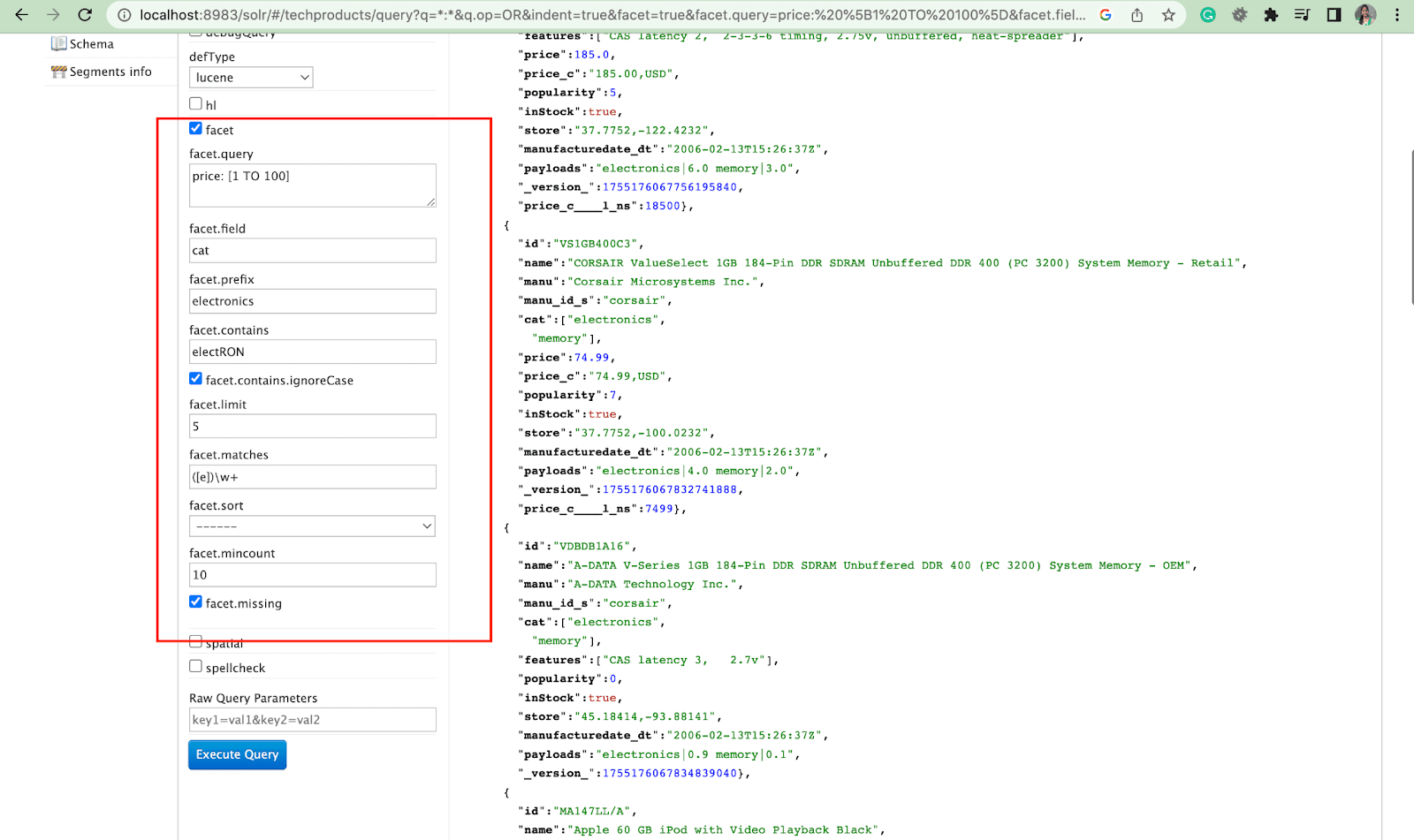
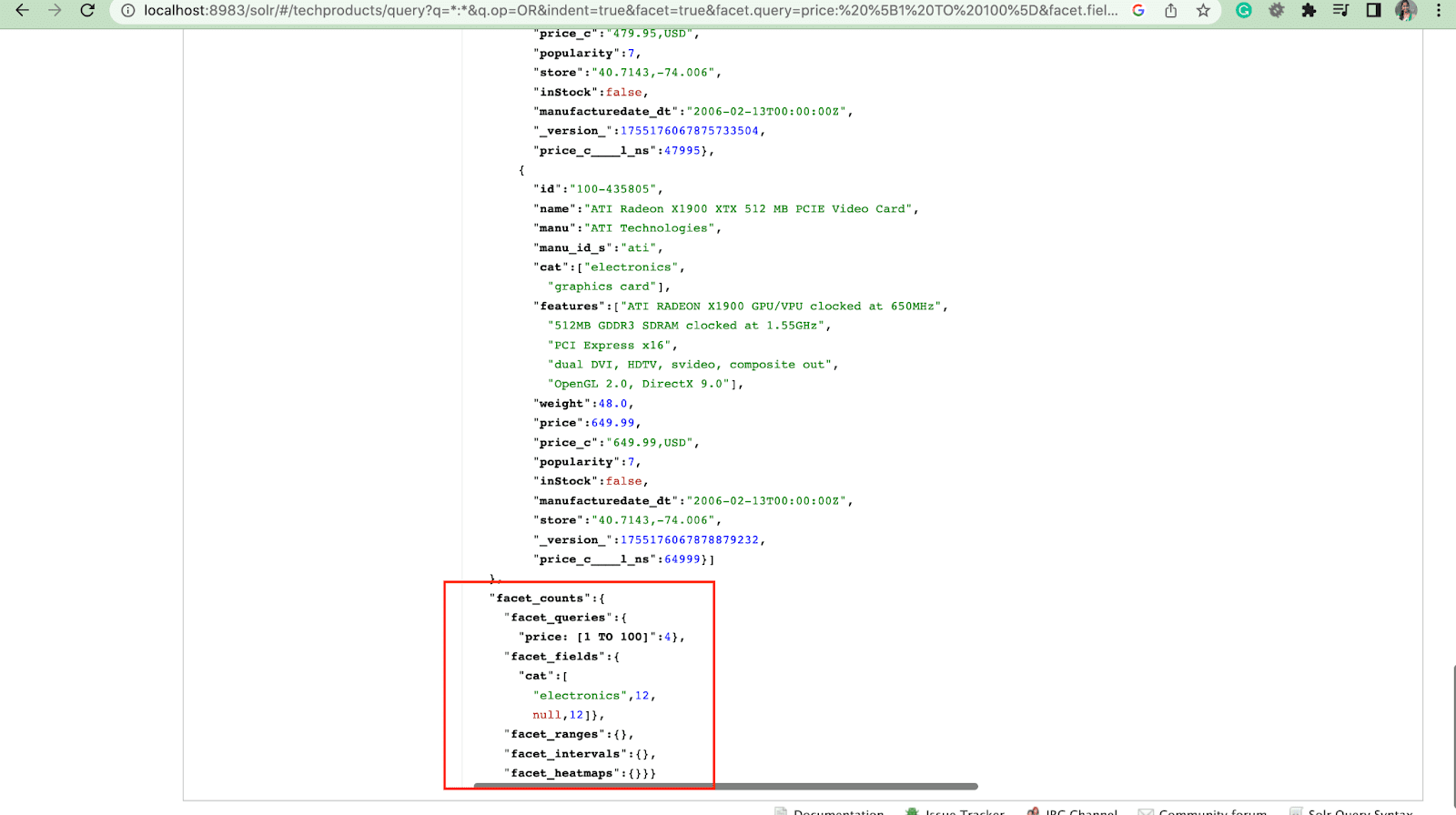
Faceta:
As facetas permitem que os usuários explorem e refinem grandes conjuntos de resultados de pesquisa. Eles são exibidos em uma interface do usuário como caixas de seleção, menus suspensos ou outros controles. Os dois parâmetros gerais para controlar facetas são:
- Parâmetro de faceta
Usando o parâmetro facet, os usuários podem gerar facetas com base nos valores de um ou mais campos em seu índice de pesquisa. Nos resultados da pesquisa, o parâmetro de faceta pode ser configurado para controlar como as facetas são geradas e exibidas.
2. Parâmetro Facet.query
Quando um usuário inclui um parâmetro facet.query em sua consulta Solr, o Solr gera uma lista de contagens de facetas que correspondem ao número de documentos no índice que correspondem a cada consulta. Facet.query é útil quando você deseja gerar facetas com base em critérios de pesquisa complexos que não podem ser facilmente representados usando um valor de campo simples.
Existem vários outros parâmetros de faceta como facet.field (para especificar os campos que devem ser usados para gerar facetas) , facet.limit (número máximo de facetas a serem exibidas para cada campo) , facet.mincount (número mínimo de documento necessário para a faceta a ser incluída na resposta) , facet.sort (especifica a ordem na qual os valores da faceta devem ser exibidos) .
Pensamentos finais
O Apache Solr é um mecanismo de pesquisa altamente versátil que vem com muitos recursos interessantes que podem ser personalizados de acordo com suas necessidades. O Drupal funciona extremamente bem com o Apache Solr. Se você está procurando por especialistas em Drupal para configurar um poderoso mecanismo de busca para seu novo projeto, nós adoraríamos ir mais longe!