
Co to jest klaster pracy awaryjnej? Jak to działa + rozwiązania
Opublikowany: 2023-09-22Firmy potrzebujące transakcji online nie mogą sobie pozwolić na awarie serwerów. W rezultacie firmy te szukają sposobów na stworzenie niezawodnej procedury, która zapewni bezpieczeństwo ich danych nawet w przypadku awarii serwera. Jedną z takich metod jest klaster pracy awaryjnej.
Klaster pracy awaryjnej może być zarządzany przez rozwiązania dostawcy zarządzanego systemu nazw domen (DNS); jednak zrozumienie jego mechanizmu i kluczowych funkcji może pomóc w ograniczeniu wszelkich problemów związanych z przełączaniem awaryjnym.
Co to jest klaster pracy awaryjnej?
Klaster pracy awaryjnej działa na grupie serwerów komputerowych, aby zapewnić wysoką dostępność (HA) lub ciągłą dostępność (CA) dla aplikacji serwerowych. Technologia ta gwarantuje, że w przypadku awarii jednego serwera lub węzła inny węzeł klastra będzie gotowy do przejęcia obciążenia bez zakłóceń.
Dzięki takiemu podejściu obciążenia serwera będą skalowalne i dostępne. Wiele głównych programów serwerowych, takich jak Microsoft Exchange , Microsoft SQL Server i Hyper-V , w celu ochrony opiera się na klastrze pracy awaryjnej.
Niektóre klastry pracy awaryjnej wykorzystują serwery fizyczne, podczas gdy inne korzystają z maszyn wirtualnych (VM) . Każdy wybiera rodzaj klastra, jakiego potrzebuje, w oparciu o wymagania swojej aplikacji serwerowej.
Klaster składa się z dwóch lub więcej węzłów wymieniających dane i oprogramowanie do przetwarzania za pośrednictwem kabli fizycznych lub wyspecjalizowanej bezpiecznej sieci. Do równoważenia obciążenia, przechowywania danych oraz przetwarzania współbieżnego lub równoległego można zastosować kilka rodzajów technologii klastrowania. W niektórych przypadkach klastry pracy awaryjnej są łączone z dodatkowymi technologiami klastrowymi.
Podstawową funkcją klastra pracy awaryjnej jest udostępnianie urzędu certyfikacji lub wysokiej dostępności dla aplikacji i usług. Klastry CA, zwane także klastrami odpornymi na awarie (FT), umożliwiają użytkownikom końcowym dalsze korzystanie z aplikacji i usług nawet w przypadku awarii serwera. Może wystąpić krótka przerwa w świadczeniu usług spowodowana klastrami HA, ale system można odzyskać bez utraty danych i z krótkimi przestojami.
Dlaczego klaster pracy awaryjnej jest ważny?
Dzięki klastrowi pracy awaryjnej możesz naprawiać nieaktywne węzły bez wyłączania bazy danych, unikając problemów z przestojami i szybko naprawiając uszkodzone serwery. Co więcej, w przypadku awarii sprzętu technika ta kończy działanie bazy danych w celu ochrony aktywnych węzłów.
Klaster pracy awaryjnej automatyzuje także odzyskiwanie danych w przypadku awarii. Zmniejsza to Twoją zależność od ekipy informatycznej i pozwala na szybkie przywrócenie działania serwerów. Zapewnia także doskonałą dostępność klastra ustrukturyzowanego języka zapytań (SQL) przy minimalnych przestojach. Zautomatyzowana funkcja przełączania awaryjnego klastra pracy awaryjnej pozwala zachować funkcjonalność bazy danych nawet w przypadku awarii sprzętu.
Jak działają klastry pracy awaryjnej?
Klaster pracy awaryjnej składa się z dwóch podstawowych procesów, HA i CA, dla aplikacji serwerowych.
Podczas gdy klastry pracy awaryjnej urzędu certyfikacji starają się osiągnąć 100% dostępności, klastry HA dążą do poziomu 99,999%, powszechnie znanego jako pięć dziewiątek. Łączny czas przestoju w ciągu roku nie przekracza 5,26 minuty. Klastry CA charakteryzują się wyższą dostępnością, ale wymagają do działania większej ilości sprzętu, co zwiększa ich całkowity koszt.
Klastry pracy awaryjnej o wysokiej dostępności
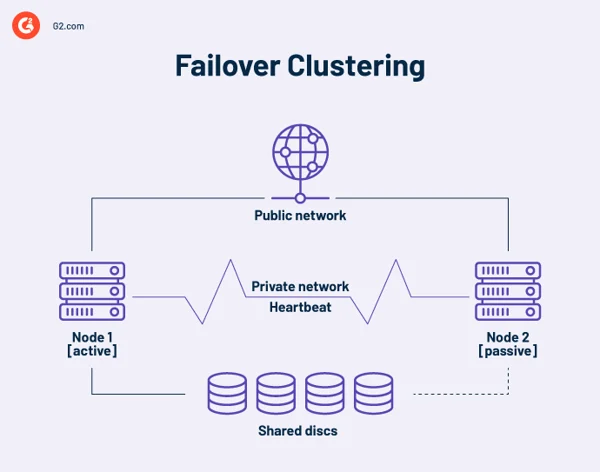
Klaster o wysokiej dostępności to zbiór niezależnych komputerów, które współdzielą zasoby i dane. Węzły klastra pracy awaryjnej mają dostęp do magazynu udostępnionego. W klastrach o wysokiej dostępności znajduje się także łącze monitorujące, umożliwiające sprawdzanie tętna i kondycji innych serwerów. Puls to prywatna sieć udostępniana tylko przez węzły w klastrze. Nie jest dostępny z zewnątrz.
W dowolnym momencie co najmniej jeden węzeł w klastrze jest aktywny, a co najmniej jeden jest uśpiony lub pasywny.
W podstawowym układzie dwóch węzłów, jeśli węzeł 1 ulegnie awarii, węzeł 2 rozpoznaje awarię poprzez połączenie pulsu i konfiguruje się jako węzeł aktywny. Oprogramowanie klastrowe na każdym węźle gwarantuje klientom połączenie z aktywnym węzłem.
Większe instalacje mogą wykorzystywać serwery dedykowane do administrowania klastrem. Serwer zarządzania klastrem zawsze wysyła sygnały pulsu, aby zidentyfikować awarię węzłów i, jeśli tak się stanie, poinformować inny węzeł, aby przejął pracę.
Niektóre narzędzia programowe do zarządzania klastrami obsługują HA dla maszyn wirtualnych, grupując maszyny i serwery w klaster. Jeśli host ulegnie awarii, inny host wznawia działanie maszyn wirtualnych.
Jako możliwy pojedynczy punkt awarii, pamięć współdzielona stanowi ryzyko. Jednak połączenie nadmiarowej macierzy niezależnych dysków 6 i 10 – czyli RAID 6 i RAID 10 – może pomóc w utrzymaniu usług nawet w przypadku awarii dwóch dysków twardych.
Zasilanie elektryczne może być kolejnym pojedynczym punktem awarii, jeśli wszystkie serwery są podłączone do tej samej sieci. Zapewnienie każdemu węzłowi własnego zasilacza awaryjnego (UPS) zapewnia ich ochronę.
Klastry pracy awaryjnej o ciągłej dostępności
W przeciwieństwie do paradygmatu HA, klaster odporny na awarie składa się z wielu komputerów, które współdzielą pojedynczą kopię systemu operacyjnego komputera. Polecenia oprogramowania wydane jednemu systemowi są również wykonywane w innych systemach.
CA nalega, aby organizacja korzystała ze sformatowanego sprzętu komputerowego i zapasowego zasilacza UPS. CA potrzebuje stale dostępnej i niemal doskonałej repliki fizycznego lub wirtualnego systemu, na którym działa usługa. Ten model redundancji jest znany jako 2N.
Systemy CA mogą kompensować szeroki zakres usterek. System odporny na uszkodzenia może wykryć awarię:
- Dysk twardy
- Jednostka przetwarzająca w komputerze
- Podsystem wejść i wyjść (I/O)
- Źródło zasilania
- Składnik sieci
Punkt awarii można szybko wykryć, a komponent lub metoda tworzenia kopii zapasowych może natychmiast zająć jego miejsce, bez zakłócania kolejnej usługi.
Oprogramowanie do klastrowania może łączyć dwa lub więcej serwerów, aby zachowywać się jak pojedynczy serwer wirtualny lub tworzyć różne alternatywne konfiguracje klastrów pracy awaryjnej urzędu certyfikacji. Na przykład, jeśli jeden z serwerów wirtualnych ulegnie awarii, pozostałe reagują, tymczasowo usuwając serwer wirtualny z kworum klastra. Następnie serwer wirtualny ponownie rozdziela obciążenie na inne serwery, dopóki serwer, który uległ awarii, nie będzie gotowy do ponownego uruchomienia.
Serwer z podwójnym sprzętem , w którym replikowane są wszystkie komponenty fizyczne, jest alternatywą dla klastrów pracy awaryjnej urzędu certyfikacji. Obliczają oddzielnie i współbieżnie na różnych platformach sprzętowych i synchronizują się za pomocą dedykowanego węzła, który monitoruje wyniki z obu serwerów fizycznych. Chociaż to rozwiązanie zapewnia ochronę, może być droższe.
Funkcje klastra pracy awaryjnej
Wiele organizacji korzysta z klastra pracy awaryjnej w przypadku aplikacji o znaczeniu krytycznym. Dzieje się tak, ponieważ poniższe cechy sprawiają, że klaster pracy awaryjnej jest istotną techniką.
- Skalowalność : ponieważ klaster pracy awaryjnej opiera się na grupie klastrów współpracujących w celu zapobiegania awariom serwera, można łatwo i łatwo skalować w razie potrzeby, dodając nowe klastry.
- Stabilność: serwery klastrowe łączą się za pomocą przewodów. Pozostałe klastry mogą nadal świadczyć usługi, nawet jeśli jeden lub więcej ulegnie awarii z powodu czynników zewnętrznych.
- Monitorowanie w czasie rzeczywistym: węzły klastra są stale monitorowane, aby mieć pewność, że działają prawidłowo. Po ponownym uruchomieniu klastra lub przeniesieniu go do innego węzła.
- Udostępniony wolumin klastra (CSV): ta funkcja zapewnia spójną i rozproszoną przestrzeń nazw, z której mogą korzystać węzły podczas pracy z magazynem współdzielonym. Zapewnienie nieprzerwanego działania aplikacji serwerowych od początku do końca ma kluczowe znaczenie.
Typy klastrów pracy awaryjnej
W ciągu ostatniej dekady nastąpił znaczny postęp w klastrach pracy awaryjnej, a wiele organizacji oferuje obecnie własną wersję rozwiązań klastrowych. W tym miejscu opisano szczegółowo niektóre z najpopularniejszych usług klastrowych.

Klastry awaryjne VMware
VMware udostępnia liczne technologie wirtualizacji dla klastrów maszyn wirtualnych. Architektura CA vSphere vMotion precyzyjnie powiela maszynę wirtualną VMware i jej sieć pomiędzy fizycznymi sieciami centrów danych.
Drugi produkt VMware vSphere HA zapewnia HA dla maszyn wirtualnych, grupując je i ich hosty w klaster w celu automatycznego przełączania awaryjnego. Dodatkowo program nie opiera się na komponentach zewnętrznych takich jak DNS, co zmniejsza ryzyko ewentualnych punktów awarii.
Klaster pracy awaryjnej serwera Windows
Metoda klastra pracy awaryjnej serwerów Windows (WSFC) ułatwia tworzenie serwerów pracy awaryjnej Hyper-V. W latach 2016-2019 strategia ta zyskała popularność wśród użytkowników systemu Microsoft Windows. WSFC umożliwia monitorowanie klastra i automatycznie oferuje niezbędny mechanizm przełączania awaryjnego. W przypadku utraty serwera WFSC przenosi klastry do osobnego węzła lub próbuje je zrestartować. Dodatkowo technologia CSV zapewnia rozproszoną przestrzeń nazw, która umożliwia kilku węzłom współdzielenie pamięci.
Serwer SQL
Ten produkt firmy Microsoft, wprowadzony wraz z SQL Server 2017, zawiera niezawodne rozwiązania HA korzystające z technologii WSFC. W tym kontekście komponenty serwera SQL są uważane za zasoby klastra WSFC. Są one dodatkowo zintegrowane z innymi zasobami zależnymi od WSFC. W rezultacie WSFC ma władzę nad identyfikowaniem i przekazywaniem poleceń ponownego uruchomienia instancji serwera SQL lub przeniesienia takich instancji do nowego węzła.
Linux Red Hata
Oprócz firmy Microsoft inni dostawcy systemów operacyjnych oferują własne rozwiązania klastrów pracy awaryjnej. Na przykład fani Red Hat Enterprise Linux (RHEL) mogą używać rozszerzenia HA i Red Hat Global File System (GFS/GFS2) do tworzenia klastrów pracy awaryjnej HA. Obsługiwane są klastry rozciągające z jednym klastrem, obejmujące wiele lokalizacji oraz klastry z wieloma lokalizacjami, odporne na awarie . Replikacja magazynu danych w sieci pamięci masowej (SAN) jest powszechnie stosowana w klastrach obejmujących wiele lokalizacji.
Zastosowania klastrów pracy awaryjnej
Ten solidny mechanizm ułatwia następujące aplikacje w czasie rzeczywistym.
Dostępność aplikacji o znaczeniu krytycznym.
Komputery do przetwarzania transakcji online (OLTP) muszą być wyposażone w systemy odporne na awarie. OLTP, który wymaga pełnej dostępności, jest używany w systemach rezerwacji linii lotniczych, elektronicznym obrocie akcjami i bankowości bankomatowej.
Wiele branż, takich jak produkcja, spedycja i handel detaliczny, wykorzystuje klastry CA lub komputery odporne na awarie do zastosowań o znaczeniu strategicznym. Przykładami są handel elektroniczny, zarządzanie zamówieniami i systemy pomiaru czasu pracy personelu.
Klastry o wysokiej dostępności są często akceptowalne w przypadku aplikacji i usług klastrowych, które wymagają czasu sprawności wynoszącego tylko pięć do dziewięciu.
Pomoc w przypadku katastrof
Odzyskiwanie po awarii również przynosi korzyści dzięki klastrowi pracy awaryjnej. Zdecydowanie zaleca się, aby serwery awaryjne były hostowane w odległych lokalizacjach, ponieważ katastrofa taka jak pożar lub powódź niszczy cały fizyczny sprzęt i oprogramowanie.
Storage Replica, technologia duplikowania woluminów między serwerami w celu odzyskiwania po awarii , jest dostępna w systemach Windows Server 2016 i 2019. Rozciągnięte przełączanie awaryjne to funkcja technologiczna, która pozwala klastrom pracy awaryjnej rozciągać się na dwie lokalizacje.
Organizacje mogą replikować dane w różnych centrach, rozszerzając klastry pracy awaryjnej. Jeśli w jednej lokalizacji wydarzy się tragedia, wszystkie dane zostaną zachowane na serwerach awaryjnych w pozostałych.
Replikacja bazy danych
Według Microsoftu usługa WSFC została po raz pierwszy uruchomiona w systemie Windows Server 2016 w celu ochrony usług „o znaczeniu krytycznym”, takich jak baza danych serwera SQL i serwer komunikacyjny Microsoft Exchange.
Do replikacji baz danych inni dostawcy dostarczają technologię klastra pracy awaryjnej. Na przykład klaster MySQL ma metodę pulsu, która umożliwia szybkie wykrywanie awarii w innych węzłach w klastrze, często w czasie krótszym niż sekunda, bez zakłócania usług dla klientów.
Bazy danych można replikować do odległych lokalizacji, korzystając z możliwości replikacji geograficznej.
Korzyści z klastrów pracy awaryjnej
Ideą klastrów pracy awaryjnej jest zapewnienie użytkownikom minimalnych zakłóceń w świadczeniu usług. Jednak inne dodatkowe zalety klastra pracy awaryjnej omówiono poniżej.
- Większa dostępność zasobów: jeśli jeden inteligentny serwer ulegnie awarii, pozostałe w klastrze przejmą ciężar. Oszczędza to kluczowy czas i informacje.
- Strategiczna alokacja zasobów: możesz dystrybuować projekty pomiędzy węzłami w dowolny sposób. Minimalizuje to obciążenie, ponieważ nie wszystkie komputery są wymagane do jednoczesnego wykonywania wszystkich projektów, co pozwala na swobodniejsze korzystanie z zasobów.
- Zwiększona moc przetwarzania: więcej maszyn, więcej mocy.
- Większa skalowalność: wraz ze wzrostem bazy użytkowników i złożoności raportów rosną także Twoje zasoby.
- Uproszczone zarządzanie: klastrowanie ułatwia obsługę znaczących lub szybko zmieniających się systemów.
Ograniczenia klastra pracy awaryjnej
Klaster pracy awaryjnej jest tak istotny, że napotyka następujące ograniczenia.
- Złożone konfiguracje: Konfiguracja klastra pracy awaryjnej w systemie Windows wymaga jednoczesnej obsługi wielu sieci i kart sieciowych. W rezultacie wdrożenie tej metody jest trudne, szczególnie dla początkujących.
- Integracja narzędzi: Klaster pracy awaryjnej systemu Windows i funkcja Hyper-V muszą być ściślej zintegrowane. Trzeba dopasować każdy z nich aby pomyślnie zakończyć klaster pracy awaryjnej.
- Interfejs internetowy: nie ma interfejsu internetowego umożliwiającego dostosowanie parametrów klastra. Aby uzyskać dostęp do funkcji menedżera klastrów, należy ręcznie zalogować się na pulpicie zdalnym.
Rozwiązania klastrowe pracy awaryjnej: zarządzani dostawcy DNS
Współpracując z systemami klastrów pracy awaryjnej, zarządzani dostawcy DNS przekierowują ruch do alternatywnych serwerów lub centrów danych podczas zdarzeń przełączania awaryjnego, zapewniając nieprzerwany dostęp do usług, dzięki czemu osiągasz wysoką dostępność i minimalizujesz przestoje.
Pięciu najlepszych zarządzanych dostawców DNS:
- DNS Cloudflare'a
- Azure DNS
- Infoblox NIOS
- ROZW. WPMU
- Menedżer DNS
* Powyżej znajduje się lista pięciu wiodących dostawców oprogramowania zarządzanych serwerów DNS z raportu G2 Grid Report z jesieni 2023 r.

Modernizacja niezawodności
Klaster pracy awaryjnej stał się niezawodną i niezbędną opcją zapewniającą wysoką dostępność i odporność na awarie w obecnych infrastrukturach IT. Zapewnia ciągłość działania pomimo awarii sprzętu lub zaplanowanej konserwacji, automatycznie rozkładając obciążenia i zasoby na wiele węzłów sieci. Technologia ta zapewnia inny sposób obsługi najważniejszego aspektu Twojej firmy – zapewnienia bezpieczeństwa i zadowolenia każdemu klientowi.
Wzmocnienie odporności systemu też nie zaszkodzi!
Zacznij od przewodnika po bezpieczeństwie DNS, aby uzyskać solidną strategię systemową.