
Cos'è il clustering di failover? Come funziona + Soluzioni
Pubblicato: 2023-09-22Le aziende che necessitano di transazioni online non possono permettersi guasti ai server. Di conseguenza, queste aziende cercano modi per creare una procedura di sicurezza che mantenga i propri dati al sicuro anche se il server crolla. Uno di questi metodi è il clustering di failover.
Il clustering di failover può essere gestito da soluzioni di provider DNS (Domain Name System) gestiti; tuttavia, comprenderne il meccanismo e le caratteristiche principali può aiutare a limitare eventuali problemi di failover.
Cos'è il clustering di failover?
Il clustering di failover opera su un gruppo di server di computer per garantire alta disponibilità (HA) o disponibilità continua (CA) per le applicazioni server. Questa tecnologia garantisce che in caso di guasto di un server o nodo, un altro nodo del cluster sia pronto a sostenere il carico di lavoro senza interruzioni.
Questo approccio mantiene i carichi di lavoro del server scalabili e disponibili. Molti dei principali programmi server, come Microsoft Exchange , Microsoft SQL Server e Hyper-V , si affidano al clustering di failover per proteggersi.
Alcuni cluster di failover utilizzano server fisici, mentre altri utilizzano macchine virtuali (VM) . Ognuno seleziona il tipo di cluster di cui ha bisogno in base ai requisiti della propria applicazione server.
Un cluster è costituito da due o più nodi che scambiano dati e software da elaborare tramite cavi fisici o una rete sicura specializzata. La tecnologia di clustering di diversi tipi può essere utilizzata per il bilanciamento del carico, l'archiviazione e l'elaborazione simultanea o parallela. In alcuni casi, i cluster di failover vengono combinati con tecnologie di clustering aggiuntive.
La funzione principale di un cluster di failover è fornire CA o HA per applicazioni e servizi. I cluster CA, noti anche come cluster FT (failure tolerant), consentono agli utenti finali di continuare a utilizzare applicazioni e servizi anche in caso di guasto di un server. Potrebbe verificarsi una breve interruzione del servizio causata dai cluster HA, ma il sistema può essere ripristinato senza perdita di dati e con tempi di inattività minimi.
Perché il clustering di failover è importante?
Con il clustering di failover, puoi riparare i nodi inattivi senza arrestare il database, evitando problemi di inattività e riparando rapidamente i server danneggiati. Inoltre, in caso di guasto hardware, questa tecnica termina il database per proteggere i nodi attivi.
Il clustering di failover automatizza inoltre il ripristino dei dati in caso di guasto. Ciò riduce la dipendenza dal personale informatico (IT) e consente il ripristino rapido dei server. Fornisce inoltre un'eccellente disponibilità del cluster SQL (Structured Query Language) con tempi di inattività minimi. La funzionalità di failover automatizzato del clustering di failover preserva la funzionalità del database, anche in caso di guasto dell'hardware.
Come funzionano i cluster di failover?
Il clustering di failover è costituito da due processi fondamentali, HA e CA, per le applicazioni server.
Mentre i cluster di failover CA cercano di raggiungere una disponibilità del 100%, i cluster HA puntano al 99,999%, comunemente noto come cinque nove. Questo tempo di inattività ammonta a non più di 5,26 minuti ogni anno. I cluster CA hanno una disponibilità maggiore ma richiedono più hardware per funzionare, aumentandone il costo complessivo.
Cluster di failover ad alta disponibilità
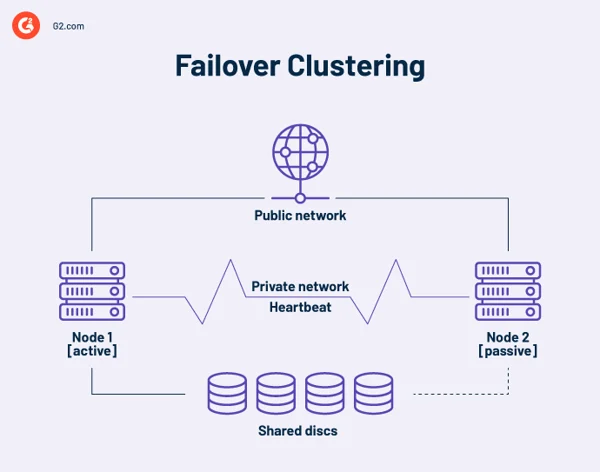
Un cluster ad alta disponibilità è una raccolta di computer indipendenti che condividono risorse e dati. I nodi di un cluster di failover hanno accesso all'archiviazione condivisa. Nei cluster ad alta disponibilità è incluso anche un collegamento di monitoraggio per controllare il battito cardiaco o l'integrità degli altri server. Un heartbeat è una rete privata condivisa solo dai nodi del cluster. Non è accessibile dall'esterno.
In qualsiasi momento, almeno un nodo di un cluster è attivo e almeno uno è dormiente o passivo.
In una disposizione di base a due nodi, se il Nodo 1 fallisce, il Nodo 2 riconosce il guasto tramite la connessione heartbeat e si configura come nodo attivo. Il software di clustering su ciascun nodo garantisce che i client si connettano a un nodo attivo.
Le installazioni più grandi possono utilizzare server dedicati per amministrare il cluster. Un server di gestione del cluster invia sempre segnali heartbeat per identificare eventuali nodi in errore e, in tal caso, per indicare a un altro nodo di intraprendere il lavoro.
Alcuni strumenti software di gestione dei cluster gestiscono l'alta disponibilità per le macchine virtuali raggruppando macchine e server in un cluster. Se un host si guasta, un host diverso ripristina le VM.
Come possibile singolo punto di errore, l'archiviazione condivisa rappresenta un rischio. Tuttavia, la combinazione di un array ridondante di dischi indipendenti 6 e 10, ovvero RAID 6 e RAID 10, può aiutare a mantenere il servizio anche in caso di guasto di due dischi rigidi.
L’energia elettrica potrebbe essere un altro singolo punto di guasto se tutti i server fossero collegati alla stessa rete. Fornire a ciascun nodo il proprio gruppo di continuità (UPS) li mantiene protetti.
Cluster di failover a disponibilità continua
A differenza del paradigma HA, un cluster con tolleranza agli errori comprende numerosi computer che condividono una singola copia del sistema operativo (OS) di un computer. I comandi software impartiti a un sistema vengono eseguiti anche sugli altri sistemi.
CA insiste affinché l'organizzazione utilizzi apparecchiature informatiche formattate e un UPS di backup. CA necessita di una replica costantemente accessibile e quasi perfetta del sistema fisico o virtuale che esegue il servizio. Questo modello di ridondanza è noto come 2N.
I sistemi CA possono compensare un'ampia gamma di guasti. Un sistema tollerante ai guasti può identificare un malfunzionamento di:
- Un disco rigido
- Un'unità di elaborazione in un computer
- Un sottosistema per input e output (I/O)
- Una fonte di energia
- Un componente di una rete
Il punto di errore può essere scoperto tempestivamente e un componente o metodo di backup può sostituirlo immediatamente senza interrompere il servizio successivo.
Il software di clustering può connettere due o più server in modo che si comportino come un singolo server virtuale o costruire varie configurazioni alternative di cluster di failover CA. Ad esempio, se uno dei server virtuali si guasta, gli altri rispondono rimuovendo temporaneamente il server virtuale dal quorum del cluster. Il server virtuale ridistribuisce quindi il carico sugli altri server finché il server in crash non è pronto per il riavvio.
Un doppio server hardware con tutti i componenti fisici replicati è un'alternativa ai cluster di failover CA. Elaborano separatamente e contemporaneamente su varie piattaforme hardware e si sincronizzano utilizzando un nodo dedicato che monitora i risultati da entrambi i server fisici. Sebbene questa soluzione offra protezione, potrebbe essere più costosa.
Funzionalità di clustering di failover
Molte organizzazioni utilizzano il clustering di failover per applicazioni mission-critical. Questo perché le seguenti caratteristiche rendono il clustering di failover una tecnica significativa.
- Scalabilità : poiché il clustering di failover si basa su un gruppo di cluster che collaborano per prevenire guasti al server, puoi scalarlo facilmente e rapidamente in base alle necessità aggiungendo nuovi cluster.
- Stabilità: i server in cluster si connettono tramite cavi. I restanti cluster possono comunque offrire il servizio anche se uno o più falliscono a causa di fattori esterni.
- Monitoraggio in tempo reale: i nodi del cluster vengono costantemente monitorati per assicurarsi che funzionino correttamente. Quando un cluster viene riavviato o trasferito su un altro nodo.
- Volume condiviso cluster (CSV): questa funzionalità fornisce uno spazio dei nomi coerente e distribuito che i nodi possono utilizzare mentre lavorano con l'archiviazione condivisa. È fondamentale mantenere le applicazioni server in esecuzione senza interruzioni dall'inizio alla fine.
Tipi di cluster di failover
Negli ultimi dieci anni si sono verificati progressi significativi nel clustering di failover e molte organizzazioni ora offrono la propria versione di soluzioni di clustering. Alcuni dei servizi cluster più comuni sono descritti in dettaglio qui.

Cluster di failover VMware
VMware fornisce numerose tecnologie di virtualizzazione per i cluster VM. L'architettura CA di vSphere vMotion duplica esattamente una macchina virtuale VMware e la sua rete tra reti di data center fisici.
VMware vSphere HA, un secondo prodotto, fornisce HA per le VM raggruppandole e i relativi host in un cluster per il failover automatizzato. Inoltre, il programma non si basa su componenti esterni come DNS, il che riduce i possibili punti di errore.
Cluster di failover del server Windows
Il metodo WSFC (server failover cluster) di Windows favorisce la creazione di server di failover Hyper-V. Tra il 2016 e il 2019, questa strategia è diventata popolare tra gli utenti di Microsoft Windows. WSFC consente il monitoraggio del cluster e offre automaticamente il meccanismo di failover necessario. In caso di perdita del server, WFSC sposta i cluster su un nodo separato o tenta di riavviarli. Inoltre, la sua tecnologia CSV fornisce uno spazio dei nomi distribuito che consente a diversi nodi di condividere la memoria.
Server SQL
Questo prodotto Microsoft, introdotto con SQL Server 2017, dispone di robuste soluzioni HA che utilizzano la tecnologia WSFC. I componenti del server SQL sono considerati risorse del cluster WSFC in questo contesto. Sono ulteriormente integrati con altre risorse dipendenti da WSFC. Di conseguenza, WSFC ha l'autorità di identificare e comunicare gli ordini per riavviare un'istanza del server SQL o spostare istanze come quelle su un nuovo nodo.
Red Hat Linux
Oltre a Microsoft, altri fornitori di sistemi operativi offrono le proprie soluzioni di cluster di failover. Ad esempio, i fan di Red Hat Enterprise Linux (RHEL) possono utilizzare l'estensione HA e Red Hat Global File System (GFS/GFS2) per stabilire cluster di failover HA. Sono supportati cluster estesi a cluster singolo che si estendono su molte posizioni e cluster multisito con tolleranza ai disastri . La replica dell'archiviazione dei dati sulla rete SAN (Storage Area Network) viene comunemente utilizzata nei cluster multisito.
Applicazioni del clustering di failover
Questo robusto meccanismo facilita le seguenti applicazioni in tempo reale.
Disponibilità di applicazioni mission-critical.
I computer OLTP (Online Transaction Processing) devono disporre di sistemi a prova di errore. OLTP, che richiede disponibilità completa, viene utilizzato per i sistemi di prenotazione aerea, il commercio elettronico di azioni e i servizi bancari ATM.
Molti settori, come quello manifatturiero, delle spedizioni e della vendita al dettaglio, utilizzano cluster CA o computer resistenti ai guasti per applicazioni mission-important. L'e-commerce, la gestione degli ordini e i sistemi di gestione del tempo del personale contano come esempi.
I cluster ad alta disponibilità sono spesso accettabili per il clustering di applicazioni e servizi che richiedono solo un tempo di attività di cinque nove.
In caso di catastrofe
Anche il ripristino di emergenza trae vantaggio dal clustering di failover. Si consiglia vivamente di ospitare i server di failover in siti remoti poiché una calamità come un incendio o un'alluvione distrugge tutto l'hardware e il software fisico.
Replica archiviazione, una tecnologia che duplica i volumi tra server per il ripristino di emergenza , è inclusa in Windows Server 2016 e 2019. Il failover esteso è una funzionalità tecnologica che consente ai cluster di failover di estendersi su due posizioni.
Le organizzazioni possono replicare i dati su vari centri estendendo i cluster di failover. Se una tragedia colpisce un luogo, tutti i dati vengono conservati sui server di failover negli altri.
Replica di un database
Secondo Microsoft, il WSFC è stato lanciato per la prima volta in Windows Server 2016 per salvaguardare i servizi “mission-critical”, come il database del server SQL e il server di comunicazione Microsoft Exchange.
Per la replica del database , altri fornitori forniscono la tecnologia cluster di failover. Ad esempio, MySQL Cluster dispone di un metodo heartbeat che consente il rilevamento rapido degli errori su altri nodi del cluster, spesso in meno di un secondo, senza interruzioni del servizio ai client.
I database possono essere replicati in siti lontani utilizzando la funzionalità di replica geografica.
Vantaggi dei cluster di failover
L'idea dei cluster di failover è garantire che gli utenti subiscano interruzioni minime del servizio. Tuttavia, altri vantaggi aggiuntivi del clustering di failover vengono discussi di seguito.
- Maggiore disponibilità delle risorse: se un server intelligente si guasta, gli altri nel cluster si fanno carico del carico. Ciò consente di risparmiare tempo e informazioni cruciali.
- Allocazione strategica delle risorse: puoi distribuire i progetti tra i nodi nel modo che preferisci. Ciò riduce al minimo il sovraccarico poiché non tutti i computer sono tenuti a eseguire tutti i progetti contemporaneamente, offrendoti la possibilità di utilizzare le tue risorse più liberamente.
- Maggiore potenza di elaborazione: più macchine, più potenza.
- Maggiore scalabilità: man mano che la base utenti e la complessità dei report si espandono, aumentano anche le tue risorse.
- Gestione semplificata: il clustering semplifica la gestione di sistemi significativi o in rapida evoluzione.
Limitazioni del clustering di failover
Per quanto significativo sia il clustering di failover, si scontra con le seguenti limitazioni.
- Configurazioni complesse: la configurazione del clustering di failover per Windows richiede la gestione di più reti e schede di rete contemporaneamente. Di conseguenza, l’implementazione di questo metodo è difficile, soprattutto per i principianti.
- Integrazioni degli strumenti: il clustering di failover di Windows e Hyper-V devono essere integrati più strettamente. Devi regolare ciascuno di essi per completare correttamente il clustering di failover.
- Interfaccia Web: non esiste un'interfaccia Web per regolare i parametri del cluster. Per accedere alla funzionalità di gestione cluster, è necessario accedere manualmente a un desktop remoto.
Soluzioni di failover clustering: provider DNS gestiti
Lavorando insieme ai sistemi di clustering di failover, i provider DNS gestiti reindirizzano il traffico verso server o data center alternativi durante gli eventi di failover, garantendo un accesso ininterrotto ai servizi in modo da ottenere un'elevata disponibilità e ridurre al minimo i tempi di inattività.
I cinque principali provider DNS gestiti:
- DNS di Cloudflare
- DNS di Azure
- InfobloxNIOS
- WPMU DEV
- Gestore DNS
* Sopra sono riportati i cinque principali fornitori di software DNS gestiti dal Grid Report dell'autunno 2023 di G2.

Modernizzare l'affidabilità
Il clustering di failover è emerso come un'opzione affidabile ed essenziale per l'elevata disponibilità e la tolleranza ai guasti all'interno delle attuali infrastrutture IT. Garantisce operazioni continue nonostante guasti hardware o manutenzione programmata distribuendo automaticamente carichi di lavoro e risorse su numerosi nodi della rete. Questa tecnologia ti offre un altro modo per gestire l'aspetto più importante della tua attività: rendere l'esperienza di ogni cliente sicura e felice.
Anche rafforzare la resilienza del tuo sistema non fa male!
Inizia con una guida alla sicurezza DNS per una solida strategia di sistema.