
Dapatkan Hasil Maksimal dari Apache Solr: Eksplorasi Teknis Pengindeksan Pencarian
Diterbitkan: 2023-02-21Fitur pencarian meningkatkan pengalaman pengguna situs web dengan memungkinkan pengguna menemukan apa yang mereka cari dengan mudah dan cepat. Terlebih lagi untuk website besar, situs e-commerce, dan situs dengan konten dinamis (situs berita, blog).
Apache Solr adalah salah satu platform pencarian paling populer yang digunakan oleh situs web dari semua ukuran. Ini adalah mesin pencari sumber terbuka berbasis Java yang memungkinkan Anda mencari data dalam jumlah besar, seperti artikel, produk, ulasan pelanggan, dan lainnya. Lihatlah lebih dalam ke Apache Solr di artikel ini.
Lihat artikel ini untuk mempelajari cara mengkonfigurasi Apache Solr di Drupal

Mengapa Apache Solr begitu populer?
Apache Solr cepat dan fleksibel dan memungkinkan untuk pencarian teks lengkap, penyorotan hit (menyoroti istilah pencarian yang cocok), pencarian segi (pencarian yang lebih halus), pengindeksan waktu nyata (memungkinkan konten baru untuk segera diindeks), pengelompokan dinamis ( mengatur hasil pencarian ke dalam grup), integrasi database, fitur NoSQL (database non-relasional) dan penanganan dokumen yang kaya (untuk mengindeks berbagai format dokumen seperti PDF, MS Office, Open office).
Beberapa fakta yang perlu diketahui tentang Apache Solr:
- Ini awalnya dikembangkan oleh jaringan CNET, inc. sebagai mesin pencari untuk situs web dan artikel mereka. Kemudian, itu bersumber terbuka dan menjadi proyek Apache tingkat atas.
- Mendukung beberapa bahasa pemrograman seperti PHP, Java, Python, dan Ruby. Itu juga menyediakan API untuk bahasa-bahasa ini.
- Memiliki dukungan bawaan untuk pencarian geospasial, memungkinkan untuk mencari konten berdasarkan lokasinya. Sangat berguna untuk situs seperti situs web real estat, situs web perjalanan, dll.
- Mendukung fitur pencarian lanjutan seperti pemeriksaan ejaan, pelengkapan otomatis, dan pencarian khusus melalui API dan plugin.
- Menggunakan Lucene untuk pengindeksan dan pencarian.
Apa itu Lucena
Apache Lucene adalah pustaka pencarian Java sumber terbuka yang memungkinkan Anda dengan mudah menambahkan pencarian atau pengambilan informasi ke aplikasi. Ini serbaguna, kuat, akurat, dan bekerja pada algoritma pencarian yang efisien.
Meskipun dikenal dengan kemampuan pencarian teks lengkapnya, Lucene juga dapat digunakan untuk klasifikasi dokumen, analisis data, dan pencarian informasi. Ini juga mendukung banyak bahasa selain bahasa Inggris seperti Jerman, Prancis, Spanyol, Cina, Jepang, dan banyak lagi.
Apa itu Pengindeksan?
Semua mesin pencari dimulai dengan pengindeksan. Pengindeksan adalah pemrosesan data asli menjadi pencarian referensi silang yang sangat efisien untuk memfasilitasi pencarian cepat.
Mesin pencari tidak mengindeks data secara langsung. Teks pertama kali dipecah menjadi token (elemen atom). Pencarian adalah proses berkonsultasi dengan indeks pencarian dan mengambil dokumen yang cocok dengan kueri.
Keuntungan pengindeksan
- Pengambilan informasi yang cepat dan akurat (mengumpulkan, mengurai, dan menyimpan)
- Tanpa pengindeksan, mesin pencari membutuhkan lebih banyak waktu untuk memindai setiap dokumen
Aliran pengindeksan
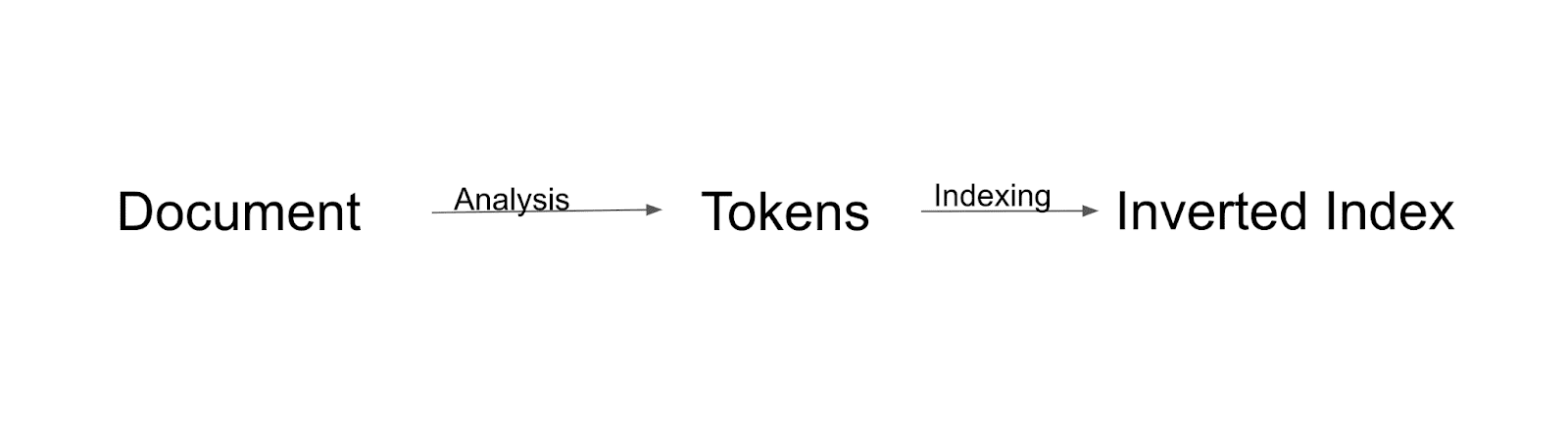
Pertama, dokumen akan dianalisis dan dipecah menjadi token. Semua token itu akan diindeks ke indeks terbalik. Indeks terbalik adalah cara Solr membangun indeks.
Cara kerja pengindeksan terbalik
Anggap saja kita memiliki 3 dokumen:
- Saya suka coklat (D 1)
- Saya memesan kue coklat (D 2)
- Saya menyiapkan kue vanila besar (D 3)
Cara tokenized adalah seperti yang ditunjukkan pada kolom ke-2 dari tabel di bawah ini.

“Cokelat” tersedia di D1 dan D2
“Kue” tersedia di D2 dan D3
"Besar" tersedia di D3
"Dipesan" tersedia di D2
"Siap" tersedia di D3
"Vanila" tersedia di D3
Anda akan melihat bahwa kata-kata seperti "aku", "cinta" tidak diberi token. Ini disebut kata Berhenti yang tidak akan diindeks atau dicari oleh Solr.
Jadi ketika seseorang menelusuri istilah “Kue Coklat”, mesin melihat ke dalam indeks. Alih-alih mencari dokumen, pertama-tama ia melihat ke dalam indeks untuk melihat dokumen mana yang memuat kata "Cokelat" dan "Kue". Ini membuatnya mudah dan lebih cepat untuk mengambil dokumen tertentu saja. Ini disebut pengindeksan terbalik.
Skema Penyimpanan
Apache Solr menggunakan skema penyimpanan berbasis dokumen dan menyimpan setiap bagian data sebagai dokumen terpisah dalam koleksi. Ini memungkinkan penyimpanan dan pengambilan data yang efisien dan fleksibel.
Di Drupal, setiap node dianggap sebagai dokumen. Jadi ketika Anda mengindeks node Anda ke Apache Solr, itu dianggap sebagai dokumen. Setiap dokumen dapat berisi banyak bidang. Lucene tidak memiliki skema global yang umum. Yang berarti Anda dapat mengindeks semua jenis bidang di setiap dokumen di Apache Solr.

Cara Install Apache Solr
- Pertama, pastikan Anda telah menginstal Java di sistem Anda.
- Selanjutnya, mari instal Solr dari sini: https://solr.apache.org/downloads.html
- Unduh dan ekstrak Solr.
- Jalankan perintah ini di folder Solr.
◦ bin/solr -e techproducts
Ini akan membuat inti dummy untuk demonstrasi dan juga akan memulai server Solr.
- Setelah server dimulai, buka browser Anda dan ketik "http://localhost:8983/".
- Pastikan Solr berhasil diinstal dengan dummy core.
Struktur Direktori
Setelah Anda menginstal Solr, Anda akan melihat banyak folder seperti:

Docs - berisi dokumentasi tentang Solr
Dist - File .jar utama Solr
Contrib - berisi plugin tambahan dan fitur khusus Solr
Bin - skrip Solr
Contoh - berisi kemampuan demonstrasi solr
Server - jantung Solr. Berisi aplikasi web Solr, log, inti Solr
File konfigurasi
Untuk membuat core, kita membutuhkan dua file wajib.
- Skema.xml
- Solrconfig.xml
Skema.xml
- Ini akan berisi jenis bidang yang Anda rencanakan untuk didukung dan bagaimana jenis tersebut harus dianalisis.
Solrconfig.xml
- Berisi berbagai pengaturan yang mengontrol perilaku inti Solr seperti penangan permintaan, pengirim permintaan, komponen kueri, penangan pembaruan, dll.
Meminta di Solr
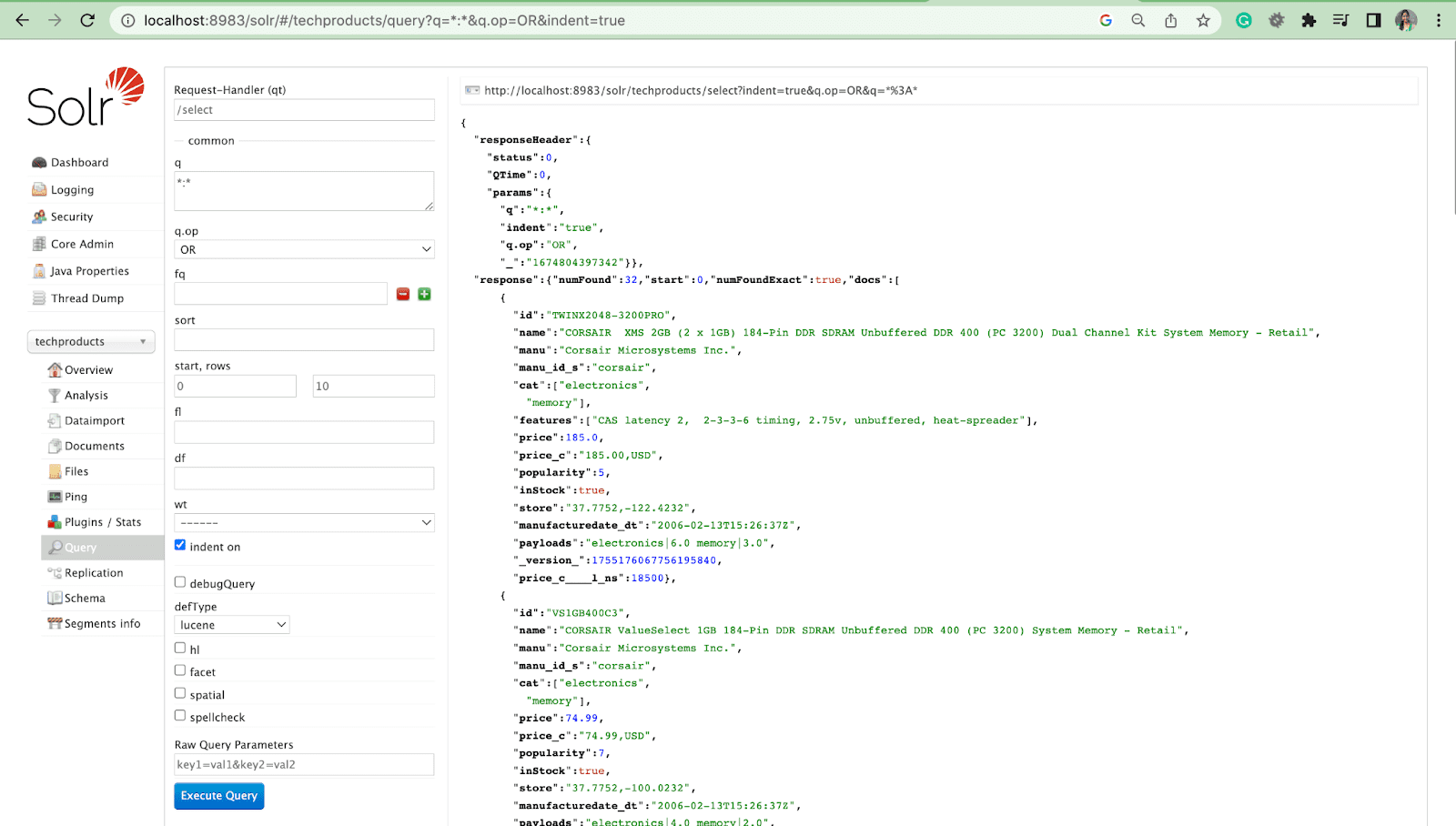
Sekarang mari kita lihat cara menanyakan hasil Solr di UI admin Solr.
Parameter Kueri
- Parameter lokal adalah argumen dalam permintaan Solr yang khusus untuk parameter kueri.
Misalnya: kucing: elektronik
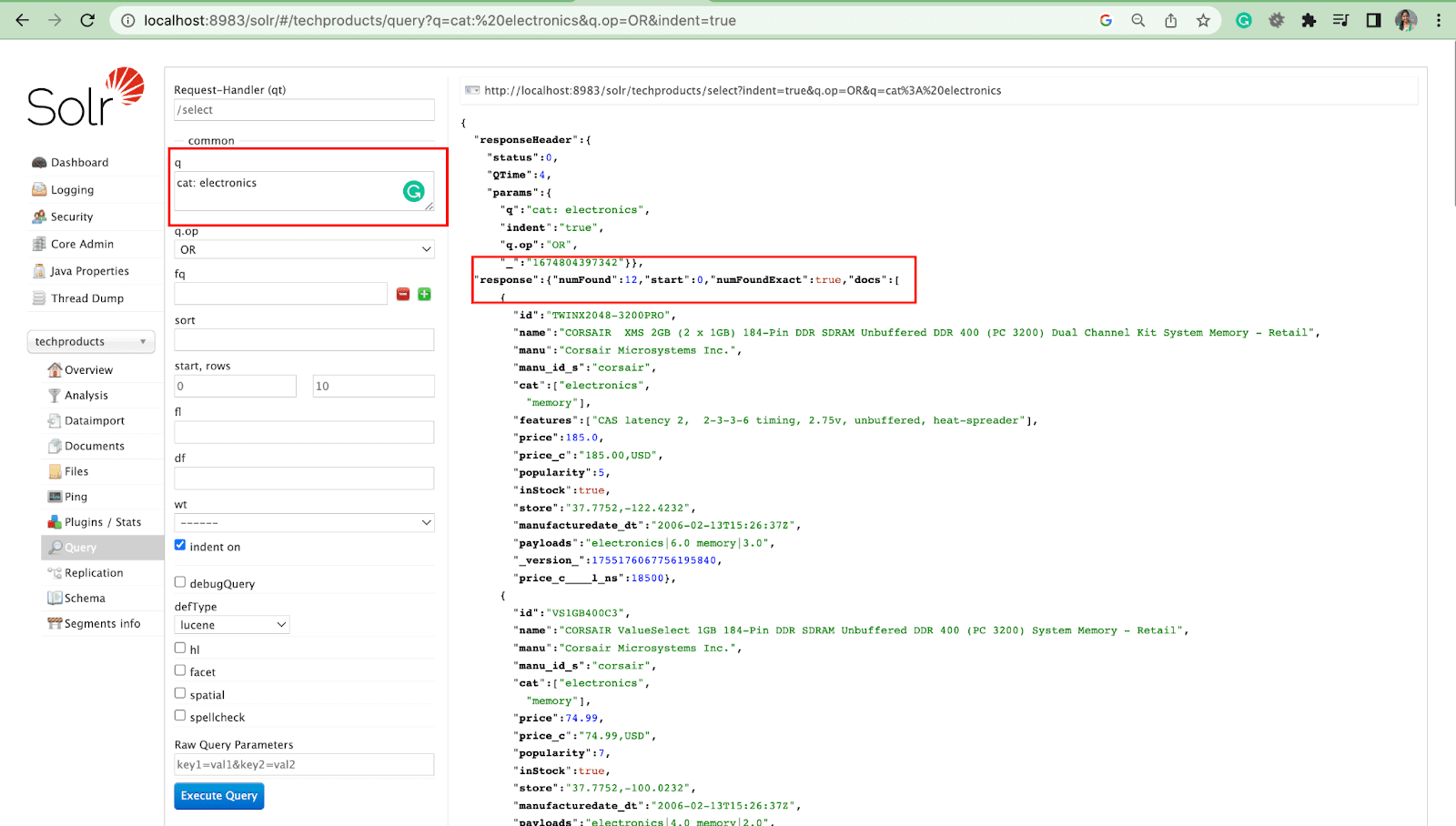
Parameter Kueri dengan operasi
- Kami dapat menanyakan beberapa bidang dengan operasi.
Misalnya: cat: electronics id:TWINX2048-3200PRO dengan q.op DAN
[ATAU]
kucing: elektronik DAN id:TWINX2048-3200PRO
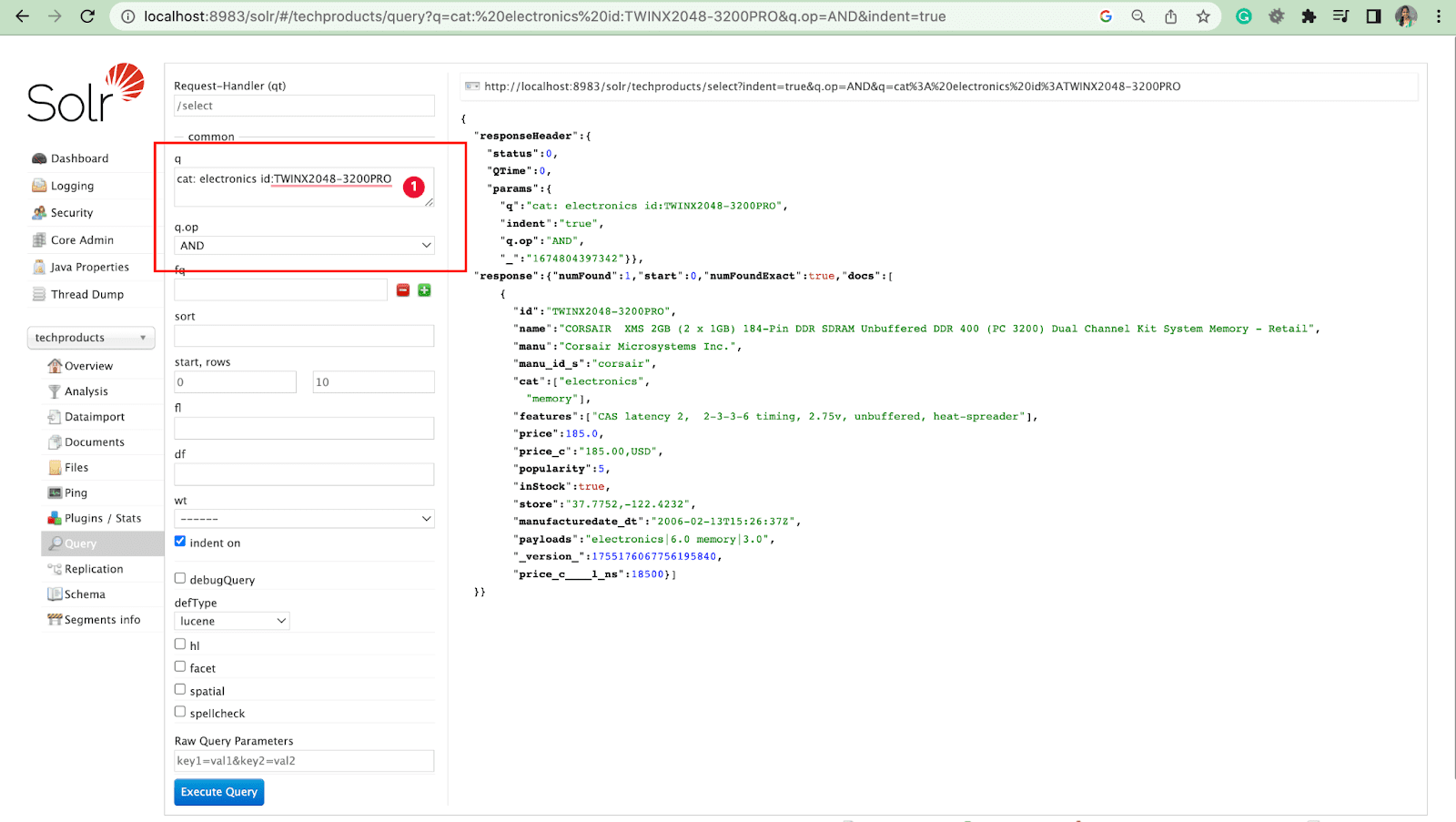
[ATAU]
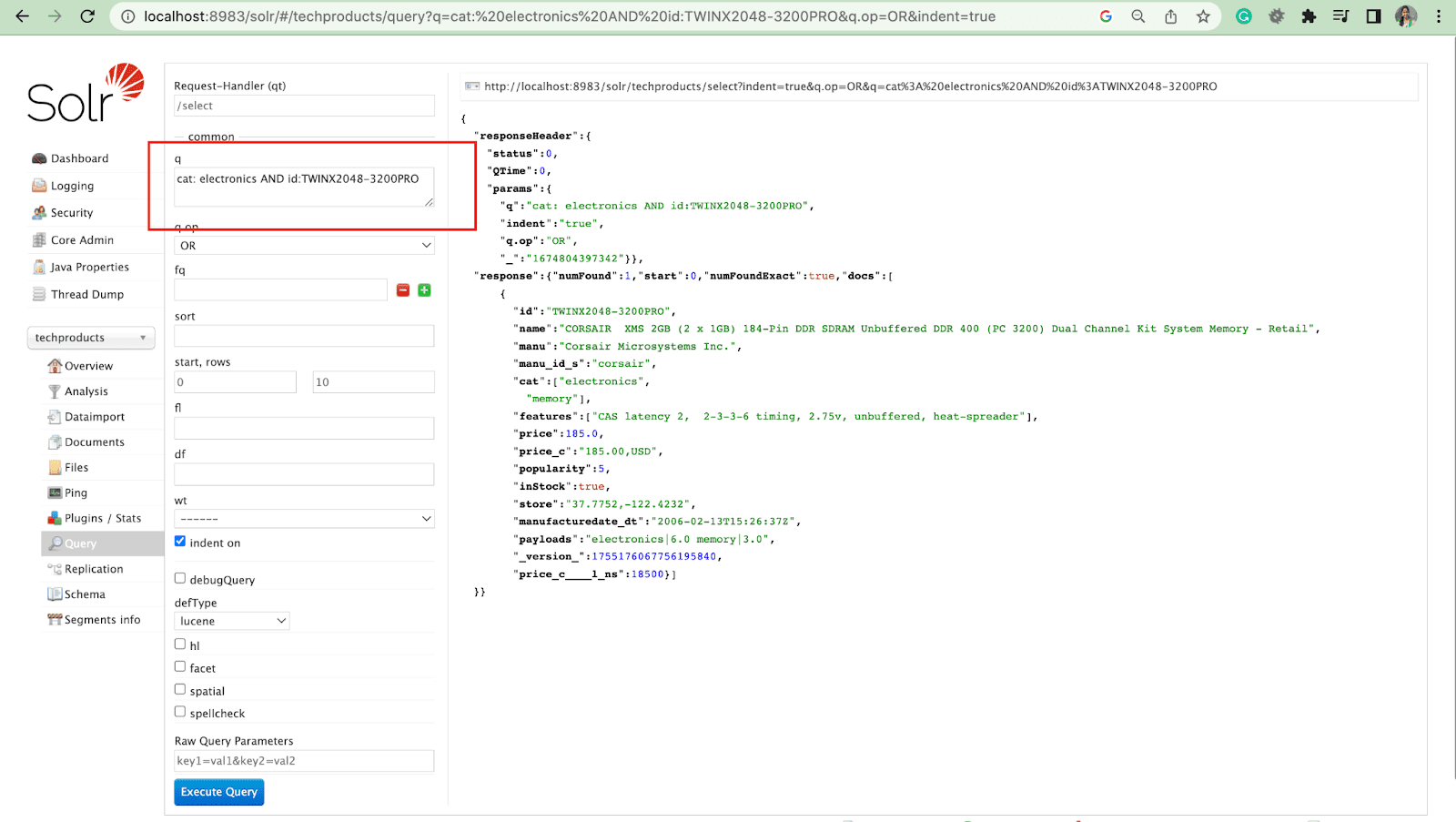
Filter Kueri
Kueri filter membantu mempersempit hasil pencarian. Kueri dapat ditentukan oleh parameter fq untuk membatasi dokumen mana yang dikembalikan dalam superset, tanpa memengaruhi skor.
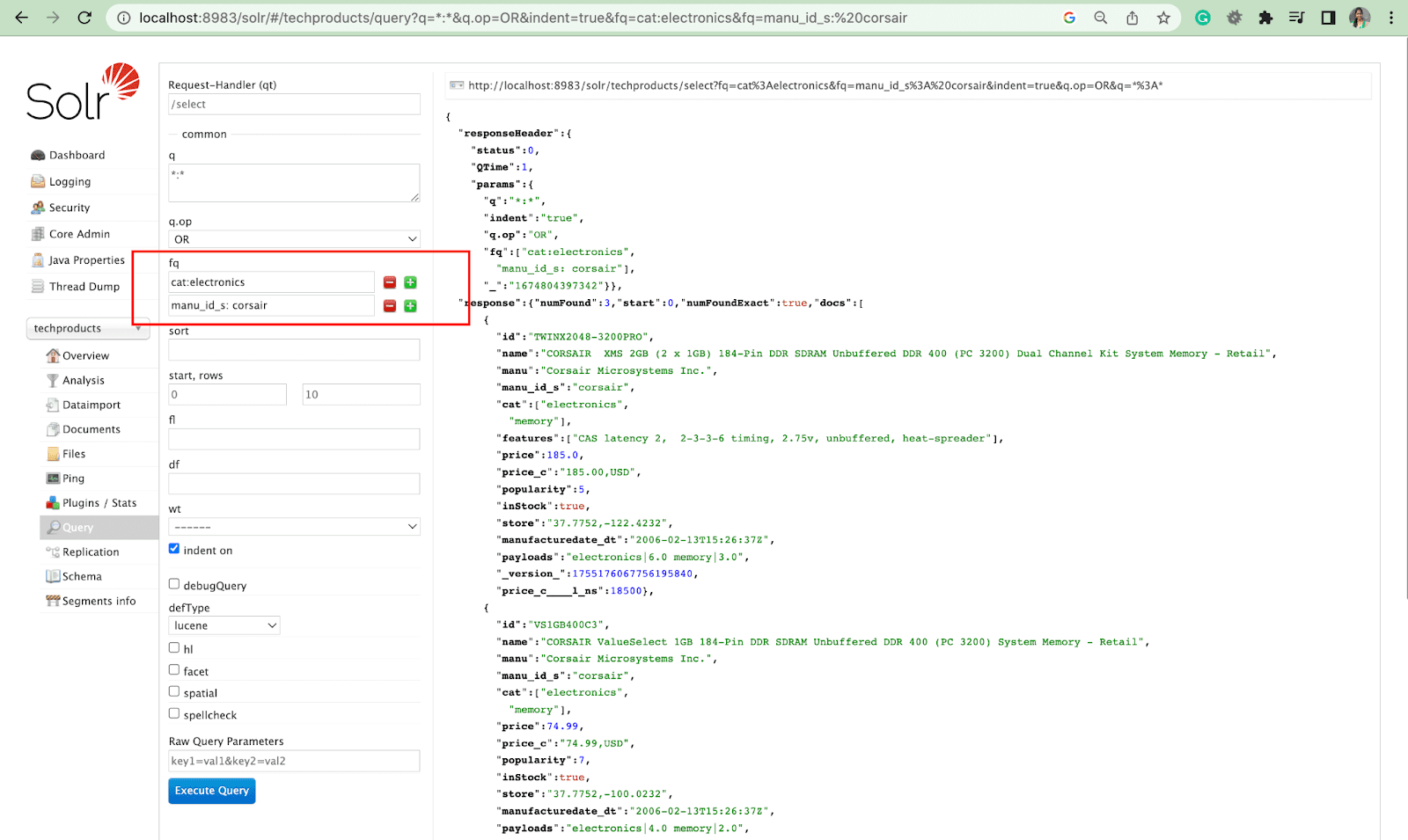
Sortir Parameter
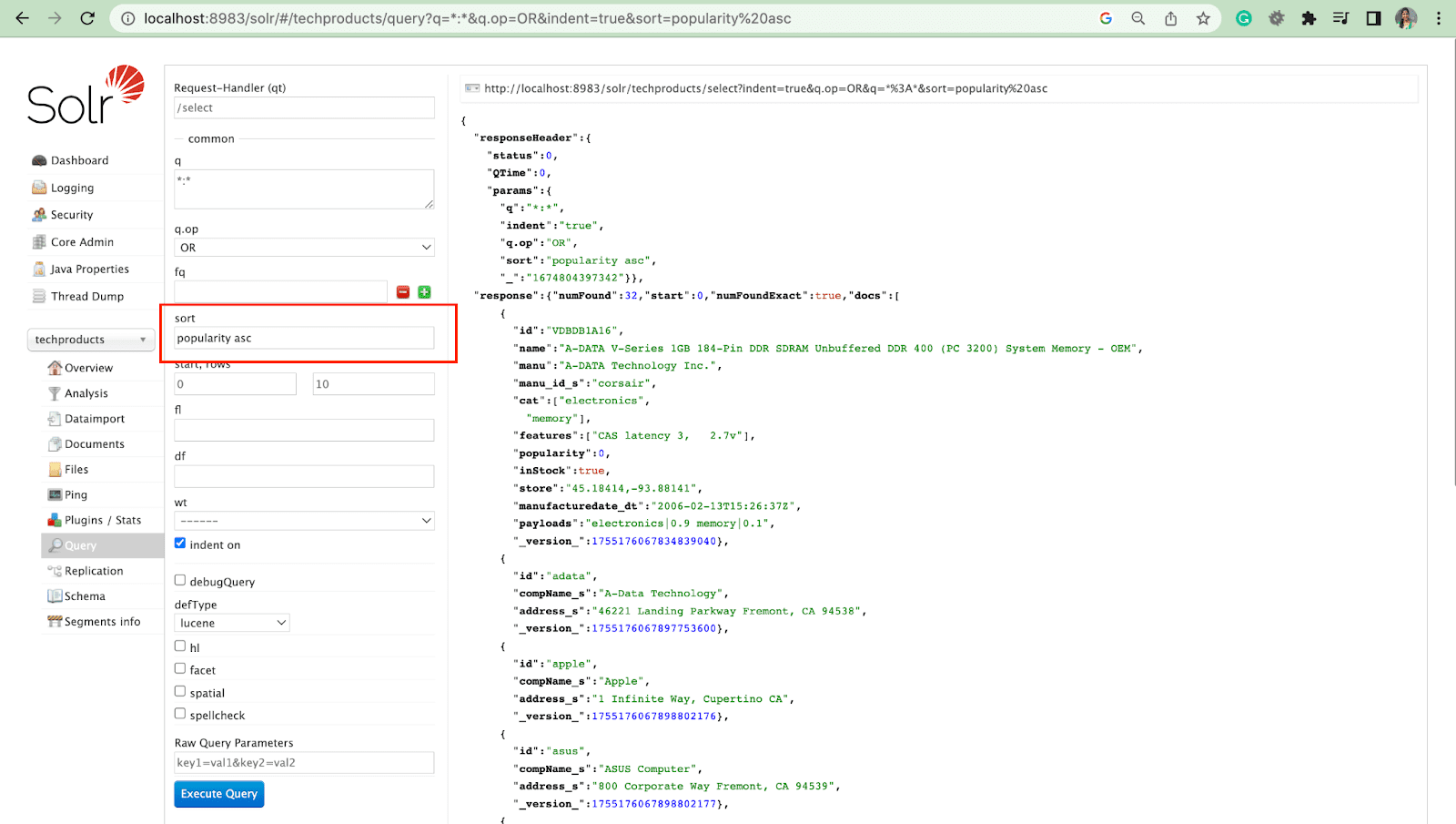
Parameter sortir mengatur hasil pencarian dalam urutan menaik (asc) atau menurun (desc). Bergantung pada kontennya, parameter dapat digunakan secara numerik atau abjad.
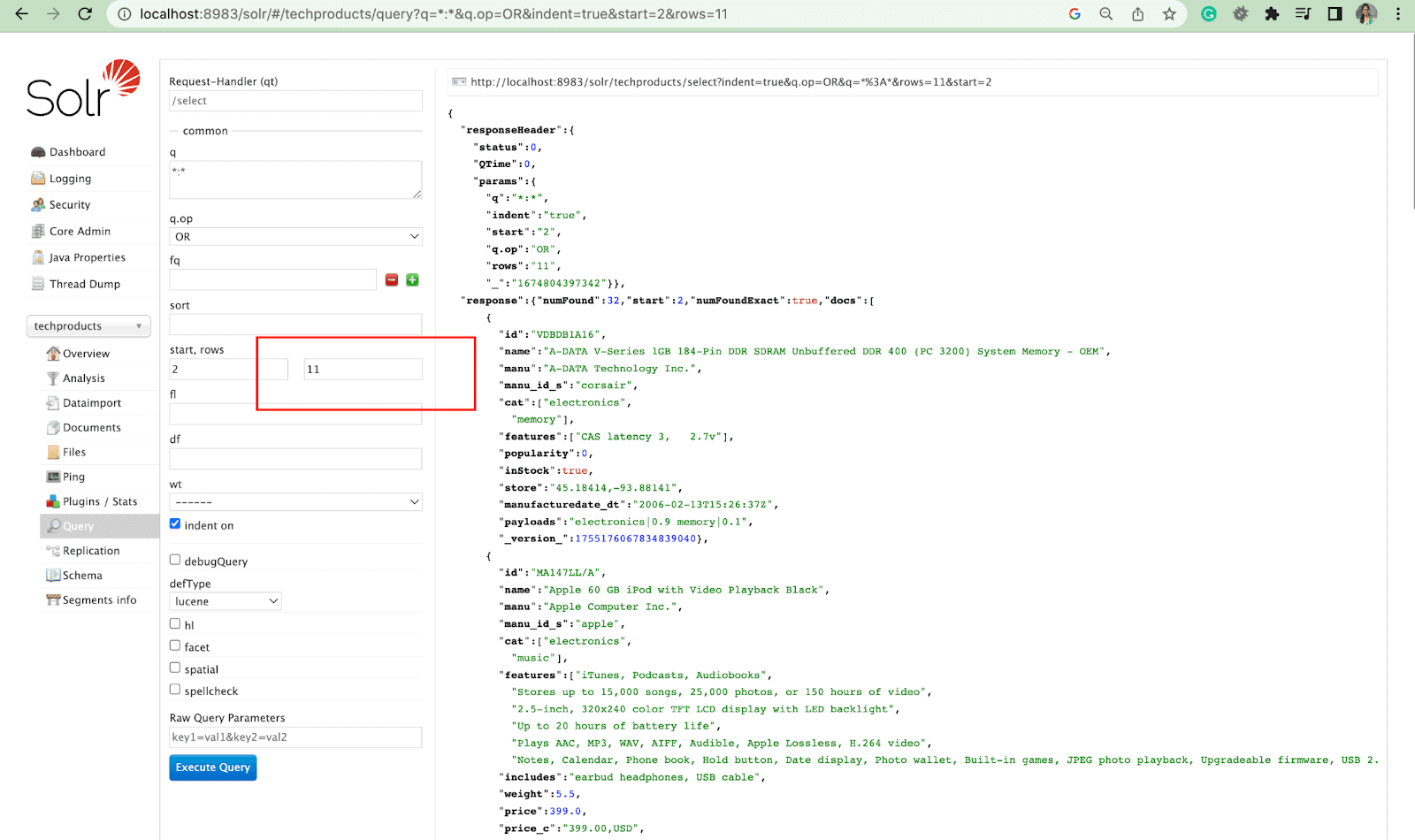
Parameter Baris
Parameter rows memungkinkan Anda untuk memberi nomor halaman hasil dari kueri.
Parameter Daftar Bidang
Parameter fl membatasi informasi yang disertakan dalam respons kueri ke daftar bidang tertentu.
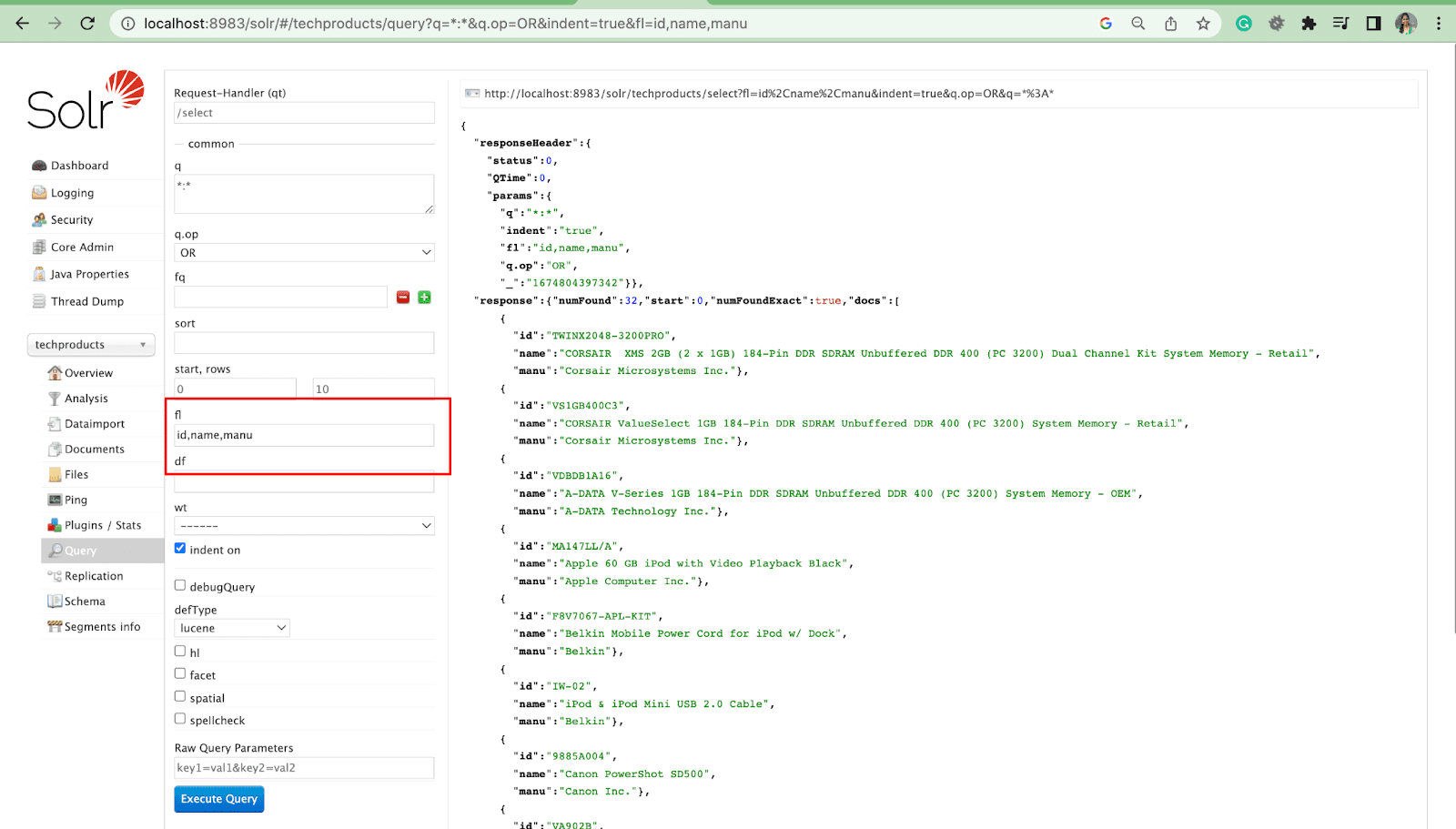
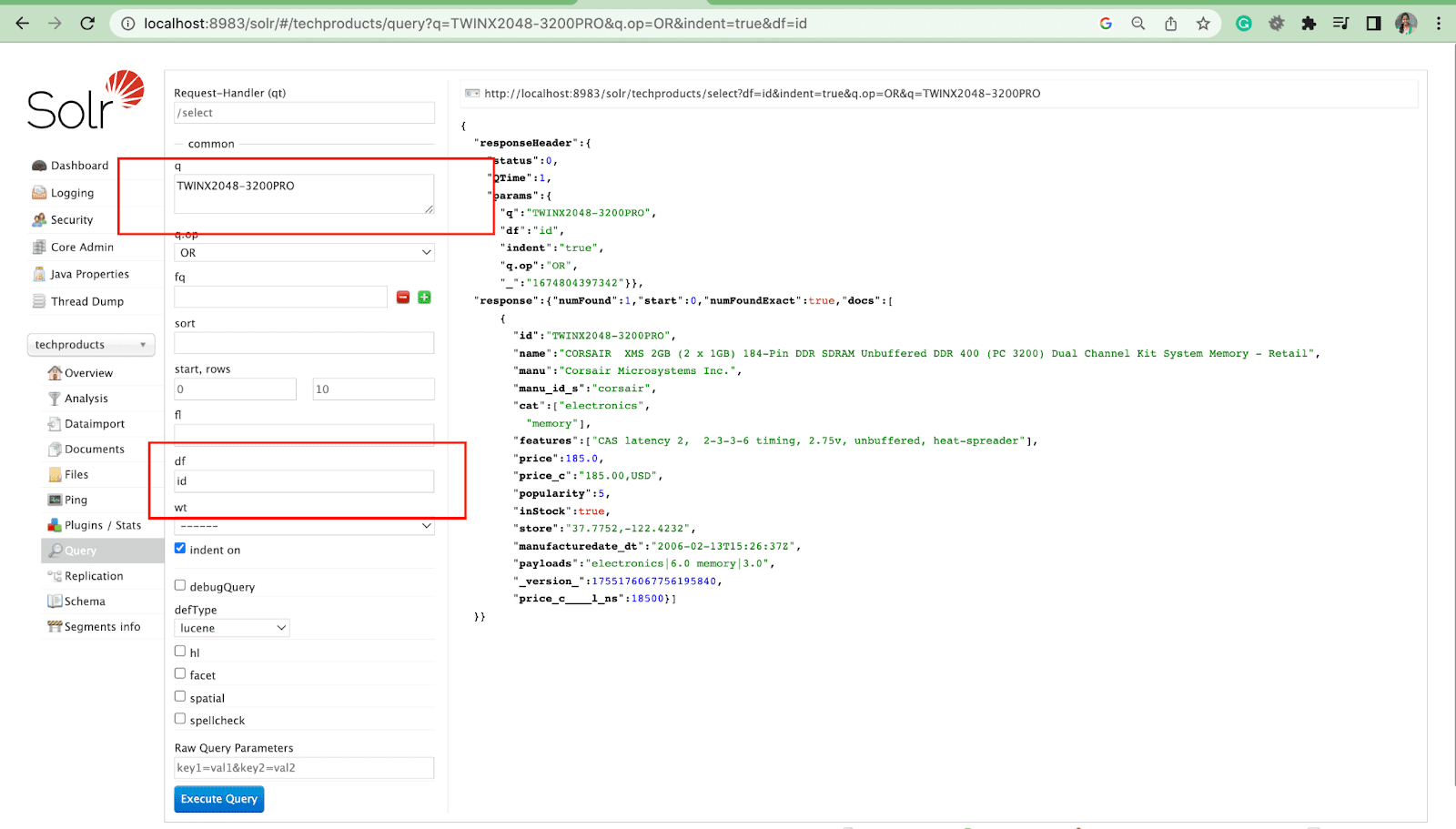
Parameter bidang default
Parameter bidang default adalah bidang default untuk parameter kueri.
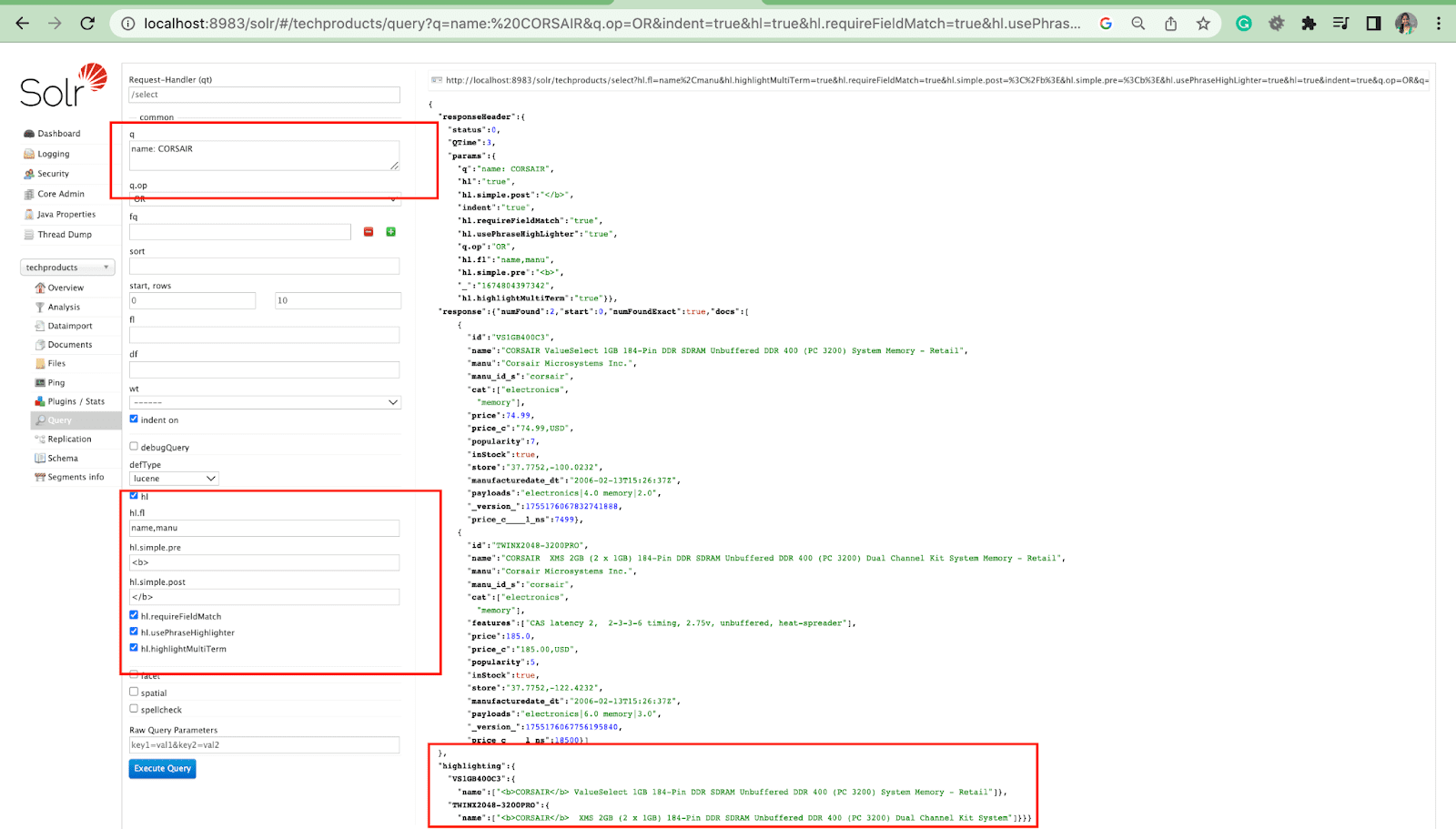
Sorotan Parameter
Fitur sorotan di Solr memungkinkan penyertaan fragmen dokumen yang cocok dengan kueri.
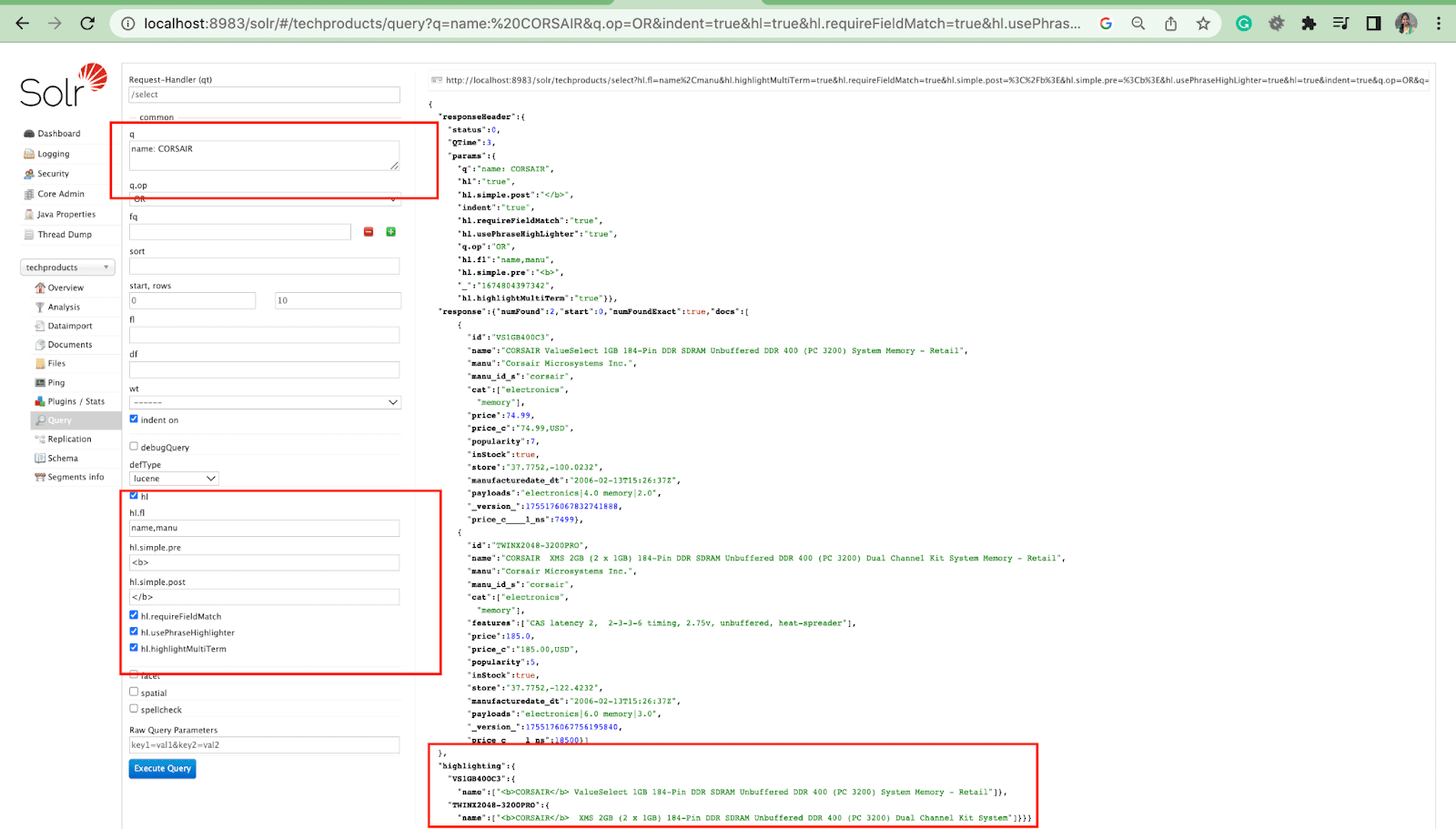
Beberapa parameter sorotan yang paling umum adalah:
- Hl.fl - Menyoroti daftar bidang.
- Hl.simple.pre - Menentukan "tag" mana yang harus digunakan sebelum kata yang disorot.
- Hl.simple.post - Menentukan "tag" mana yang harus digunakan setelah istilah yang disorot.
- hl.highlightMultiTerm - Jika disetel ke true , Solr akan menyorot kueri wildcard. Jika false , mereka tidak akan disorot sama sekali.
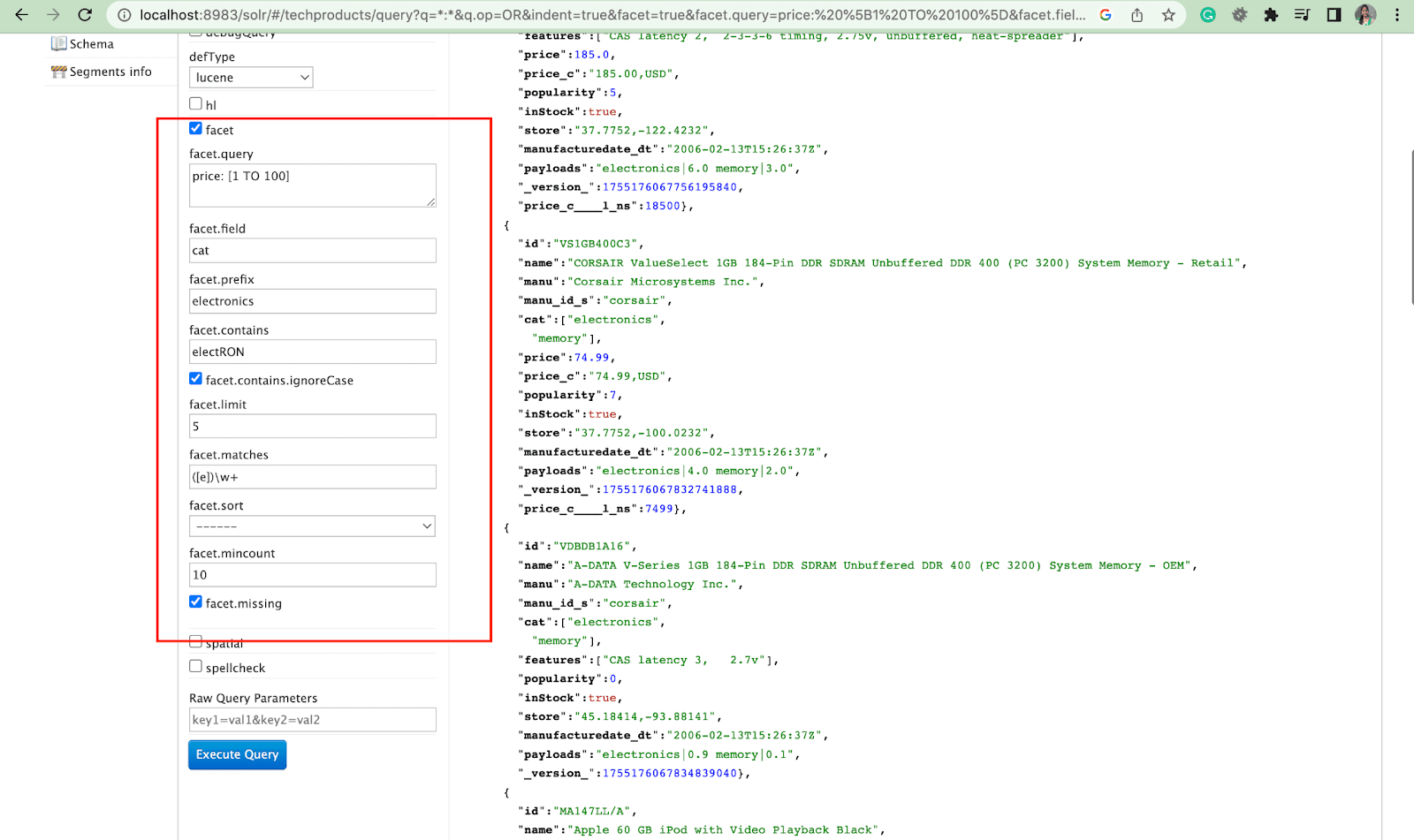
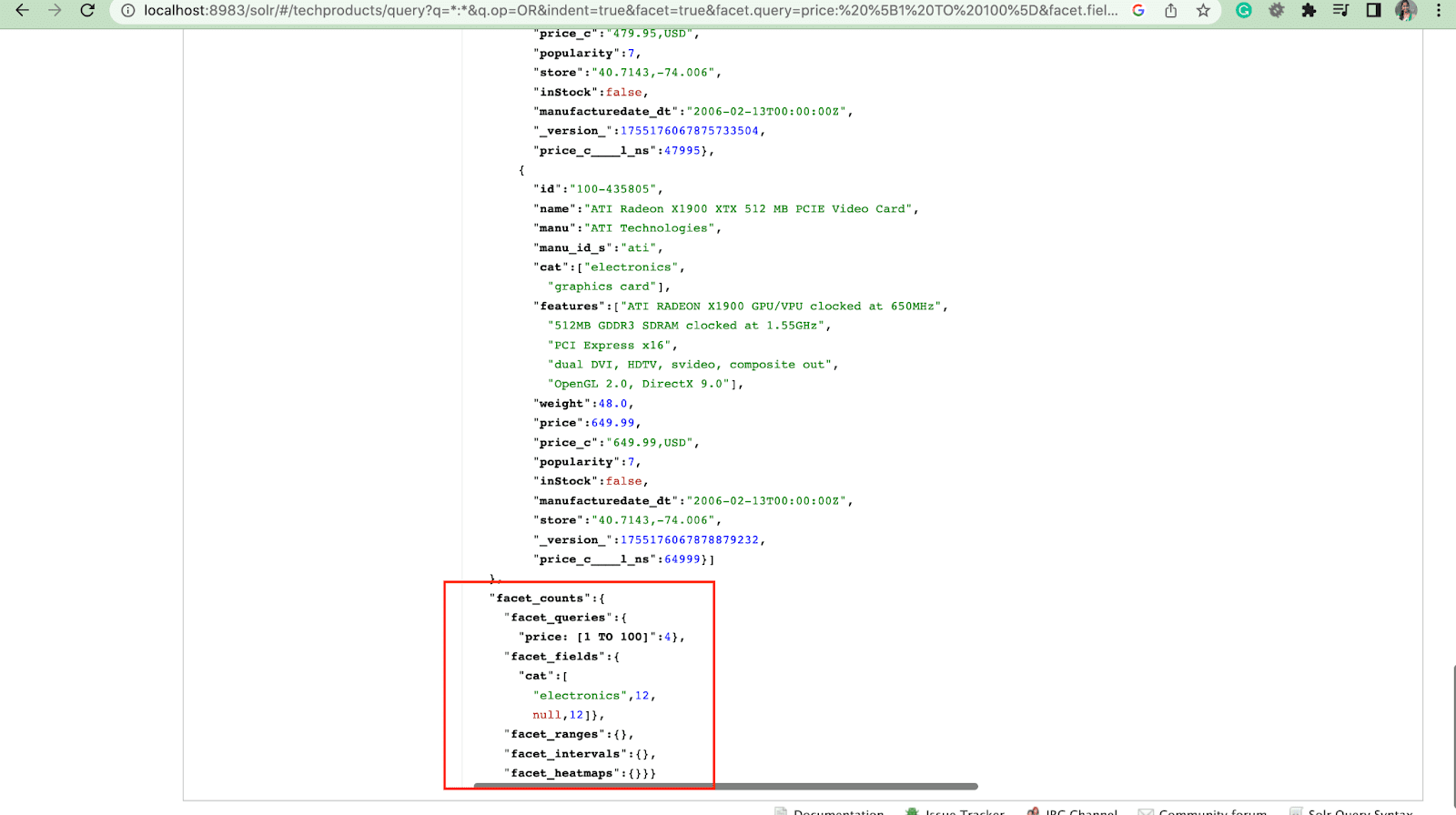
Segi:
Faset memungkinkan pengguna untuk menjelajahi dan menyempurnakan sekumpulan besar hasil penelusuran. Mereka ditampilkan di UI sebagai kotak centang, dropdown, atau kontrol lainnya. Dua parameter umum untuk mengontrol faset adalah:
- Parameter segi
Dengan menggunakan parameter faset, pengguna dapat menghasilkan faset berdasarkan nilai dari satu atau beberapa kolom dalam indeks pencarian mereka. Dalam hasil pencarian, parameter faset dapat dikonfigurasi untuk mengontrol bagaimana faset dibuat dan ditampilkan.
2. Paramater facet.query
Saat pengguna menyertakan parameter facet.query dalam kueri Solr mereka, Solr akan menghasilkan daftar jumlah faset yang sesuai dengan jumlah dokumen dalam indeks yang cocok dengan setiap kueri. Facet.query berguna saat Anda ingin menghasilkan faset berdasarkan kriteria pencarian kompleks yang tidak dapat dengan mudah direpresentasikan menggunakan nilai bidang sederhana.
Ada beberapa parameter faset lain seperti facet.field (untuk menentukan bidang yang harus digunakan untuk menghasilkan faset) , facet.limit (jumlah maksimum faset untuk ditampilkan untuk setiap bidang) , facet.mincount (jumlah minimum dokumen yang diperlukan untuk faset yang akan disertakan dalam respons) , faset.sort (menentukan urutan di mana nilai faset harus ditampilkan) .
Pikiran Akhir
Apache Solr adalah mesin pencari yang sangat serbaguna yang hadir dengan banyak fitur menarik yang dapat disesuaikan sesuai kebutuhan Anda. Drupal bekerja sangat baik dengan Apache Solr. Jika Anda sedang mencari pakar Drupal untuk mengonfigurasi mesin telusur yang kuat untuk proyek baru Anda, kami ingin melanjutkannya!