
Come configurare il file robots.txt di Magento 2 per SEO
Pubblicato: 2021-01-21Sommario
La SEO è un fattore importante per il successo del tuo negozio e un robots.txt correttamente configurato contribuisce non poco a rendere più facile il lavoro dei crawler dei motori di ricerca.
Cos'è robots.txt?
In poche parole, robots.txt è un file che istruisce i crawler dei motori di ricerca su ciò che possono o non possono eseguire la scansione. Senza un robots.txt nella tua directory principale, i crawler dei motori di ricerca che arrivano nel tuo negozio eseguiranno la scansione di tutto ciò che possono, e questo include pagine duplicate o non importanti su cui non vuoi che i crawler dei motori di ricerca sprechino il loro budget di scansione. Un robots.txt dovrebbe essere in grado di risolvere questo problema.
Nota : il file robots.txt non deve essere utilizzato per nascondere le tue pagine web a Google. Dovresti invece usare il meta tag noindex per questo scopo.
Istruzioni predefinite robots.txt in Magento 2
Per impostazione predefinita, il file robots.txt generato da Magento contiene solo alcune istruzioni di base per il web crawler.
# Istruzioni predefinite fornite da Magento User-agent: * Non consentire: /lib/ Non consentire: /*.php$ Non consentire: /pkginfo/ Non consentire: /report/ Non consentire: /var/ Non consentire: /catalog/ Non consentire: /cliente/ Non consentire: /sendfriend/ Non consentire: /recensione/ Non consentire: /*SID=
Per generare queste istruzioni predefinite, premi il pulsante Ripristina impostazioni predefinite nella configurazione dei robot dei motori di ricerca nel tuo back-end Magento.
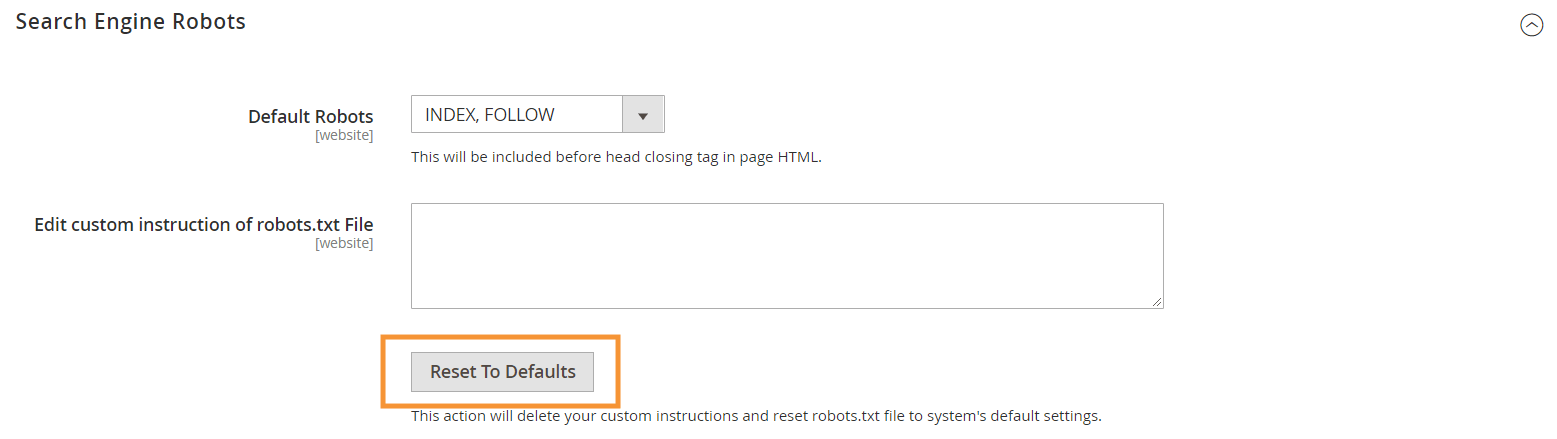
Perché è necessario creare istruzioni robots.txt personalizzate in Magento 2
Sebbene le istruzioni robots.txt predefinite fornite da Magento siano necessarie per dire ai crawler di evitare di eseguire la scansione di determinati file utilizzati internamente dal sistema, non sono sufficienti per la maggior parte dei negozi Magento.
I robot dei motori di ricerca hanno solo una quantità limitata di risorse per la scansione delle pagine web. Affinché un sito con migliaia o addirittura milioni di URL da scansionare (che è più comune di quanto si pensi), dovrai dare la priorità al tipo di contenuto che deve essere scansionato (con un sitemap.xml) e disattivare l'accesso irrilevante pagine dalla scansione (con un robots.txt). L'ultima parte viene eseguita impedendo la scansione di pagine duplicate, irrilevanti e non necessarie nel tuo robots.txt.
Formato base delle direttive robots.txt
Le istruzioni nel robots.txt sono disposte in modo coerente, amichevole per gli utenti non tecnici:
# Regola 1 User-agent: Googlebot Non consentire: /nogooglebot/ # Regola 2 User-agent: * Permettere: / Mappa del sito: https://www.example.com/sitemap.xml
-
User-agent: indica il crawler specifico a cui si riferisce la regola. Alcuni programmi utente comuni sonoGooglebot,Googlebot-Image,Mediapartners-Google,Googlebot-Videoe così via. Per un elenco completo di crawler comuni, vedere Panoramica dei crawler di Google.
-
Allowe nonDisallow: specifica i percorsi a cui i crawler designati possono o non possono accedere. Ad esempio,Allow: /significa che il crawler può accedere all'intero sito senza restrizioni.
-
Sitemapdel sito: indica il percorso della mappa del sito per il tuo negozio. La Sitemap è un modo per indicare ai crawler dei motori di ricerca a quali contenuti dare la priorità, mentre il resto del contenuto in robots.txt indica ai crawler quali contenuti possono o non possono scansionare.
Anche in robots.txt, puoi utilizzare diversi caratteri jolly per i valori di percorso come:

-
*: Quando inserito inuser-agent, l'asterisco (*) si riferisce a tutti i crawler dei motori di ricerca (ad eccezione dei crawler di AdsBot) che visitano il sito. Quando viene utilizzato nelle direttiveAllow/Disallow, significa 0 o più istanze di qualsiasi carattere valido (ad esempio,Allow: /example*.csscorrisponde a /example.css e anche /example12345.css ). -
$: indica la fine di un URL. Ad esempio,Disallow: /*.php$bloccherà tutti i file che terminano con .php -
#: indica l'inizio di un commento, che i crawler ignoreranno.
Nota : ad eccezione del percorso sitemap.xml, i percorsi in robots.txt sono sempre relativi , il che significa che non puoi utilizzare URL completi (ad es. https://simicart.com/nogooglebot/) per specificare i percorsi.
Configurazione di robots.txt in Magento 2
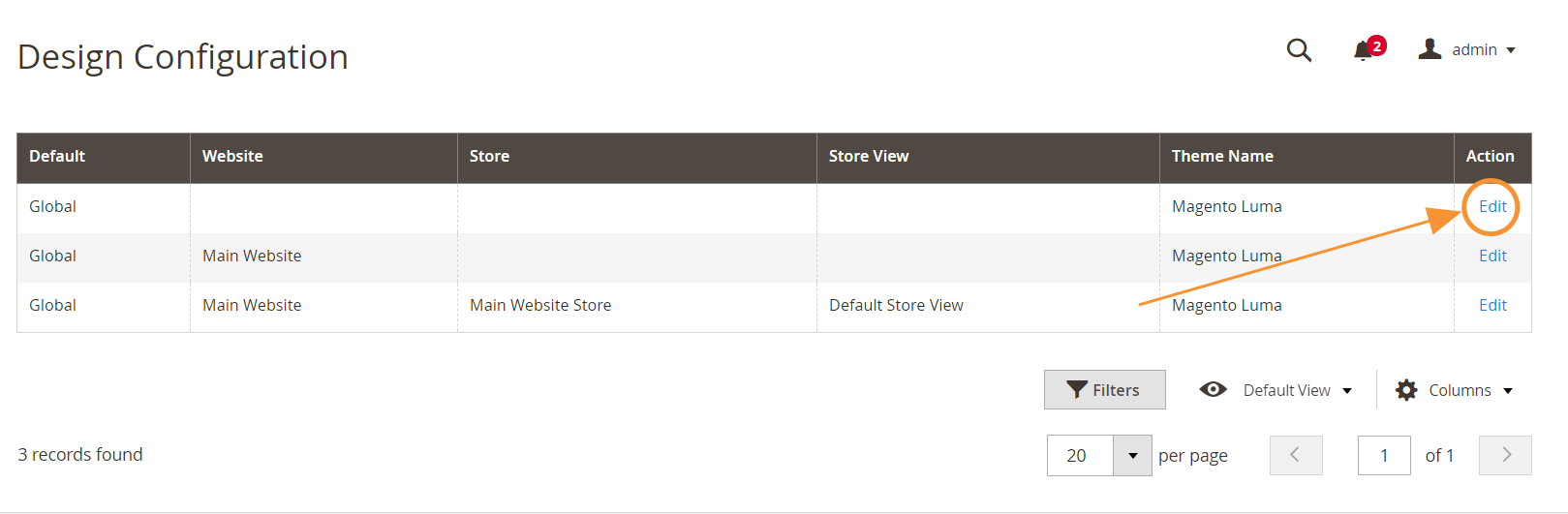
Per accedere all'editor di file robots.txt, nel tuo amministratore di Magento 2:
Passaggio 1 : vai su Contenuto > Design > Configurazione
Passaggio 2 : modifica la configurazione globale nella prima riga
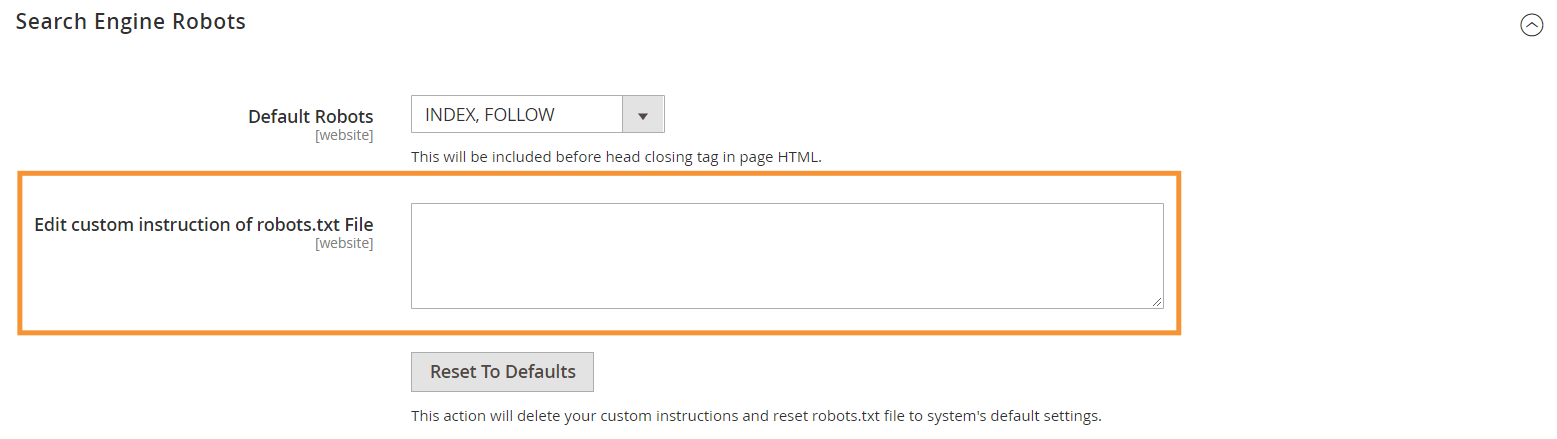
Passaggio 3 : nella sezione Robot dei motori di ricerca, modifica le istruzioni personalizzate
Istruzioni consigliate per robots.txt
Ecco le nostre istruzioni consigliate che dovrebbero soddisfare le esigenze generali. Naturalmente, ogni negozio è diverso e potrebbe essere necessario modificare o aggiungere qualche regola in più per ottenere i migliori risultati.
User-agent: * # Istruzioni predefinite: Non consentire: /lib/ Non consentire: /*.php$ Non consentire: /pkginfo/ Non consentire: /report/ Non consentire: /var/ Non consentire: /catalog/ Non consentire: /cliente/ Non consentire: /sendfriend/ Non consentire: /recensione/ Non consentire: /*SID= # Non consentire file Magento comuni nella directory principale: Non consentire: /cron.php Non consentire: /cron.sh Non consentire: /error_log Non consentire: /install.php Non consentire: /LICENZA.html Non consentire: /LICENZA.txt Non consentire: /LICENSE_AFL.txt Non consentire: /STATUS.txt # Non consentire account utente & Pagine di pagamento: Non consentire: /checkout/ Non consentire: /onestepcheckout/ Non consentire: /cliente/ Non consentire: /cliente/account/ Non consentire: /cliente/account/login/ # Non consentire pagine di ricerca nel catalogo: Non consentire: /catalogsearch/ Non consentire: /catalog/product_compare/ Non consentire: /catalog/categoria/visualizza/ Non consentire: /catalog/product/view/ # Non consentire ricerche con filtro URL Non consentire: /*?dir* Non consentire: /*?dir=desc Non consentire: /*?dir=asc Non consentire: /*?limit=tutto Non consentire: /*?modalità* # Non consentire directory CMS: Non consentire: /app/ Non consentire: /bin/ Non consentire: /dev/ Non consentire: /lib/ Non consentire: /phpserver/ Non consentire: /pub/ # Non consentire contenuto duplicato: Non consentire: /tag/ Non consentire: /recensione/ Non consentire: /*?*product_list_mode= Non consentire: /*?*product_list_order= Non consentire: /*?*product_list_limit= Non consentire: /*?*product_list_dir= # Impostazioni del server # Non consentire directory e file tecnici generali su un server Non consentire: /cgi-bin/ Non consentire: /cleanup.php Non consentire: /apc.php Non consentire: /memcache.php Non consentire: /phpinfo.php # Non consentire cartelle di controllo della versione e altro Non consentire: /*.git Non consentire: /*.CVS Non consentire: /*.Zip$ Non consentire: /*.Svn$ Non consentire: /*.Idea$ Non consentire: /*.Sql$ Non consentire: /*.Tgz$ Mappa del sito: https://www.example.com/sitemap.xml
Conclusione
La creazione di un file robots.txt è solo uno dei tanti passaggi nell'elenco di controllo SEO di Magento e ottimizzare correttamente un negozio Magento per i motori di ricerca non è sicuramente un compito facile per la maggior parte dei proprietari di negozi. Se non ti senti a voler affrontare questo, possiamo occuparci di tutto noi per te. Qui a SimiCart, forniamo servizi di SEO e ottimizzazione della velocità che garantiscono i migliori risultati per il tuo negozio.