
SEO用にMagento2robots.txtファイルを設定する方法
公開: 2021-01-21目次
SEOはストアの成功にとって重要な要素であり、適切に構成されたrobots.txtは、検索エンジンのクローラーの作業を容易にするのに少なからず貢献します。
robots.txtとは何ですか?
一言で言えば、robots.txtは、検索エンジンのクローラーにクロールできるものとできないものを指示するファイルです。 ルートディレクトリにrobots.txtがないと、ストアにアクセスする検索エンジンクローラーは可能な限りすべてをクロールします。これには、検索エンジンクローラーがクロール予算を浪費したくない重複ページや重要でないページが含まれます。 robots.txtでこれに対処できるはずです。
注:robots.txtファイルを使用してウェブページをGoogleから非表示にしないでください。 代わりに、この目的のためにnoindexメタタグを使用する必要があります。
Magento2のデフォルトのrobots.txt命令
デフォルトでは、Magentoによって生成されたrobots.txtファイルには、Webクローラーの基本的な手順がいくつか含まれています。
#Magentoが提供するデフォルトの手順 ユーザーエージェント: * 禁止:/ lib / 許可しない:/*。php$ 禁止:/ pkginfo / 許可しない:/ report / 禁止:/ var / 禁止:/ catalog / 許可しない:/ customer / 禁止:/ sendfriend / 禁止:/ review / 禁止:/ * SID =
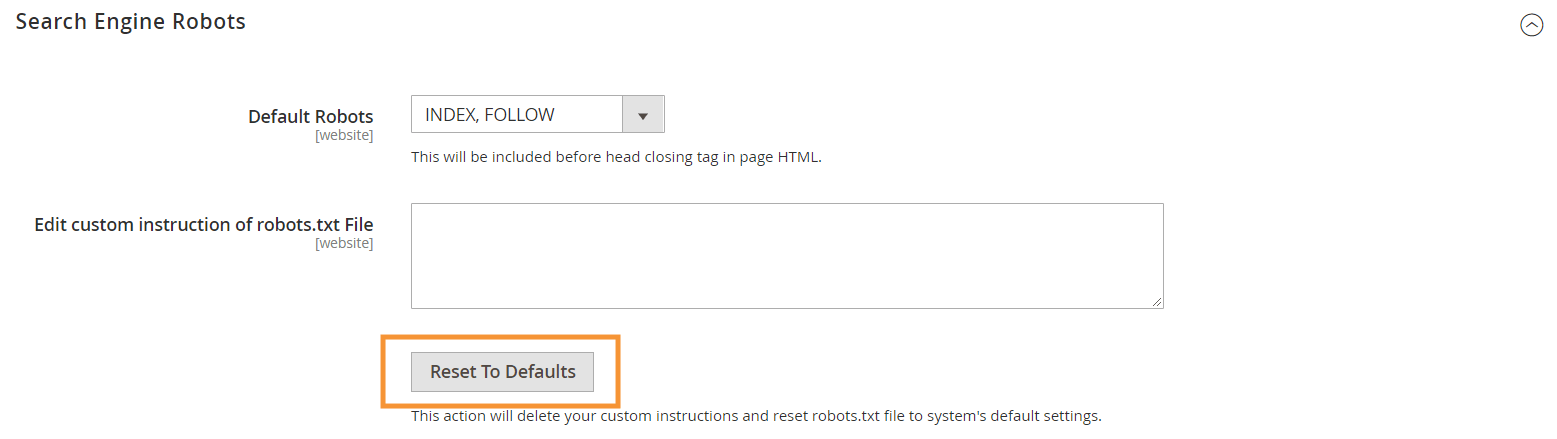
これらのデフォルトの命令を生成するには、Magentoバックエンドの検索エンジンロボット構成で[デフォルトにリセット]ボタンを押します。
Magento2でカスタムrobots.txt命令を作成する必要がある理由
Magentoが提供するデフォルトのrobots.txt命令は、システムによって内部的に使用される特定のファイルをクロールしないようにクローラーに指示するために必要ですが、ほとんどのMagentoストアには十分ではありません。
検索エンジンロボットには、Webページをクロールするための限られた量のリソースしかありません。 数千または数百万ものURLをクロールするサイト(これはあなたが思っているよりも一般的です)の場合、クロールする必要のあるコンテンツのタイプに優先順位を付け(sitemap.xmlを使用)、無関係なものを許可しないようにする必要がありますページがクロールされないようにします(robots.txtを使用)。 後者の部分は、robots.txtで重複した、無関係な、不要なページがクロールされないようにすることで実行されます。
robots.txtディレクティブの基本形式
robots.txtの手順は、技術者以外のユーザーにもわかりやすい一貫した方法で配置されています。
#ルール1 ユーザーエージェント:Googlebot 禁止:/ nogooglebot / #ルール2 ユーザーエージェント: * 許可する: / サイトマップ:https://www.example.com/sitemap.xml
-
User-agent:ルールの対象となる特定のクローラーを示します。 一般的なユーザーエージェントには、Googlebot、Googlebot-Image、Mediapartners-Google、Googlebot-Videoなどがあります。一般的なクローラーの広範なリストについては、Googleクローラーの概要を参照してください。
-
AllowおよびDisallow:指定されたクローラーがアクセスできるパスまたはアクセスできないパスを指定します。 たとえば、Allow: /は、クローラーが制限なしでサイト全体にアクセスできることを意味します。
-
Sitemap:ストアのサイトマップへのパスを示します。 サイトマップは、検索エンジンのクローラーに優先するコンテンツを通知する方法ですが、robots.txtの残りのコンテンツは、クローラーがクロールできるコンテンツとできないコンテンツをクローラーに通知します。
また、robots.txtでは、次のようなパス値にいくつかのワイルドカードを使用できます。

-
*:user-agentに入れると、アスタリスク(*)は、サイトにアクセスするすべての検索エンジンクローラー(AdsBotクローラーを除く)を指します。Allow/Disallowディレクティブで使用される場合、有効な文字のインスタンスが0個以上であることを意味します(たとえば、Allow: /example*.cssは/example.cssおよび/example12345.cssと一致します)。 -
$:URLの終わりを示します。 たとえば、Disallow: /*.php$は、 .phpで終わるすべてのファイルをブロックします #:クローラーが無視するコメントの開始を指定します。
注:sitemap.xmlパスを除いて、robots.txtのパスは常に相対的です。つまり、完全なURL(https://simicart.com/nogooglebot/など)を使用してパスウェイを指定することはできません。
Magento2でrobots.txtを構成する
Magento 2管理者でrobots.txtファイルエディタにアクセスするには、次の手順に従います。
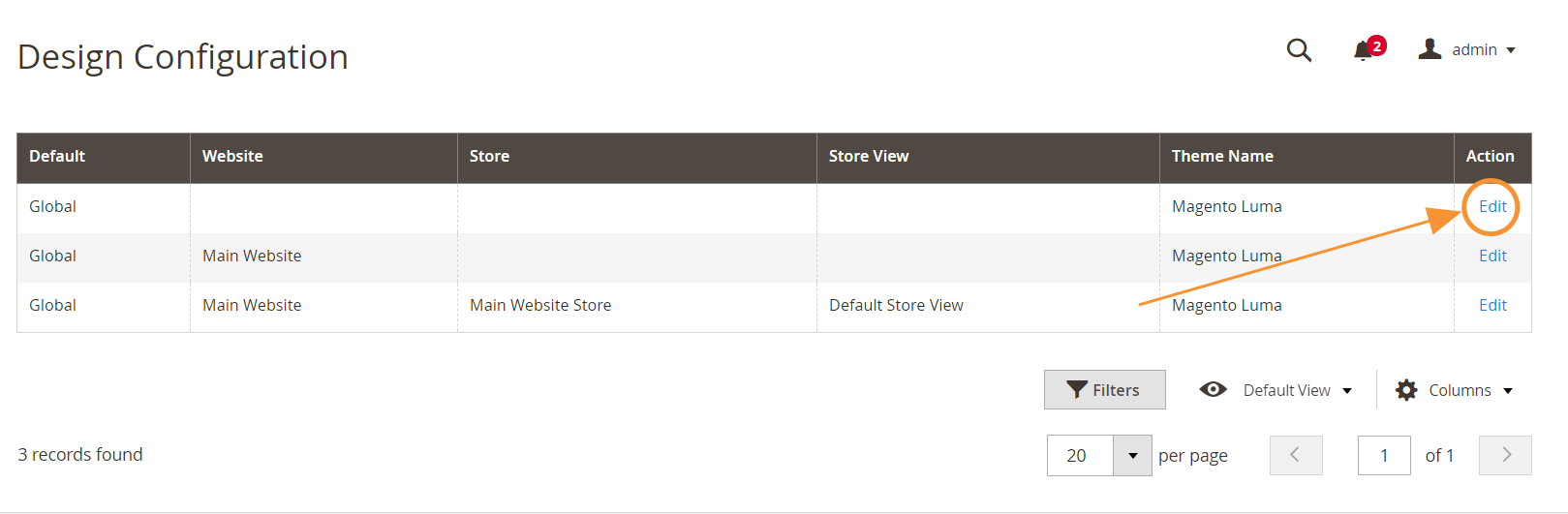
ステップ1 :[コンテンツ]>[デザイン]>[構成]に移動します
手順2 :最初の行のグローバル構成を編集する
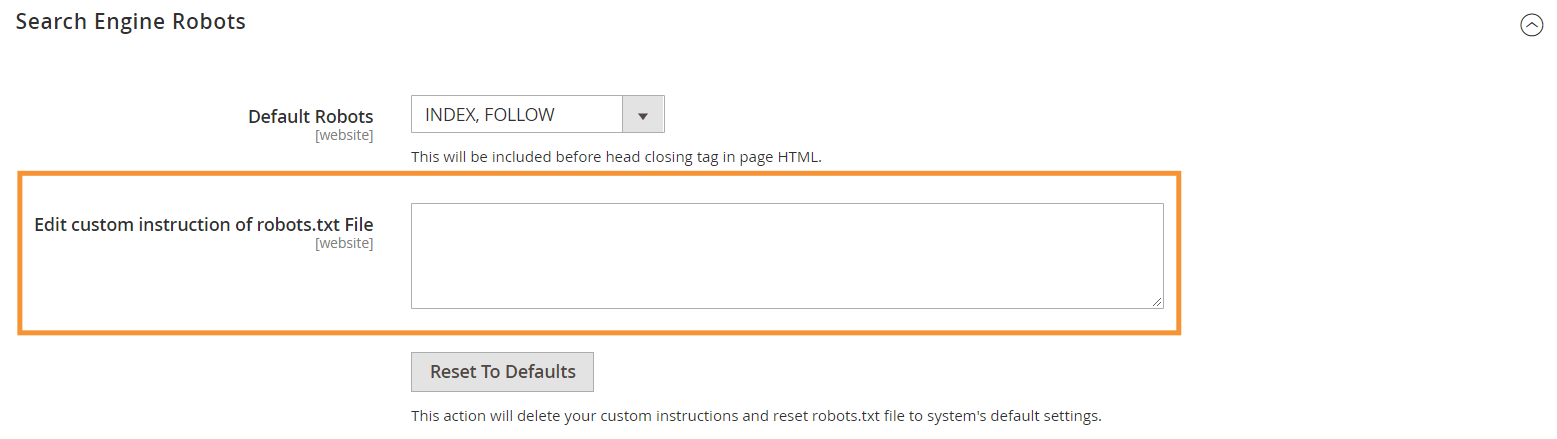
ステップ3 :[検索エンジンロボット]セクションで、カスタム手順を編集します
推奨されるrobots.txtの手順
一般的なニーズに合う推奨手順は次のとおりです。 もちろん、店舗はそれぞれ異なり、最良の結果を得るには、ルールを微調整または追加する必要がある場合があります。
ユーザーエージェント: * #デフォルトの手順: 禁止:/ lib / 許可しない:/*。php$ 禁止:/ pkginfo / 許可しない:/ report / 禁止:/ var / 禁止:/ catalog / 許可しない:/ customer / 禁止:/ sendfriend / 禁止:/ review / 禁止:/ * SID = #ルートディレクトリ内の一般的なMagentoファイルを禁止します。 禁止:/cron.php 許可しない:/cron.sh 許可しない:/ error_log 禁止:/install.php 禁止:/LICENSE.html 許可しない:/LICENSE.txt 禁止:/LICENSE_AFL.txt 禁止:/STATUS.txt #ユーザーアカウントを禁止& チェックアウトページ: 禁止:/ checkout / 禁止:/ onestepcheckout / 許可しない:/ customer / 許可しない:/ customer / account / 禁止:/ customer / account / login / #カタログ検索ページを禁止する: 禁止:/ catalogsearch / 禁止:/ catalog / product_compare / 禁止:/ catalog / category / view / 禁止:/ catalog / product / view / #URLフィルター検索を禁止する 許可しない:/ *?dir * 許可しない:/ *?dir = desc 許可しない:/ *?dir = asc 許可しない:/ *?limit = all 禁止:/ *?モード* #CMSディレクトリを禁止する: 禁止:/ app / 禁止:/ bin / 禁止:/ dev / 禁止:/ lib / 禁止:/ phpserver / 禁止:/ pub / #重複するコンテンツを禁止する: 禁止:/ tag / 禁止:/ review / 許可しない:/ *?* product_list_mode = 許可しない:/ *?* product_list_order = 許可しない:/ *?* product_list_limit = 許可しない:/ *?* product_list_dir = #サーバー設定 #サーバー上の一般的な技術ディレクトリとファイルを禁止する 禁止:/ cgi-bin / 禁止:/cleanup.php 禁止:/apc.php 許可しない:/memcache.php 禁止:/phpinfo.php #バージョン管理フォルダなどを禁止する 許可しない:/*。git 許可しない:/*。CVS 許可しない:/*。Zip$ 許可しない:/*。Svn $ 許可しない:/*。Idea $ 許可しない:/*.Sql$ 禁止:/*.Tgz$ サイトマップ:https://www.example.com/sitemap.xml
結論
robots.txtファイルの作成は、Magento SEOチェックリストの多くの手順の1つにすぎません。また、検索エンジン用にMagentoストアを適切に最適化することは、ほとんどのストア所有者にとって簡単な作業ではありません。 あなたがこれに対処したいと思わないならば、私たちはあなたのためにすべての世話をすることができます。 ここSimiCartでは、店舗に最高の結果を保証するSEOおよび速度最適化サービスを提供しています。