
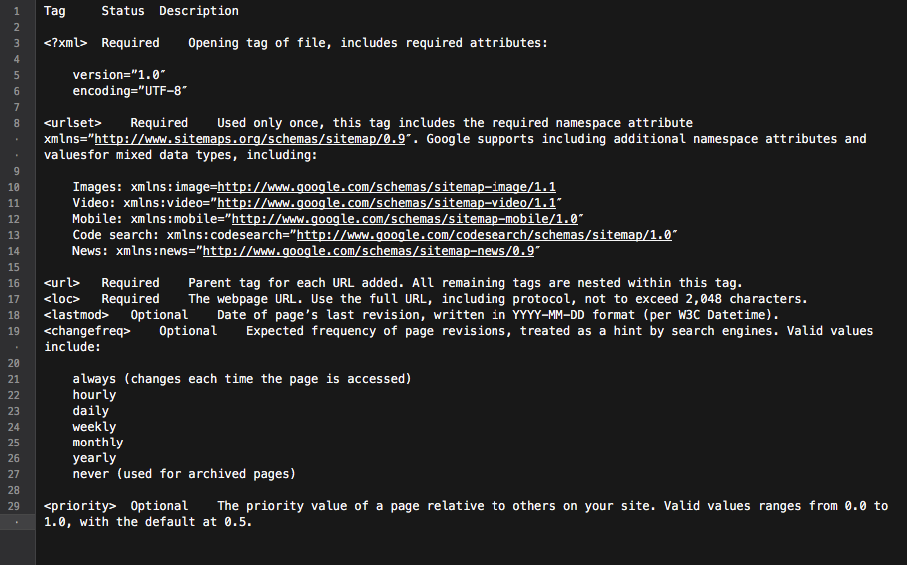
Sfatare 3 miti comuni dietro la scansione del sito, l'indicizzazione e le Sitemap XML
Pubblicato: 2018-03-07Molti di noi credono erroneamente che l'avvio di un sito Web dotato di una mappa del sito XML comporterà automaticamente la scansione e l'indicizzazione di tutte le sue pagine.
A questo proposito, si accumulano alcuni miti e idee sbagliate. I più comuni sono:
- Google esegue automaticamente la scansione di tutti i siti e lo fa velocemente.
- Durante la scansione di un sito Web, Google segue tutti i collegamenti e visita tutte le sue pagine e le include tutte nell'Indice immediatamente.
- L'aggiunta di una mappa del sito XML è il modo migliore per eseguire la scansione e l'indicizzazione di tutte le pagine del sito.
Purtroppo, inserire il tuo sito web nell'indice di Google è un compito un po' più complicato. Continua a leggere per avere un'idea migliore di come funziona il processo di scansione e indicizzazione e quale ruolo gioca una mappa del sito XML al suo interno.
Prima di scendere a sfatare i miti sopra menzionati, impariamo alcune nozioni SEO essenziali:
Il crawling è un'attività implementata dai motori di ricerca per tracciare e raccogliere URL da tutto il Web.
L'indicizzazione è il processo che segue la scansione. Fondamentalmente, si tratta di analizzare e archiviare dati Web che vengono successivamente utilizzati per fornire risultati per le query dei motori di ricerca. L'indice dei motori di ricerca è il luogo in cui tutti i dati Web raccolti vengono archiviati per un ulteriore utilizzo.
Il Crawl Rank è il valore che Google assegna al tuo sito e alle sue pagine. Non è ancora noto come questa metrica venga calcolata dal motore di ricerca. Google ha confermato più volte che la frequenza di indicizzazione non è correlata al ranking, quindi non esiste una correlazione diretta tra l'autorità di ranking di un sito Web e il suo crawl rank.
I siti Web di notizie, i siti con contenuti di valore e i siti aggiornati regolarmente hanno maggiori possibilità di essere scansionati regolarmente.
Crawl Budget è una quantità di risorse di scansione che il motore di ricerca assegna a un sito web. Di solito, Google calcola questo importo in base al Crawl Rank del tuo sito.
La profondità di scansione è la misura in cui Google esegue il drill down di un livello di sito Web durante l'esplorazione.
La priorità di scansione è un numero ordinale assegnato a una pagina del sito che ne indica l'importanza in relazione alla scansione.
Ora, conoscendo tutte le basi del processo, sfatiamo quei 3 miti dietro le mappe dei siti XML, la scansione e l'indicizzazione!
Sommario
- Mito 1. Google esegue automaticamente la scansione di tutti i siti e lo fa velocemente.
- Asporto
- Mito 2. L'aggiunta di una mappa del sito XML è il modo migliore per eseguire la scansione e l'indicizzazione di tutte le pagine del sito.
- Asporto
- Mito 3. Una mappa del sito XML può risolvere tutti i problemi di scansione e indicizzazione.
- Asporto
Mito 1. Google esegue automaticamente la scansione di tutti i siti e lo fa velocemente.
Google afferma che quando si tratta di raccogliere dati Web, è agile e flessibile.
Ma a dire il vero, perché al momento ci sono trilioni di pagine sul Web, tecnicamente, il motore di ricerca non può scansionarle tutte rapidamente.
Selezione di siti Web a cui allocare il budget di scansione
L'algoritmo intelligente di Google (aka Crawl Budget) distribuisce le risorse del motore di ricerca e decide quali siti vale la pena scansionare e quali no.
Di solito, Google dà la priorità ai siti Web affidabili che corrispondono ai requisiti stabiliti e fungono da base per definire in che modo gli altri siti sono all'altezza.
Quindi, se hai un sito Web appena sfornato o un sito Web con contenuti raschiati, duplicati o sottili, le possibilità che venga scansionato correttamente sono piuttosto ridotte.
I fattori importanti che possono anche influenzare l'allocazione del crawling budget sono:
- dimensione del sito web,
- il suo stato generale (questo insieme di metriche è determinato dal numero di errori che potresti avere su ciascuna pagina),
- e il numero di collegamenti interni e in entrata.
Per aumentare le tue possibilità di ottenere il budget per la scansione, assicurati che il tuo sito soddisfi tutti i requisiti di Google sopra menzionati, oltre a ottimizzarne l'efficienza di scansione (consulta la sezione successiva dell'articolo).
Prevedere il programma di scansione
Google non annuncia i suoi piani per la scansione degli URL Web. Inoltre, è difficile indovinare la periodicità con cui il motore di ricerca visita alcuni siti.
Può essere che per un sito possa eseguire scansioni almeno una volta al giorno, mentre per altri venga visitato una volta al mese o anche meno frequentemente.
- La periodicità delle scansioni dipende da:
- la qualità dei contenuti del sito,
- la novità e la pertinenza delle informazioni fornite da un sito web,
- e su quanto siano importanti o popolari il motore di ricerca ritiene che gli URL dei siti siano.
Tenendo conto di questi fattori, puoi provare a prevedere la frequenza con cui Google potrebbe visitare il tuo sito web.
Il ruolo dei link esterni/interni e delle mappe del sito XML
Come percorsi, i Googlebot utilizzano collegamenti che collegano le pagine del sito e il sito Web tra loro. Pertanto, il motore di ricerca raggiunge trilioni di pagine interconnesse che esistono sul Web.
Il motore di ricerca può avviare la scansione del tuo sito Web da qualsiasi pagina, non necessariamente da quella principale. La selezione del punto di ingresso della scansione dipende dall'origine di un collegamento in entrata. Supponiamo che alcune delle pagine dei tuoi prodotti abbiano molti collegamenti provenienti da vari siti Web. Google collega i punti e visita pagine così popolari nel primo turno.
Una mappa del sito XML è un ottimo strumento per costruire una struttura del sito ben congegnata. Inoltre, può rendere il processo di scansione del sito più mirato e intelligente.
Fondamentalmente, la mappa del sito è un hub con tutti i collegamenti al sito. Ogni collegamento incluso in esso può essere dotato di alcune informazioni extra: la data dell'ultimo aggiornamento, la frequenza di aggiornamento, la sua relazione con altri URL del sito, ecc.
 Tutto ciò fornisce a Googlebots una roadmap dettagliata per la scansione del sito Web e rende la scansione più informata. Inoltre, tutti i principali motori di ricerca danno priorità agli URL che sono elencati in una mappa del sito.
Tutto ciò fornisce a Googlebots una roadmap dettagliata per la scansione del sito Web e rende la scansione più informata. Inoltre, tutti i principali motori di ricerca danno priorità agli URL che sono elencati in una mappa del sito.
Riassumendo, per portare le pagine del tuo sito sul radar di Googlebot, devi creare un sito Web con ottimi contenuti e ottimizzare la sua struttura di collegamento interna.
Asporto
• Google non esegue automaticamente la scansione di tutti i tuoi siti web.
• La periodicità della scansione del sito dipende dall'importanza o dalla popolarità del sito e delle sue pagine.
• L'aggiornamento dei contenuti fa sì che Google visiti un sito Web più frequentemente.
• È improbabile che i siti Web che non corrispondono ai requisiti del motore di ricerca vengano scansionati correttamente.
• I siti Web e le pagine del sito che non dispongono di collegamenti interni/esterni vengono generalmente ignorati dai bot dei motori di ricerca.
• L'aggiunta di una mappa del sito XML può migliorare il processo di scansione del sito Web e renderlo più intelligente.
Mito 2. L'aggiunta di una mappa del sito XML è il modo migliore per eseguire la scansione e l'indicizzazione di tutte le pagine del sito.
Ogni proprietario di un sito web desidera che Googlebot visiti tutte le pagine importanti del sito (tranne quelle nascoste dall'indicizzazione), oltre a esplorare istantaneamente contenuti nuovi e aggiornati.
Tuttavia, il motore di ricerca ha una propria visione delle priorità di scansione del sito.
Quando si tratta di controllare un sito web e il suo contenuto, Google utilizza una serie di algoritmi chiamati crawl budget. Fondamentalmente, consente al motore di ricerca di scansionare le pagine del sito, utilizzando saggiamente le proprie risorse.
Controllo del budget per la scansione di un sito web
È abbastanza facile capire come viene eseguita la scansione del tuo sito e se hai problemi di budget di scansione.
Hai solo bisogno di:
- contare il numero di pagine del tuo sito e della tua mappa del sito XML,
- visita Google Search Console, passa alla sezione Scansione -> Statistiche di scansione e controlla quante pagine vengono scansionate ogni giorno sul tuo sito,
- dividi il numero totale delle pagine del tuo sito per il numero di pagine scansionate al giorno.
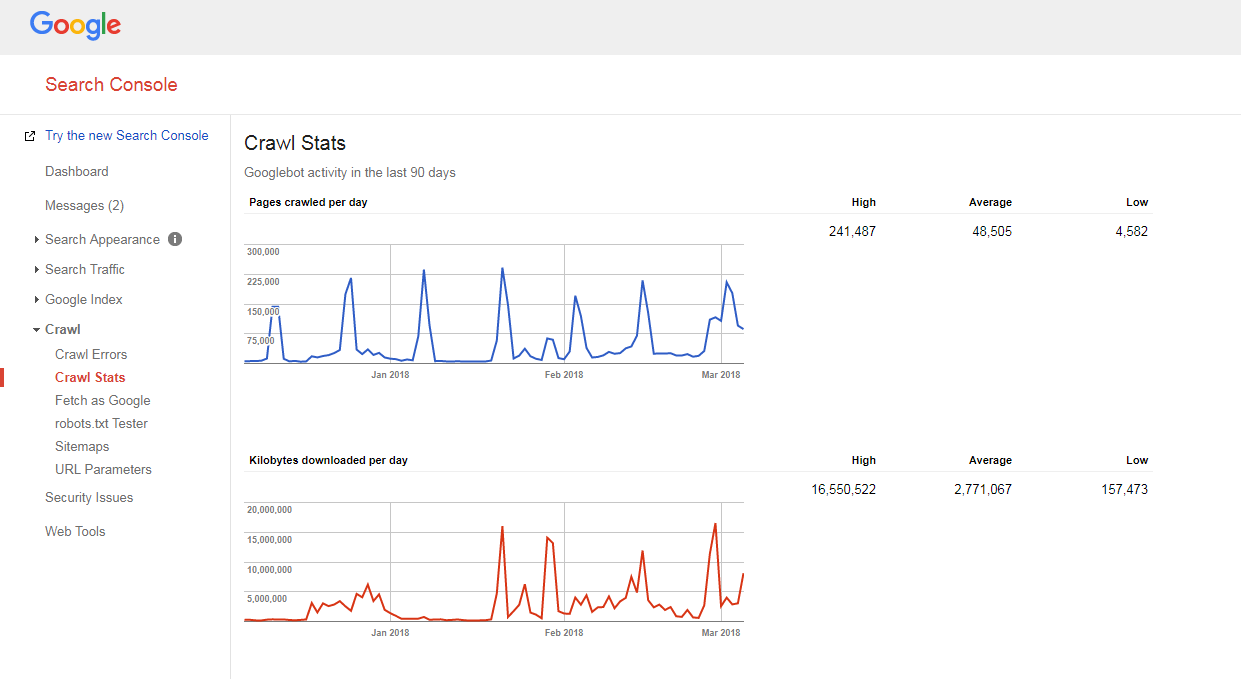 Se il numero che hai è maggiore di 10 (ci sono 10 volte più pagine sul tuo sito rispetto a quelle che Google scansiona quotidianamente), abbiamo una brutta notizia per te: il tuo sito web ha problemi di scansione.
Se il numero che hai è maggiore di 10 (ci sono 10 volte più pagine sul tuo sito rispetto a quelle che Google scansiona quotidianamente), abbiamo una brutta notizia per te: il tuo sito web ha problemi di scansione.
Ma prima di imparare a risolverli, devi capire un'altra nozione, cioè...
Profondità di scansione
La profondità della scansione è la misura in cui Google continua a esplorare un sito Web fino a un certo livello.
Generalmente, la home page è considerata di livello 1, una pagina a 1 clic di distanza è di livello 2, ecc.
Le pagine di livello profondo hanno un Pagerank più basso (o non lo hanno affatto) e hanno meno probabilità di essere scansionate da Googlebot. Di solito, il motore di ricerca non scava più in profondità del livello 4.
Nello scenario ideale, una pagina specifica dovrebbe essere a 1-4 clic dalla home page o dalle categorie principali del sito. Più lungo è il percorso verso quella pagina, più risorse i motori di ricerca devono allocare per raggiungerla.
Se si trova su un sito Web, Google stima che il percorso sia troppo lungo, interrompe ulteriormente la scansione.
Ottimizzazione della profondità di scansione e del budget
Per evitare che Googlebot rallenti, ottimizzare il budget e la profondità della scansione del tuo sito web, devi:
- correggere tutti gli errori di pagina 404, JS e altri;
Una quantità eccessiva di errori di pagina può rallentare notevolmente la velocità del crawler di Google. Per trovare tutti gli errori principali del sito, accedi al tuo pannello Strumenti per i Webmaster di Google (Bing, Yandex) e segui tutte le istruzioni fornite qui.

- ottimizzare l'impaginazione;
Nel caso in cui tu abbia elenchi di impaginazione troppo lunghi o il tuo schema di impaginazione non consenta di fare clic oltre un paio di pagine nell'elenco, è probabile che il crawler del motore di ricerca smetta di scavare in una tale pila di pagine.
Inoltre, se ci sono pochi elementi per tale pagina, può essere considerato come contenuto sottile e non verrà scansionato.
- controllare i filtri di navigazione;
Alcuni schemi di navigazione possono essere dotati di più filtri che generano nuove pagine (ad es. pagine filtrate da una navigazione a più livelli). Sebbene tali pagine possano avere un potenziale di traffico organico, possono anche creare un carico indesiderato sui crawler dei motori di ricerca.
Il modo migliore per risolvere questo problema è limitare i collegamenti sistematici agli elenchi filtrati. Idealmente, dovresti usare 1-2 filtri al massimo. Ad esempio, se hai un negozio con 3 filtri LN (colore/taglia/genere), dovresti consentire la combinazione sistematica di soli 2 filtri (ad esempio, colore-taglia, sesso-taglia). Nel caso in cui sia necessario aggiungere combinazioni di più filtri, è necessario aggiungere manualmente i collegamenti ad essi.
- Ottimizza i parametri di monitoraggio negli URL;
Vari parametri di monitoraggio degli URL (ad es. '?source=thispage') possono creare trap per i crawler, poiché generano un'enorme quantità di nuovi URL. Questo problema è tipico per le pagine con blocchi di "prodotti simili" o "storie correlate", in cui questi parametri vengono utilizzati per tenere traccia del comportamento degli utenti.
Per ottimizzare l'efficienza della scansione in questo caso, si consiglia di trasmettere le informazioni di tracciamento dietro un "#" alla fine dell'URL. In questo modo, tale URL rimarrà invariato. Inoltre, è anche possibile reindirizzare gli URL con parametri di monitoraggio agli stessi URL ma senza monitoraggio.
- rimuovere i reindirizzamenti 301 eccessivi;
Supponiamo che tu abbia una grossa fetta di URL a cui sono collegati senza una barra finale. Quando il bot del motore di ricerca visita tali pagine, viene reindirizzato alla versione con una barra.
Pertanto, il bot deve fare il doppio di quanto dovrebbe e alla fine può arrendersi e smettere di gattonare. Per evitare ciò, prova ad aggiornare tutti i link all'interno del tuo sito ogni volta che modifichi gli URL.
Priorità di scansione
Come detto sopra, Google dà la priorità ai siti Web per la scansione. Quindi non c'è da stupirsi che faccia la stessa cosa con le pagine all'interno di un sito Web sottoposto a scansione.
Per la maggior parte dei siti Web, la pagina con la priorità di scansione più alta è la home page.
Tuttavia, come detto prima, in alcuni casi può essere anche la categoria più popolare o la pagina del prodotto più visitata. Per trovare le pagine che ottengono un numero maggiore di scansioni da parte di Googlebot, basta guardare i log del tuo server.
Sebbene Google non annunci ufficialmente che i fattori che possono presumibilmente influenzare la priorità di scansione di una pagina del sito sono:
- inclusione in una mappa del sito XML (e aggiunta dei tag Priority* per le pagine più importanti),
- il numero di link in entrata,
- il numero di collegamenti interni,
- popolarità della pagina (n. di visite),
- PageRank.
Ma anche dopo aver aperto la strada ai robot dei motori di ricerca per eseguire la scansione del tuo sito Web, potrebbero comunque ignorarlo. Continua a leggere per scoprire perché.
Per capire meglio come eseguire la scansione della priorità, guarda questo keynote virtuale di Gary Illyes.
Parlando dei tag di priorità in una mappa del sito XML, possono essere aggiunti manualmente o con l'aiuto delle funzionalità integrate della piattaforma su cui si basa il tuo sito. Inoltre, alcune piattaforme supportano estensioni/app della mappa del sito XML di terze parti che semplificano il processo.
Utilizzando il tag XML Sitemap Priority, puoi assegnare i seguenti valori a diverse categorie di pagine del sito:
- 0.0-0.3 a pagine di utilità, contenuto obsoleto e pagine di minore importanza,
- 0.4-0.7 agli articoli del tuo blog, alle FAQ e alle pagine esperte, alle pagine di categorie e sottocategorie di importanza secondaria e
- 0.8-1.0 alle categorie principali del sito, alle pagine di destinazione chiave e alla home page.
Asporto
• Google ha una propria visione sulle priorità del processo di scansione.
• Una pagina che dovrebbe entrare nell'indice del motore di ricerca dovrebbe essere a 1-4 clic dalla home page, dalle categorie principali del sito o dalle pagine del sito più popolari.
• Per impedire a Googlebot di rallentare e ottimizzare il budget di scansione del tuo sito web e la profondità di scansione, dovresti trovare e correggere 404, JS e altri errori di pagina, ottimizzare l'impaginazione del sito e i filtri di navigazione, rimuovere reindirizzamenti 301 eccessivi e ottimizzare i parametri di tracciamento negli URL.
• Per migliorare la priorità di scansione di pagine importanti del sito, assicurarsi che siano incluse in una mappa del sito XML (con tag Priority) e ben collegate con altre pagine del sito, avere collegamenti provenienti da altri siti Web pertinenti e autorevoli.
Mito 3. Una mappa del sito XML può risolvere tutti i problemi di scansione e indicizzazione.
Pur essendo un buon strumento di comunicazione che avvisa Google sugli URL del tuo sito e sui modi per raggiungerli, una sitemap XML NON garantisce che il tuo sito sarà visitato dai bot dei motori di ricerca (per non parlare dell'inclusione di tutte le pagine del sito nell'indice) .
Inoltre, dovresti capire che le mappe del sito non ti aiuteranno a migliorare il posizionamento del tuo sito. Anche se una pagina viene scansionata e inclusa nell'indice dei motori di ricerca, la sua performance di ranking dipende da moltissimi altri fattori (link interni ed esterni, contenuti, qualità del sito, ecc.).
Tuttavia, se utilizzata correttamente, una Sitemap XML può migliorare notevolmente l'efficienza della scansione del tuo sito. Di seguito sono riportati alcuni consigli su come massimizzare il potenziale SEO di questo strumento.
Sii coerente
Quando crei una mappa del sito, ricorda che verrà utilizzata come tabella di marcia per i crawler di Google. Pertanto, è importante non fuorviare il motore di ricerca fornendo indicazioni sbagliate.
Ad esempio, potresti occasionalmente includere nella tua mappa del sito XML alcune pagine di utilità (pagine Contattaci o TOS, pagine per l'accesso, pagina di ripristino della password persa, pagine per la condivisione di contenuti , ecc.).
Queste pagine sono generalmente nascoste dall'indicizzazione con meta tag robots noindex o non consentite nel file robots.txt.
Pertanto, includerli in una mappa del sito XML confonderà solo i Googlebot, il che potrebbe influenzare negativamente il processo di raccolta delle informazioni sul tuo sito web.
Aggiorna regolarmente
La maggior parte dei siti Web sul Web cambia quasi ogni giorno. Soprattutto il sito Web di e-commerce con prodotti e categorie che si spostano regolarmente dentro e fuori dal sito.
Per mantenere Google ben informato, devi mantenere aggiornata la tua mappa del sito XML.
Alcune piattaforme (Magento, Shopify) hanno funzionalità integrate che ti consentono di aggiornare periodicamente le tue mappe del sito XML o supportano alcune soluzioni di terze parti in grado di svolgere questa attività.
Ad esempio, in Magento 2, puoi visualizzare la periodicità dei cicli di aggiornamento delle mappe del sito. Quando lo definisci nelle impostazioni di configurazione della piattaforma, segnali al crawler che le pagine del tuo sito vengono aggiornate a un determinato intervallo di tempo (orario, settimanale, mensile) e il tuo sito ha bisogno di un'altra scansione.
Clicca qui per saperne di più.
Ma ricorda che, sebbene l'impostazione della priorità e della frequenza per gli aggiornamenti delle mappe del sito sia utile, potrebbero non essere al passo con le modifiche reali e talvolta non fornire un'immagine reale.
Ecco perché assicurati che la tua mappa del sito rifletta tutte le modifiche apportate di recente.
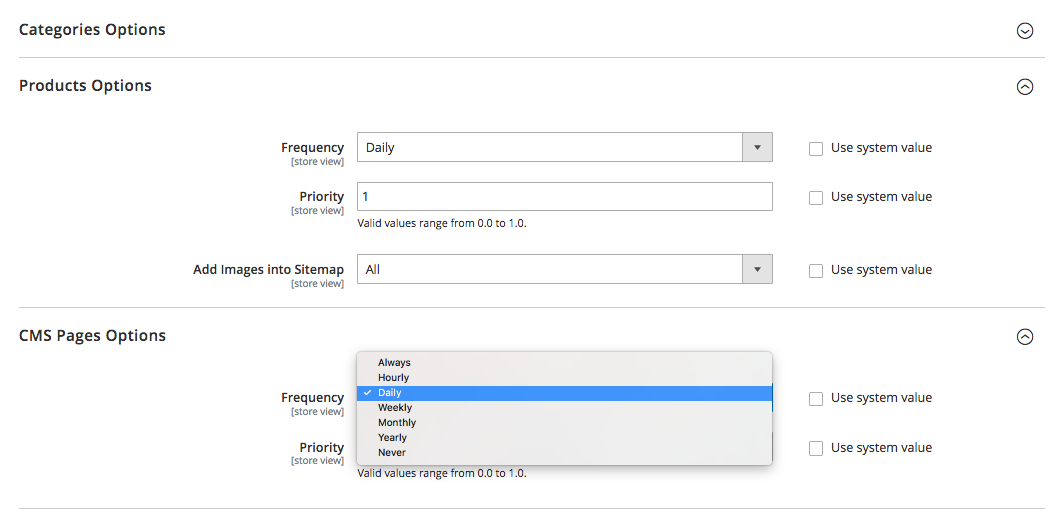 Segmenta i contenuti del sito e imposta le giuste priorità di scansione
Segmenta i contenuti del sito e imposta le giuste priorità di scansione
Google sta lavorando duramente per misurare la qualità complessiva del sito e visualizzare solo i siti Web migliori e più pertinenti.
Ma come spesso accade, non tutti i siti sono creati uguali e in grado di fornire un valore reale.
Ad esempio, un sito Web può essere composto da 1.000 pagine e solo 50 di esse sono di grado «A». Gli altri sono puramente funzionali, hanno contenuti obsoleti o nessun contenuto.
Se Google inizia a esplorare un sito Web di questo tipo, probabilmente deciderà che è piuttosto scadente a causa dell'elevata percentuale di pagine di basso valore, spam o obsolete.
Ecco perché quando si crea una mappa del sito XML, si consiglia di segmentare il contenuto del sito Web e guidare i robot dei motori di ricerca solo verso le aree del sito meritevoli.
E come forse ricorderai, anche i tag Priority, assegnati alle pagine del sito più importanti nella tua Sitemap XML, possono essere di grande aiuto.
Asporto
• Quando crei una mappa del sito, assicurati di non includere pagine nascoste dall'indicizzazione con meta tag noindex robots o non consentite nel file robots.txt.
• Aggiorna le mappe del sito XML (manualmente o automaticamente) subito dopo aver apportato modifiche alla struttura e al contenuto del sito web.
• Segmenta il contenuto del tuo sito per includere solo le pagine di grado «A» nella mappa del sito.
• Impostare la priorità di scansione per diversi tipi di pagina.
Questo è fondamentalmente.
Hai qualcosa da dire sull'argomento? Sentiti libero di condividere la tua opinione su scansione, indicizzazione o mappe dei siti nella sezione commenti qui sotto.