
Comment configurer le fichier robots.txt de Magento 2 pour le référencement
Publié: 2021-01-21Table des matières
Le référencement est un facteur important pour le succès de votre boutique, et un fichier robots.txt correctement configuré contribue largement à faciliter le travail des robots des moteurs de recherche.
Qu'est-ce que robots.txt ?
En un mot, robots.txt est un fichier qui indique aux robots des moteurs de recherche ce qu'ils peuvent ou ne peuvent pas explorer. Sans robots.txt dans votre répertoire racine, les robots des moteurs de recherche traversant votre boutique exploreront tout ce qu'ils peuvent, et cela inclut les pages dupliquées ou sans importance sur lesquelles vous ne voulez pas que les robots des moteurs de recherche gaspillent leur budget d'exploration. Un robots.txt devrait pouvoir résoudre ce problème.
Remarque : Le fichier robots.txt ne doit pas être utilisé pour masquer vos pages Web à Google. Vous devriez plutôt utiliser la balise meta noindex à cette fin.
Instructions robots.txt par défaut dans Magento 2
Par défaut, le fichier robots.txt généré par Magento ne contient que quelques instructions de base pour le robot d'exploration Web.
# Instructions par défaut fournies par Magento Agent utilisateur: * Interdire : /lib/ Interdire : /*.php$ Interdire : /pkginfo/ Interdire : /signaler/ Interdire : /var/ Interdire : /catalogue/ Interdire : /client/ Interdire : /sendfriend/ Interdire : /revoir/ Interdire : /*SID=
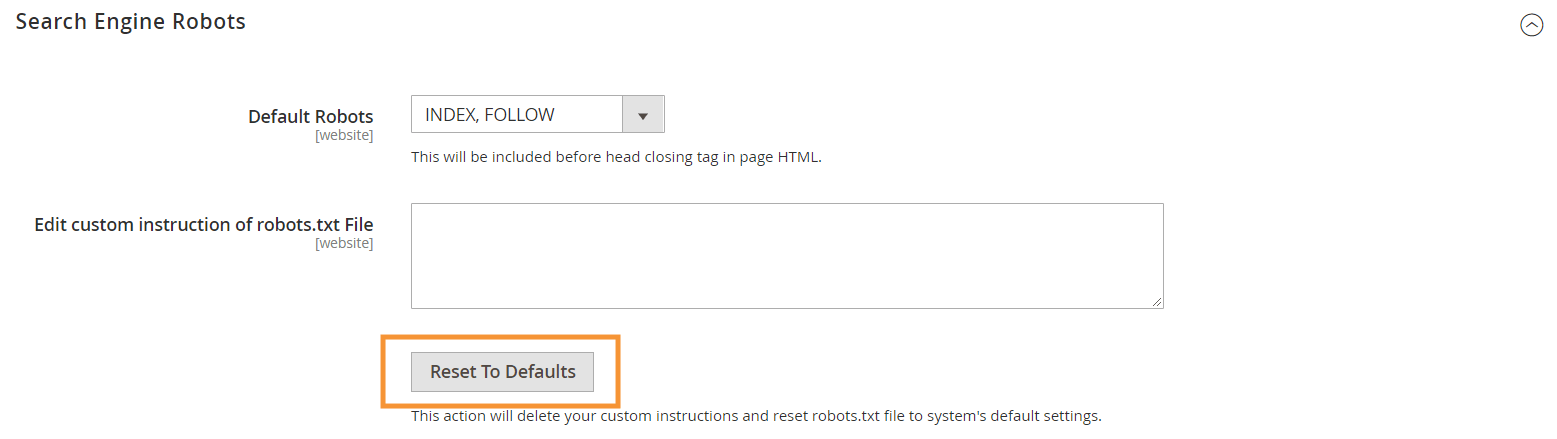
Pour générer ces instructions par défaut, cliquez sur le bouton Reset to Defaults dans la configuration de Search Engine Robots dans votre backend Magento.
Pourquoi vous devez créer des instructions robots.txt personnalisées dans Magento 2
Alors que les instructions robots.txt par défaut fournies par Magento sont nécessaires pour indiquer aux robots d'exploration d'éviter d'explorer certains fichiers utilisés en interne par le système, elles ne sont pas suffisantes pour la plupart des magasins Magento.
Les robots des moteurs de recherche ne disposent que d'une quantité limitée de ressources pour explorer les pages Web. Pour un site avec des milliers, voire des millions d'URL à explorer (ce qui est plus courant que vous ne le pensez), vous devrez hiérarchiser le type de contenu à explorer (avec un sitemap.xml) et interdire les contenus non pertinents. pages d'être explorées (avec un robots.txt). La dernière partie est effectuée en interdisant l'exploration des pages dupliquées, non pertinentes et inutiles dans votre robots.txt.
Format de base des directives robots.txt
Les instructions dans le fichier robots.txt sont présentées de manière cohérente, conviviale pour les utilisateurs non techniques :
# Règle 1 Agent utilisateur : Googlebot Interdire : /nogooglebot/ # Règle 2 Agent utilisateur: * Permettre: / Plan du site : https://www.example.com/sitemap.xml
-
User-agent: indique le crawler spécifique auquel la règle est destinée. Certains agents utilisateurs courants sontGooglebot,Googlebot-Image,Mediapartners-Google,Googlebot-Video, etc. Pour une liste complète des robots d'exploration courants, consultez Présentation des robots d'exploration Google.
-
AllowetDisallow: spécifiez les chemins auxquels le ou les robots d'exploration désignés peuvent ou ne peuvent pas accéder. Par exemple,Allow: /signifie que le robot d'exploration peut accéder à l'ensemble du site sans restriction.
-
Sitemapdu site : indique le chemin vers le plan du site de votre boutique. Le plan du site est un moyen d'indiquer aux robots des moteurs de recherche quel contenu prioriser, tandis que le reste du contenu dans robots.txt indique aux robots quel contenu ils peuvent ou ne peuvent pas explorer.
Toujours dans robots.txt, vous pouvez utiliser plusieurs caractères génériques pour les valeurs de chemin telles que :

-
*: Lorsqu'il est placé dansuser-agent, l'astérisque (*) fait référence à tous les robots des moteurs de recherche (à l'exception des robots AdsBot) qui visitent le site. Lorsqu'il est utilisé dans les directivesAllow/Disallow, cela signifie 0 ou plusieurs instances de tout caractère valide (par exemple,Allow: /example*.csscorrespond à /exemple.css et également à /exemple12345.css ). -
$: désigne la fin d'une URL. Par exemple,Disallow: /*.php$bloquera tous les fichiers qui se terminent par .php -
#: désigne le début d'un commentaire, que les crawlers ignoreront.
Remarque : à l'exception du chemin sitemap.xml, les chemins dans robots.txt sont toujours relatifs , ce qui signifie que vous ne pouvez pas utiliser d'URL complètes (par exemple, https://simicart.com/nogooglebot/) pour spécifier des chemins.
Configurer robots.txt dans Magento 2
Pour accéder à l'éditeur de fichier robots.txt, dans votre admin Magento 2 :
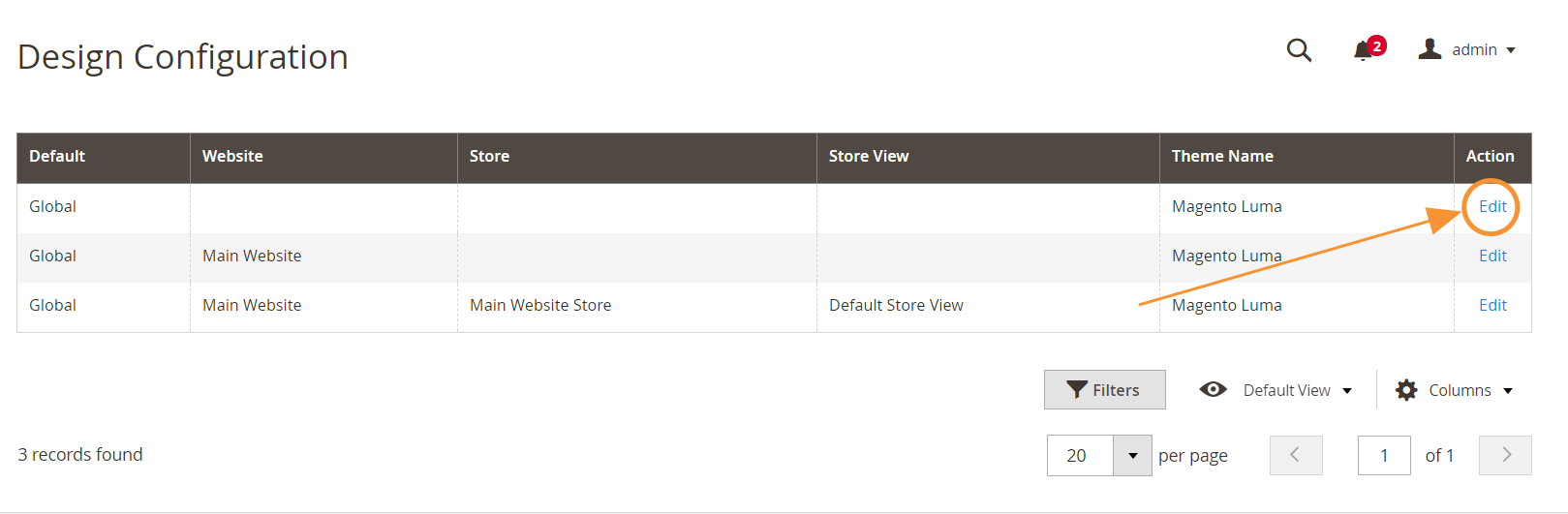
Étape 1 : Allez dans Contenu > Conception > Configuration
Étape 2 : Modifier la configuration globale dans la première ligne
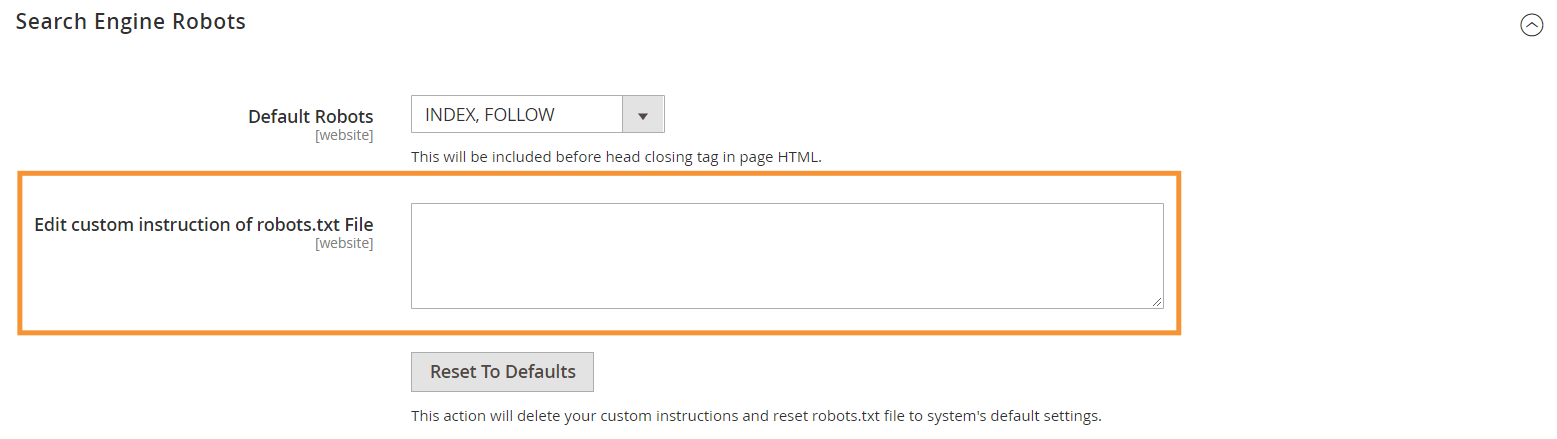
Étape 3 : Dans la section Search Engine Robots, modifiez les instructions personnalisées
Instructions robots.txt recommandées
Voici nos instructions recommandées qui devraient répondre aux besoins généraux. Bien sûr, chaque magasin est différent et vous devrez peut-être modifier ou ajouter quelques règles supplémentaires pour obtenir les meilleurs résultats.
Agent utilisateur: * # Consignes par défaut : Interdire : /lib/ Interdire : /*.php$ Interdire : /pkginfo/ Interdire : /signaler/ Interdire : /var/ Interdire : /catalogue/ Interdire : /client/ Interdire : /sendfriend/ Interdire : /revoir/ Interdire : /*SID= # Interdire les fichiers Magento communs dans le répertoire racine : Interdire : /cron.php Interdire : /cron.sh Interdire : /error_log Interdire : /install.php Interdire : /LICENSE.html Interdire : /LICENSE.txt Interdire : /LICENSE_AFL.txt Interdire : /STATUS.txt # Interdire le compte utilisateur & Pages de paiement : Interdire : /checkout/ Interdire : /onestepcheckout/ Interdire : /client/ Interdire : /client/compte/ Interdire : /client/compte/connexion/ # Interdire les pages de recherche de catalogue : Interdire : /catalogsearch/ Interdire : /catalog/product_compare/ Interdire : /catalog/category/view/ Interdire : /catalog/product/view/ # Interdire les recherches de filtres d'URL Interdire : /*?dir* Interdire : /*?dir=desc Interdire : /*?dir=asc Interdire : /*?limit=all Interdire : /*?mode* # Interdire les répertoires CMS : Interdire : /app/ Interdire : /bin/ Interdire : /dev/ Interdire : /lib/ Interdire : /phpserver/ Interdire : /pub/ # Interdire le contenu dupliqué : Interdire : /tag/ Interdire : /revoir/ Interdire : /*?*product_list_mode= Interdire : /*?*product_list_order= Interdire : /*?*product_list_limit= Interdire : /*?*product_list_dir= # Paramètres du serveur # Interdire les répertoires techniques généraux et les fichiers sur un serveur Interdire : /cgi-bin/ Interdire : /cleanup.php Interdire : /apc.php Interdire : /memcache.php Interdire : /phpinfo.php # Interdire les dossiers de contrôle de version et autres Interdire : /*.git Interdire : /*.CVS Interdire : /*.Zip$ Interdire : /*.Svn$ Interdire : /*.Idea$ Interdire : /*.Sql$ Interdire : /*.Tgz$ Plan du site : https://www.example.com/sitemap.xml
Conclusion
La création d'un fichier robots.txt n'est qu'une des nombreuses étapes de la liste de contrôle SEO de Magento - et optimiser correctement une boutique Magento pour les moteurs de recherche n'est certainement pas une tâche facile pour la plupart des propriétaires de boutiques. Si vous ne souhaitez pas vous en occuper, nous pouvons nous occuper de tout pour vous. Chez SimiCart, nous fournissons des services de référencement et d'optimisation de la vitesse qui garantissent les meilleurs résultats pour votre magasin.