
La forma correcta de no indexar una página
Publicado: 2022-12-02Puede parecer contradictorio, pero no todas las páginas de su sitio web deberían aparecer en los resultados de búsqueda. La optimización de motores de búsqueda (SEO) se esfuerza por aumentar la visibilidad de búsqueda y el tráfico orgánico y, a veces, la mejor manera de lograr ese objetivo es restringir qué contenido puede aparecer en los resultados de búsqueda.
Si te estás rascando la cabeza o me estás engañando, sigue leyendo para descubrir el valor de no indexar una página o subdirectorio y cómo implementar etiquetas noindex.
¿Qué significa Noindex?
El término "noindex" es una directiva especial en una metaetiqueta de robots que le dice a los rastreadores de búsqueda que excluyan la página de las páginas de resultados del motor de búsqueda (SERP). Eso significa que los buscadores no podrán acceder a la página a través de la búsqueda.
Una parte valiosa de cualquier estrategia técnica de SEO, las metaetiquetas de robots le permiten excluir páginas que no brindan valor a los buscadores o que contienen información que no desea que aparezca en los resultados de búsqueda, como:
- Páginas de confirmación y agradecimiento
- Páginas de inicio de sesión
- Política de privacidad o página de términos de servicio
- contenido cerrado
- Error de mensajes
Metaetiqueta Robots vs. Robots.txt vs. Etiqueta X-Robots
La metaetiqueta Robots a menudo se confunde con el archivo robots.txt y la etiqueta x-robots. Los tres dan instrucciones para buscar rastreadores sobre páginas y son parte del protocolo de exclusión de robots (REP). En pocas palabras: le dicen a Google qué poner en la Búsqueda de Google y qué mantener fuera de ella, así como qué páginas deben rastrear. Sin embargo, no pueden ni deben usarse indistintamente.
Metaetiqueta Robots
Se agrega una metaetiqueta de robots a la sección <head> de una página web en particular y solo transmite instrucciones sobre esa página específica. A menudo llamada etiqueta noindex o metaetiqueta noindex, la metaetiqueta robots puede hacer más que simplemente decirle a un rastreador de búsqueda que no indexe una página.
También se puede usar para pedir a los rastreadores que no sigan enlaces, traduzcan una página, bloqueen un bot de búsqueda específico o eviten que un enlace almacenado en caché aparezca en las SERP.
Las directivas comunes de etiquetas meta de robots incluyen:
- Noindex, nofollow — <meta nombre=”robots” content=”noindex, nofollow”>
Googlebot y otros rastreadores web pueden acceder a la página, pero no deben indexarla ni seguir sus enlaces. - Noindex, seguir — <meta name=”robots” content=”noindex”>
Googlebot y otros rastreadores web pueden acceder a la página y seguir los enlaces que contiene, pero no deben indexar la página en sí. No es necesario que incluyas "seguir" en la metaetiqueta, ya que esa es la opción predeterminada.
Robots.txt
Robots.txt es un archivo que permite a los propietarios de sitios indicar a los motores de búsqueda qué partes de su sitio no desean que se rastreen. Es como un letrero personal de No molestar para su sitio web que cuelga en el directorio raíz de su dominio o subdominio.
Un archivo robots.txt es mejor para bloquear el acceso y el rastreo de subdirectorios completos que para páginas individuales. Úselo para bloquear el acceso y la indexación de los rastreadores de búsqueda:
- Páginas de búsqueda interna
- parámetros de URL
- Foros donde el spam generado por el usuario puede causar problemas
- Subdirectorios internos, como los que son solo para empleados
Siga estos pasos para crear un archivo robots.txt y asegúrese de vincularlo a su mapa del sitio XML.
Si vincula a una página incluida en su archivo robots.txt, es posible que también desee agregarle una metaetiqueta de robots para asegurarse de que no aparezca en los resultados de búsqueda. Recuerde: robots.txt solo impide que los rastreadores accedan a una página, no que la indexen. Si las páginas cubiertas por sus directivas de robots.txt reciben enlaces externos, los motores de búsqueda pueden indexarlos. Utilice una metaetiqueta de robots junto con el archivo robots.txt para evitar esto.
Etiqueta X-Robots
Para bloquear la aparición de un PDF, un video o una imagen en las SERP, use una etiqueta de x-robots. Las mismas directivas especificadas para las etiquetas meta de robots se utilizan para x-robots. Sin embargo, a diferencia de la metaetiqueta robots, que se encuentra en el encabezado HTML de una página, se coloca una etiqueta x-robots en la respuesta del encabezado HTTP.
La directiva se ve así:
X-Robots-Tag: noindexCuándo no indexar una página
Inflación del índice de bordillo
La hinchazón del índice ocurre cuando Google indexa páginas con poco o ningún valor para los buscadores. Estas páginas superfluas restan recursos a las páginas más valiosas. Use una metaetiqueta de robots para administrar qué páginas aparecen en los resultados de búsqueda.
Erradicar la canibalización de palabras clave
La canibalización de palabras clave ocurre cuando dos páginas comparten una palabra clave y una intención de búsqueda similares, lo que hace que compitan entre sí en las SERP.
Si tienes dos páginas canibalizándose entre sí y quieres mantener ambas sin cambiar su contenido, noindex one. Dicho esto, solo debe hacer esto si la página que no está indexando no genera tráfico de palabras clave que la otra página no genera. En una situación como esta, es posible que deba volver a trabajar en el contenido de una o ambas páginas para resolver el problema de canibalización.
Proteja las páginas de destino cerradas
Cuando ofrezca un recurso de gran valor a los clientes a cambio de información de contacto, asegúrese de que no sea accesible de ninguna otra forma. Agregue una metaetiqueta de robots para no indexar la página y evitar que aparezca en los SERP.
Excluir productos impopulares de la búsqueda
Los sitios de comercio electrónico a menudo ofrecen productos para servir a ciertos clientes, aunque no haya demasiada demanda para ellos. Por ejemplo, un minorista de autopartes u otra empresa técnica puede tener productos para modelos particulares o equipos raros. Si estas páginas de productos o categorías no generan tráfico orgánico, generalmente no se pueden indexar.
Cómo no indexar una página web
La metaetiqueta noindex va en el encabezado del HTML de una página. El código no distingue entre mayúsculas y minúsculas y se ve así:
<meta name="robots" content="noindex">"Robots" significa que la directiva se aplica a cualquier rastreador, pero puede identificar rastreadores reemplazando "robots" con nombres de rastreadores conocidos, como "Googlebot" o "bingbot".

Los rastreadores seguirán los enlaces en la página a menos que también agregue un comando nofollow. Puede hacer esto para evitar que la equidad de los enlaces fluya a través de la página o para evitar que un rastreador siga un enlace a contenido restringido.
Para agregar un valor nofollow, sepárelo de la directiva noindex con una coma.
<meta name="robots" content="noindex, nofollow">Nota: antes de no indexar una página, verifique si tiene tráfico orgánico entrante en Google Search Console. Si es así, determine cómo su sitio puede continuar capturando este tráfico antes de no indexar la página.
Cómo agregar una metaetiqueta de robots a su código HTML
- Abra el código fuente de la página que desea no indexar.
- Busque el encabezado en la parte superior de la página. Comienza con <head> y termina con </head>. Es probable que también haya otro código en el encabezado.
- Agregue la metaetiqueta de robots en una nueva línea, asegurándose de que aparezca entre las etiquetas <head> y </head>.
¡Eso es todo! Si su página ya está indexada, puede pedirle a Google que la vuelva a rastrear pegando su URL en la herramienta de inspección de URL.
¿Ya está indexado? Utilice la herramienta de eliminación de URL
Cuando agrega una etiqueta noindex a una nueva página de contenido, Googlebot verá la directiva cuando rastree la página y no la indexará.
Sin embargo, si agrega la etiqueta a una página que ya está indexada , la página seguirá apareciendo en los resultados de búsqueda hasta que se vuelva a rastrear y los bots vean las nuevas instrucciones de no indexación. Puede pedirle a Google que vuelva a rastrear la URL en Google Search Console a través de la Herramienta de inspección de URL, pero no eliminará instantáneamente la página de las SERP.
Si necesita eliminar una página de SERP inmediatamente, use la herramienta Eliminaciones en Google Search Console. Esto mantendrá las páginas fuera de los resultados de búsqueda de Google durante unos seis meses. Para entonces, la etiqueta meta noindex debería funcionar.
Cómo no indexar una página en WordPress
Cada página en WordPress está indexada por defecto. Puede usar el complemento Yoast SEO para no indexar una página en WordPress sin escribir código. Así es cómo.
Haga clic en la pestaña 'Avanzado' en el cuadro meta de Yoast SEO.
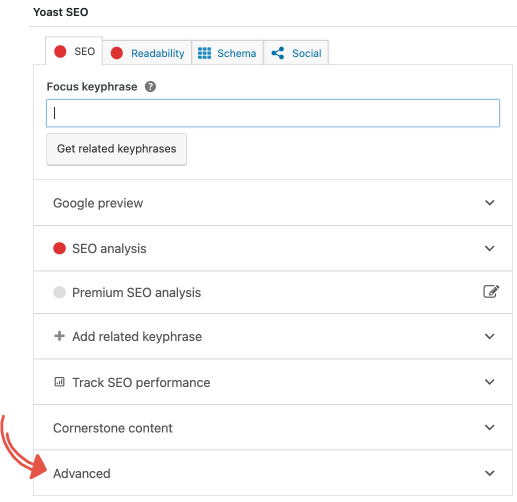
Debajo de la pregunta, "¿Permitir que los motores de búsqueda muestren esta publicación en los resultados de búsqueda?" seleccione 'No' en el cuadro desplegable.
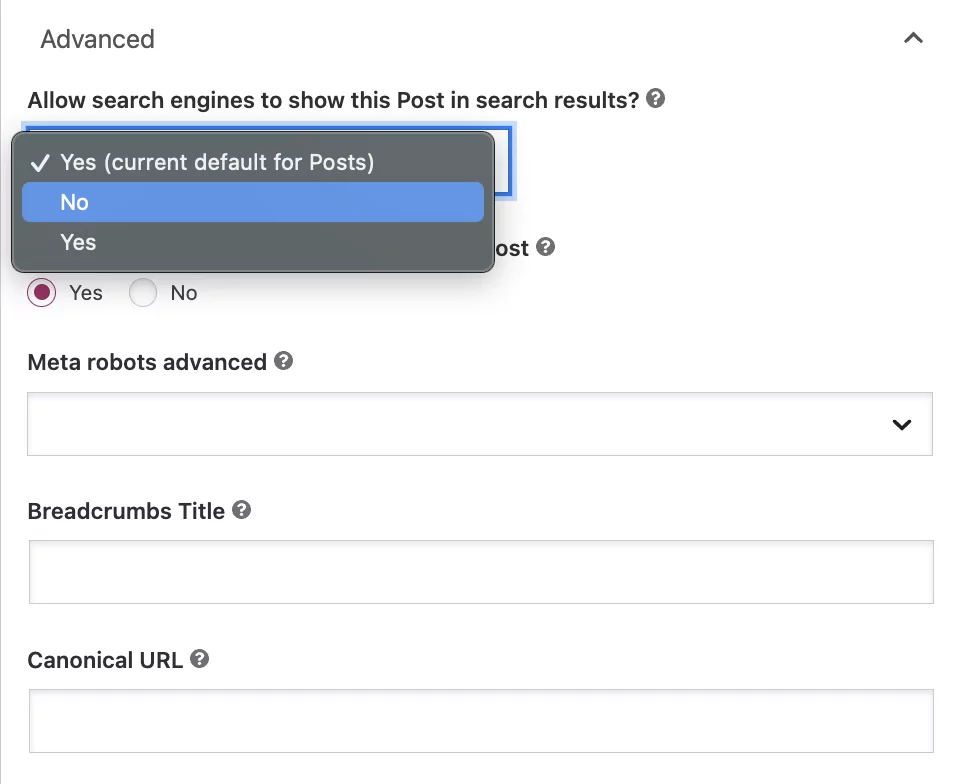
Si bien esta configuración le indica a Google que no indexe la publicación, los bots seguirán automáticamente los enlaces en la página para rastrear otras páginas.
Si desea agregar una directiva de no seguimiento, seleccione el botón 'No' debajo de la pregunta: '¿Deberían los motores de búsqueda seguir los enlaces en esta publicación?'
Preguntas frecuentes sobre la metaetiqueta Robots
¿Todos los motores de búsqueda obedecen una directiva noindex?
Puede esperar que Google, Bing y otros motores de búsqueda legítimos cumplan con una metaetiqueta de robots.
¿Puedo enlazar a páginas no indexadas?
Sí. La etiqueta noindex les dice a los robots de búsqueda cómo tratar una página cuando rastrean e indexan. No afecta su capacidad para vincular a una página. Esto puede ser útil para las páginas de categorías en un blog, que no deberían aparecer en los resultados de búsqueda pero pueden proporcionar a los bots enlaces a páginas valiosas que deberían.
¿Cuándo debo usar una metaetiqueta de robots?
Si tiene una página que no ofrece ningún valor a los buscadores, como una página de agradecimiento o una página fácil de imprimir, no indexe con una metaetiqueta de robots para evitar que aparezca en los SERP.
¿Cuándo no debería usar una directiva noindex?
Puede resolver técnicamente problemas de contenido duplicado y algunos problemas de presupuesto de rastreo con directivas noindex, pero esta no es la mejor manera de hacerlo. El contenido duplicado se maneja mejor usando etiquetas canónicas, que concentran la equidad del enlace de los duplicados en la página canónica. Si intenta conservar el presupuesto de rastreo, debe usar el archivo robots.txt para prohibir el rastreo de esa sección del sitio.
¿Las páginas no indexadas pasan la equidad de enlace?
Sí. Aunque una página no esté indexada, aún puede compartir cualquier autoridad de clasificación creada. Sin embargo, los rastreadores de búsqueda deben tener la capacidad de seguir los enlaces en la página para que fluya la equidad de los enlaces. Si una página está configurada en noindex y nofollow, no puede pasar la equidad del enlace.
¿No indexar una página la elimina automáticamente de las SERP de Google?
Si su página ya está indexada, agregar una metaetiqueta de robots no la eliminará automáticamente de los resultados de búsqueda. Las páginas que ya están indexadas tardan un tiempo en desaparecer de las SERP. Los robots de búsqueda necesitan volver a rastrear las páginas para ver la etiqueta noindex. Para obtener resultados más rápidos, solicite que Google vuelva a rastrear la página y use la herramienta de eliminación de URL.
Descubre páginas problemáticas con una auditoría SEO
No permita que el contenido reducido o duplicado afecte su visibilidad de búsqueda. Asegúrate de darle a tus páginas la mejor oportunidad de clasificarse. Nuestra auditoría de SEO de más de 200 puntos señala problemas como contenido duplicado, un archivo robots.txt faltante, metaetiquetas de robots mal aplicadas, índice hinchado y más. Regístrese para una consulta de SEO gratuita para ver cómo nuestro servicio de auditoría de SEO puede maximizar su visibilidad en línea y ayudar a que su negocio crezca.