
Gráfico de conocimiento Respuesta a preguntas
Publicado: 2023-01-25¿Qué es la función de respuesta a preguntas del gráfico de conocimiento de Google?
La respuesta a preguntas de gráficos de conocimiento (KGQA) está ocupando mucho espacio en las páginas de resultados de los motores de búsqueda (SERP).
La función de respuesta a preguntas Knowledge Graph de Google responde a las consultas de los usuarios sin necesidad de que hagan clic en un sitio web.
Cada motor de búsqueda espera devolver la mejor información basada en la intención del buscador. Para ser una fuente confiable de respuestas, debe ser conocido en línea. Google entiende los flujos de consultas y los usa para identificar temas y extraer datos confiables de la web para actualizar ontologías. Las tarjetas de Google, los gráficos de conocimiento (KG) y las colecciones de conocimiento son una forma en que los usuarios interactúan con Google. Al igual que "la gente también hace" preguntas en los resultados de búsqueda, las respuestas a las preguntas de Knowledge Graph mantienen a las personas en las SERP de Google por más tiempo.
Tabla de contenido
- ¿Qué es la función de respuesta a preguntas del gráfico de conocimiento de Google?
- ¿Cuál es la diferencia entre paneles de conocimiento y gráficos de conocimiento?
- ¿Cuál es la diferencia entre los paneles de conocimiento y los perfiles comerciales de Google?
- ¿Cuál es la diferencia entre el panel de conocimientos de Google y la bóveda de conocimientos?
- Responder preguntas complejas con aprendizaje automático
- Cómo crear contenido de respuesta a preguntas que Google encuentre útil
- Los gráficos de conocimiento responden preguntas relacionadas con datos
- Pasos para la optimización de respuestas de preguntas de KG
- ¿Cómo solicitar una actualización del panel de conocimientos de Google?
- Los KG de respuesta a preguntas buscan proporcionar conocimiento verificado
Primero establezcamos un vocabulario fundamental.
¿Cuál es la diferencia entre paneles de conocimiento y gráficos de conocimiento?
Los gráficos de conocimiento se pueden obtener para proporcionar paneles de conocimiento más completos en los resultados de búsqueda y devolver respuestas a las consultas.
Es útil ver los Paneles de conocimiento como una manifestación frontal del Gráfico de conocimiento de Google. Hay más datos detrás de lo que vemos en los datos del gráfico de panel. Una vez que establezca una entidad de Knowledge Graph, Google se basará en ella y la considerará una fuente canónica de información. El gigante tecnológico no inventó el KG como un complemento a las experiencias de los usuarios de escritorio; fue una respuesta a la necesidad de mejores respuestas de consultas móviles. Muchos sitios eran (y siguen siendo) horribles en dispositivos móviles. El GKG tiene la intención de proporcionar información precisa a su usuario; su objetivo principal no es atraer tráfico a su sitio.
Anteriormente, Google no parece clasificar las páginas web en función de la precisión. Hoy, sus evaluadores de calidad tienen más instrucciones sobre cómo evaluar la experiencia, la pericia, la autoridad y la confiabilidad (EEAT). La precisión de las respuestas es un factor de confianza, y sus pautas nos dicen que la confianza es el factor más importante. Por el contrario, la "precisión" es un factor en el que las entidades se muestran en los paneles de conocimiento.
Los paneles de conocimiento son un tipo de resultados enriquecidos en las páginas de resultados de búsqueda de Google. Brindan a los buscadores una descripción general examinada de la información relacionada con una entidad determinada.
¿Cuál es la diferencia entre los paneles de conocimiento y los perfiles comerciales de Google?
Google Business Profiles (GBP) se parece mucho a sus paneles de conocimiento. Los GBP son exclusivos de las empresas que atienden a los clientes en una ubicación particular o dentro de un área de servicio designada. El acceso a GBP permite a los dueños de negocios administrar su presencia digital en Google Maps y realizar búsquedas. Esto es gratis. Por el contrario, Google genera automáticamente su panel de conocimiento de Google (GKP) utilizando información sobre su entidad en línea. Tiene control total sobre su propagación y lo que elige actualizar dentro de él.
¿Cuál es la diferencia entre el panel de conocimientos de Google y la bóveda de conocimientos?
Piense en Google Knowledge Vault (GKV) como producido por un algoritmo que genera una enciclopedia legible por máquina.
Google solo agrega información a su GKV una vez que está seguro de que lo que muestra en los Paneles de conocimiento es correcto y útil. El GKV se basa únicamente en el aprendizaje automático y la lógica de la máquina. Las entidades separadas de múltiples dominios se mueven a Knowledge Vault solo después de que el algoritmo de conocimiento global de Google obtenga suficiente confianza en su comprensión de la entidad especificada.
“…presentamos Knowledge Vault, una base de conocimiento probabilística a escala web que combina extracciones de contenido web (obtenido a través del análisis de texto, datos tabulares, estructura de página y anotaciones humanas) con conocimiento previo derivado de repositorios de conocimiento existentes. Empleamos métodos de aprendizaje automático supervisados para fusionar estas distintas fuentes de información. Knowledge Vault es sustancialmente más grande que cualquier depósito de conocimiento estructurado publicado anteriormente y cuenta con un sistema de inferencia probabilística que calcula probabilidades calibradas de corrección de hechos”. – Bóveda de conocimiento: un enfoque a escala web para la fusión de conocimiento probabilístico [1]
Responder preguntas complejas con aprendizaje automático
Google recibe el 93% de las consultas diarias. Así funciona tradicionalmente como un motor de búsqueda y termina en su producto o servicio. Para mejorar sus capacidades de respuesta a preguntas, una patente de Google establece que: "El procesamiento del lenguaje natural (NLP) puede implicar responder preguntas en lenguaje natural basadas en la información contenida en los documentos en lenguaje natural".
“Las técnicas descritas permiten responder una pregunta en lenguaje natural utilizando métodos basados en aprendizaje automático para recopilar y analizar evidencia de búsquedas en la web”. – [2]
Sin embargo, antes de agregar entidades a su base de conocimiento, Google primero debe comprender algorítmicamente la pregunta que se le hace. Busca comprender la intención de consulta que desencadenó la pregunta. Para consultas ambiguas, la interpretación semántica ayuda a responder preguntas complejas y busca replicar la cognición humana. Los artículos web a menudo no muestran una fecha de publicación o cuándo se actualizó por última vez. Por el contrario, Knowledge Graph de Google se actualiza continuamente. Por ejemplo, estaba a punto de citar un artículo para este escrito, pero primero investigué y vi "Este artículo tiene más de 3 años".
MarketWatch estima que "la industria de la base de conocimiento semántico tendrá un valor de $ 33 mil millones para 2023, con un crecimiento anual del 10% durante el resto de la década". Su 18 de enero de 2023, se espera que el tamaño del mercado de gráficos de conocimiento semántico relacionado con el tiempo y el costo haga crecer la industria en los próximos años hasta 2029 El artículo incluye búsqueda semántica, máquina de preguntas y respuestas y recuperación de información.
Es alucinante cuánto aumento en la innovación científica se dedica a mejores KG. Del mismo modo, los especialistas en marketing digital y los SEO se benefician al adaptarse rápidamente.
Los KG generalmente se ven como redes semánticas a gran escala que almacenan hechos como triples en forma de (entidad de sujeto, relación, entidad de objeto) o (entidad de sujeto, atributo, valor). Los bordes del gráfico representan las relaciones entre estas entidades. La mayoría de los KG se construyen sobre diferentes fuentes de datos existentes para conectar datos. Hasta que GPTChat surgió dentro de GPT3, Google no se vio amenazado por otros KG a gran escala, como DBpedia, Freebase y YAGO.
El impulso para obtener respuestas a preguntas más humanas
La competencia es a una escala sin precedentes entre Goole, OpenAI, Bing y otros para brindar respuestas más humanas a las preguntas en lugar de solo enlaces a la información. Google usa y prueba continuamente varios modelos de lenguaje de IA grandes para mejorar su motor de búsqueda y sus paneles de conocimiento.
El término 'gráfico de conocimiento' tiene una amplia familia relacional; incluye los campos de gráficos de conocimiento, bases de datos de gráficos, bóvedas de conocimiento, paneles de conocimiento, redes neuronales, aprendizaje automático, NLP, inteligencia artificial, datos vinculados, incrustación de gráficos de conocimiento, transferencia de conocimiento, aprendizaje de transferencia, aprendizaje de representación de conocimiento (KRL) y más ! Gastar dinero en búsquedas pagas y mejoras triviales en el rendimiento del sitio palidece en comparación con llenar efectivamente los vacíos de contenido de preguntas y respuestas. Las siguientes sugerencias provienen de mi propia experiencia.
Los sistemas basados en datos de la empresa se evalúan para generar confianza en el enfoque científico y sus aplicaciones. Sus capacidades de respuesta a preguntas (QA) de Knowledge Graph (KG) se basan en estructuras de datos complejas a las que se puede acceder a través de interfaces de lenguaje natural.
Cómo crear contenido de respuesta a preguntas que Google encuentre útil
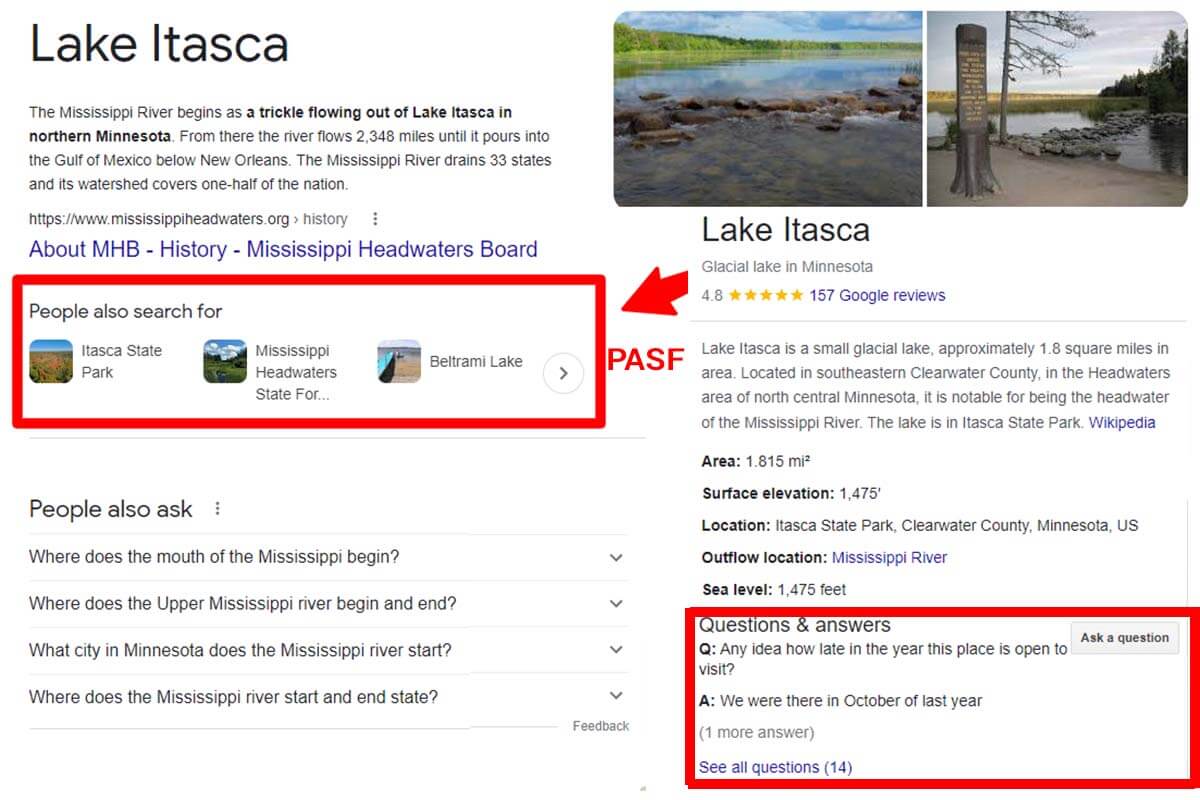
El nuevo SEO entiende que Google es una especie de motor de respuestas y lo alimenta.
Cuanto más publique datos de verificación, más datos podrá conectar el gigante tecnológico. De esta forma, facilitas el trabajo de un buscador en la comprensión de cuáles son los datos sobre tu entidad. Usted proporciona ayuda cuando conecta sus propios datos estructurados con todos los diferentes terceros que hablan de usted. Google no tiene preferencia si la implementación de datos estructurados está conectada a través de un gráfico o una matriz de nodos en lugar de tenerlos como elementos individuales en sus propios bloques en la página.
- Contenido de preguntas frecuentes: su empresa puede crear bases de datos marcadas con un esquema para ayudar a Google a rastrear e incorporar páginas informativas de preguntas y respuestas. Google puede optar por obtener el contenido de preguntas frecuentes de su sitio web.
- Grupos de temas del sitio web: la información con una ontología clara se puede utilizar para indicar la experiencia en el tema. Los gráficos de conocimiento organizan entidades utilizando datos web en los que Google confía. Puede ser la fuente principal en diferentes conjuntos de datos. De esta manera, eres un editor de datos. Si ha reclamado su panel de conocimiento, puede ser una forma más confiable y rápida de activar una actualización del panel de conocimiento.
- Base de datos de productos precisa: siempre que haga un trabajo impecable al mantener actualizada la base de datos de productos, está ayudando a Google a obtener una gran confianza en los datos de sus productos. Google tiene más confianza para mostrar a sus usuarios información precisa y relevante si su marca y productos en línea son claros y consistentes. Sea coherente con todo cuando se trata de su presencia en línea. Ir por la misma ortografía, título, biografía del autor, lugar de trabajo, etc.
- Cargue conjuntos de datos de imágenes: las imágenes que salen de esa base de datos en particular se pueden asociar con sus respuestas y completar su gráfico de conocimiento. La existencia y precisión de sus conjuntos de datos de control de calidad de productos ayudan a garantizar la comparabilidad.
- Use el marcado de esquema FactClaim: los resultados de búsqueda de Google a menudo se extraen de su repositorio Knowledge Graph de miles de millones de datos sobre personas, lugares y cosas. Al incluir contenido fáctico y estadístico que respalde sus artículos de opinión, demuestra su conciencia y conocimiento de fuentes relevantes basadas en hechos.
- Nombre, dirección y teléfono coherentes: hay más formas de administrar su perfil comercial de Google a partir de 2023. Sin embargo, su NAP es fundamental para la forma en que Google identifica su entidad. Lo mejor es tener una dirección estable y usar la asignada en Google Maps. Los gráficos de conocimiento se relacionan estrechamente con Google Maps. Se basa en datos estructurados, información estructurada en forma de consistencia NAP: nombre, dirección, número de teléfono y cómo marcan la diferencia para asegurarse de que Google Maps se actualice. El mismo tipo de consistencia suministra el GKG.
- Respuestas automáticas de texto a las preguntas frecuentes del perfil comercial de Google: puede agregar respuestas automáticas a las preguntas frecuentes directamente en su perfil comercial de Google. Funciona como una conversación bidireccional automatizada con respuesta a preguntas.
- Incorpore una estrategia efectiva de Google Post: los autores de Google Scholar, las marcas notables y los funcionarios electos de EE. UU. no están aprovechando la oportunidad de reclamar sus Paneles de conocimiento. Esto, a su vez, les brinda acceso a Google Posts, que debería ser parte de su estrategia de gráficos de conocimiento para el contenido.
- Utilice los datos de la audiencia y la investigación de mercado: la investigación de mercado inicial proporciona información sobre los datos de la audiencia que pueden impulsar campañas de contenido innovadoras y estrategias de KG. Una base de conocimiento primero clasifica las preguntas en función de cuán "significativas" son en relación con la intención de consulta de las personas.
Más información sobre el uso de datos estructurados en su sitio web:
Ryan Levering de Google, que trabaja principalmente con datos estructurados, declaró en Mastodon: “Cualquiera que sea el aspecto del gráfico para toda la página es lo que usamos, independientemente de su procedencia. Se mezcla y, aunque sé de dónde vino, no se suele usar. Sin embargo, la advertencia aquí es que cuando lo hace en varios bloques, a veces hay problemas de conflicto/duplicación. Además, con el tiempo, una semántica más rica/correcta favorecerá gráficos más conectados. Todavía vemos casos en los que las personas arrojan marcas no relacionadas sobre cosas (como productos relacionados) en el mismo nivel superior que la entidad principal de diferentes bloques en la página y eso hace que sea ruidoso. Entonces, a veces, centralizar la lógica la hace más consistente/correcta”.

Los gráficos de conocimiento responden preguntas relacionadas con datos
Un objetivo de los gráficos es la capacidad de funcionar como la verdad fundamental de la terminología, la lógica y las respuestas correctas.
Aquí hay una cita directamente de Google sobre cómo funciona su Knowledge Graph.
“Los resultados de búsqueda de Google a veces muestran información que proviene de nuestro Knowledge Graph, nuestra base de datos de miles de millones de datos sobre personas, lugares y cosas. El gráfico de conocimiento nos permite responder preguntas fácticas como "¿Qué altura tiene la Torre Eiffel?" o "¿Dónde se celebraron los Juegos Olímpicos de verano de 2016?". Nuestro objetivo con Knowledge Graph es que nuestros sistemas descubran y muestren información fáctica conocida públicamente cuando se determine que es útil”. – Cómo funciona el gráfico de conocimiento de Google
Puede alimentar su Knowledge Graph con información que demuestre relaciones y conceptos conectados entre sí. Si bien se están realizando grandes inversiones en inteligencia artificial de chatbot, actualmente sabemos que necesita un modelo de dominio para comprender y responder preguntas. El aprendizaje automático puede generar una gran base de conocimiento de oraciones y casos de uso, pero un chatbot estático tiene limitaciones.
Google recopila información sobre un tema o tema en particular para establecer primero la confianza antes de que se actualice una entrada del Gráfico de conocimiento de datos. Los gráficos nos ayudan a responder preguntas relacionadas con los datos para que Google pueda almacenar y recuperar información fácilmente. Básicamente se trata de comprender las preguntas, conectar las preguntas a su gráfico de conocimiento e inferir las respuestas.
Pasos sugeridos para la optimización de respuestas de preguntas de KG:
- Busque qué, quién, dónde, por qué y también cómo las publicaciones que controla.
- Identifique qué datos internos de control de calidad pueden obtenerse externamente.
- Aprende dónde encontrarlo.
- Aprenda cómo ya se está utilizando, por quién, cómo se puede utilizar y por qué.
- Utilice gráficos para identificar cómo proporcionar más valor mediante el análisis de sus grupos, cohortes y grupos.
- Configure alertas para ayudar a monitorear las señales de datos de control de calidad relacionadas con el contexto, las señales de grupo y la dinámica dentro y con las relaciones de su entidad.
- Programe el tiempo de mantenimiento para administrar y alimentar el contenido de control de calidad de su gráfico.
El procesamiento del lenguaje natural y la gestión de la alineación de gráficos facilitan la búsqueda de casos de entidades conflictivas o definiciones de relaciones. Los paneles, los gráficos y la bóveda de Google tienen que ver con la resolución de entidades.
Antes de responder una pregunta en una plataforma que usted controla, primero comprenda inteligentemente la pregunta. Debe conocer la intención del buscador y la información clave necesaria para la pregunta. Los motores de búsqueda extraen información clave al buscar entidades nombradas que son útiles para la inclusión de gráficos de conocimiento. Para fiarse de ellos mismos, son selectivos antes de inferir la respuesta en el KG.
¿Cómo solicitar una actualización del panel de conocimientos de Google?
Google proporciona a los propietarios de Knowledge Graph reclamados una forma de solicitar actualizaciones e informar problemas. Es más fácil una vez que ha adquirido la capacidad de proporcionar comentarios directos. Sus respuestas instantáneas se actualizan periódicamente a partir del rastreo de la web y los comentarios de los usuarios.
“También sabemos que las entidades cuya información se incluye en los paneles de conocimiento (como personas destacadas o los creadores de un programa de televisión) tienen autoridad por sí mismas, y proporcionamos formas para que estas entidades proporcionen comentarios directos. Por lo tanto, parte de la información que se muestra también puede provenir de entidades verificadas que han sugerido modificaciones a los hechos en sus propios paneles de conocimiento. – Acerca de los paneles de conocimiento
"También recibimos información fáctica directamente de los propietarios de contenido de varias maneras, incluso de aquellos que sugieren cambios en los paneles de conocimiento que han reclamado". – Cómo funciona el gráfico de conocimiento de Google
Muchos consideran que los beneficios clave de obtener un gráfico de conocimiento semántico son que brinda claridad de marca, recuperación de datos y experiencias de ventas. Pero dado que muchas personas hacen preguntas, también es importante considerar su capacidad para integrar datos y usarlos para brindar respuestas. ¿Qué no será el minorista que se muestra valioso de esta manera?
¿Cómo funciona la recuperación de información de respuestas a preguntas?
Google reúne el contenido del clúster de preguntas de fuentes de las que puede estar seguro.
2023 es la era de mejorar su estrategia de gráficos de conocimiento a medida que más y más conversiones de clientes potenciales se realizan directamente en las páginas de resultados del motor de búsqueda (SERP). Google evalúa en qué puede confiar acerca de su entidad y elige qué se incluirá en su Knowledge Graph, Knowledge Panels y Knowledge Vault. Conoce a su público objetivo y clientes; busca alinear sus fortalezas y conocimientos en la web para brindar las mejores respuestas. La investigación de audiencia y el análisis SERP pueden informar su enfoque de marketing.
Cuando Google extrae información de la entidad de control de calidad de las páginas web, se determinan los puntajes de asociación que involucran a esas entidades y sus relaciones con otras entidades. Se preocupa mucho por las respuestas fácticas que describen las propiedades de esas entidades. Una vez que haya determinado su mejor estrategia de marketing, es hora de pasarla a las tácticas de marketing, donde ha tomado acciones de marketing específicas para mejorar sus resultados SERP. Tanto hoy como aún más en el futuro, comprender la recuperación de información de control de calidad y cómo informar a sus KG es un componente vital de un SEO efectivo.
Aprendemos de las patentes de Google cómo un modelo de procesamiento de lenguaje natural puede responder una pregunta de texto en lenguaje natural.
“Un sistema informático incluye un modelo de procesamiento de lenguaje natural aprendido por máquina que incluye un modelo de codificador capacitado para recibir un cuerpo de texto en lenguaje natural y generar un gráfico de conocimiento y un modelo de programador capacitado para recibir una pregunta en lenguaje natural y generar un programa. El sistema informático incluye un medio legible por computadora que almacena instrucciones que, cuando se ejecutan, hacen que el procesador realice operaciones. Las operaciones incluyen obtener el cuerpo del texto en lenguaje natural, ingresar el cuerpo del texto en lenguaje natural en el modelo del codificador, recibir, como salida del modelo del codificador, el gráfico de conocimiento, obtener la pregunta en lenguaje natural, ingresar la pregunta en lenguaje natural en el modelo del programador , recibir el programa como resultado del modelo del programador y ejecutar el programa en el gráfico de conocimiento para generar una respuesta a la pregunta del lenguaje natural”. – Procesamiento del lenguaje natural con una máquina N-Gram, número de patente: WO2019083519A1, fecha de publicación: 2 de mayo de 2019 [3]
Puntuación de relevancia del gráfico de conocimiento
Combine aprendizaje de lenguaje de máquina y gráficos de datos para conectar el contexto de la pregunta de la audiencia con sus respuestas. La puntuación de relevancia de Google KG utiliza LM preentrenado para puntuar nodos en KG acondicionados para una respuesta a una pregunta. Google tiene un marco general para ponderar la información dentro de sus KG. Su aprendizaje automático utiliza razonamiento conjunto sobre texto y KG. De esta manera, conecta el contexto de las preguntas con el contenido de las respuestas mediante el uso de LM y redes neuronales gráficas.
En general, los KG de Google son más eficientes y confiables que las páginas web. Entonces, ¿adónde va esto?
Los KG de respuesta a preguntas buscan proporcionar conocimiento verificado
Google Knowledge Graph proporciona respuestas directas a las consultas
Los datos proporcionados por Google Knowledge Graph en respuesta a una consulta se derivan inicialmente de otras fuentes. (Hasta hace poco, esto era en gran parte de Wikipedia y Wikidata). Google se esfuerza por confiar en toda la información que contiene sus KG. Debe ser un desafío satisfacer las consultas con precisión. Por ejemplo, para responder "¿Quiénes fueron los fundadores de Google?", el Knowledge Graph necesita extraer un triple (sujeto-predicado-objeto) aquí a lo largo de las líneas de "[Organización] fundada por [Persona(s)]".
Wikipedia y Wikidata proporcionan información precisa como esa.
Aaron Bradly, estratega de Knowledge Graph en Electronic Arts, planteó una pregunta fascinante en Twitter hace unos años. "A saber, una pregunta subyacente más importante es si debemos considerar que los 'hechos' proporcionados por Google Knowledge Graph son objetivamente correctos (y si Google mismo considera que los 'hechos' proporcionados por Graph son objetivamente correctos)".
Uno puede ver rápidamente por qué los usuarios deben confiar en las "respuestas" y los "hechos" proporcionados por Knowledge Graph.
Bradley continúa diciendo: “Entonces, Graph necesita apoyarse en la confiabilidad de sus fuentes para determinar qué afirmaciones hacer. Tanto es así que Google ha reflexionado sobre métodos para mejorar la forma en que determinan la confiabilidad de una fuente. En última instancia, la afirmación proporcionada es 'de algún lugar'. Y esto se vuelve problemático cuando la carga útil de una respuesta (especialmente la voz) no incluye información de procedencia. Tanto los agregadores de conocimiento (aquí Google) como los usuarios de conocimiento (aquí buscadores) deben trabajar para mejorar la forma en que procesamos estas preguntas y respuestas”. [4]
Larry Page y Sergey Brin, los fundadores de Google, resurgieron después de su partida en 2019 para revisar la estrategia de productos de inteligencia artificial de Google. Aprobaron planes y presentaron ideas para agregar nuevas funciones de chatbot en el motor de búsqueda de Google. Los despidos masivos de personal de Google en enero de 2023 siguen a su compromiso renovado de poner la IA al frente y al centro de sus planes. [5]
Puede utilizar la API de búsqueda de Google Knowledge Graph para buscar entidades en Google Knowledge Graph. Google Cloud ofrece el siguiente ejemplo de código de marcado de esquema: [6]
{
"@contexto": {
"@vocab": "http://schema.org/"
},
"@type": "Lista de elementos",
"elementoListaElemento": [
{
"resultado": {
"@id": "c-07xuup16g",
"nombre": "Universidad de Stanford",
"description": "Universidad privada en Stanford, California",
"Descripción detallada": {
"articleBody": "Stanford University, oficialmente Leland Stanford Junior University, es una universidad privada de investigación en Stanford, California. El campus ocupa 8,180 acres, uno de los más grandes de los Estados Unidos, e inscribe a más de 17,000 estudiantes".,
"url": "https://en.wikipedia.org/wiki/Stanford_University",
"licencia": "https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License"
},
"url": "http://www.stanford.edu/",
"imagen": {
"contentUrl": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcTfPPf-ker0y_892m1wu8-U89furQgQ67foDFncY3r9sREpeWxV",
"url": "https://es.wikipedia.org/wiki/Archivo:Logo_of_Stanford_University.png"
},
"identificador": [
{
"@tipo": "Valor de la propiedad",
"ID de propiedad": "googleKgMID",
"valor": "/m/06pwq"
},
{
"@tipo": "Valor de la propiedad",
"ID de propiedad": "ID de lugar de Google",
"valor": "ChIJneqLZyq7j4ARf2j8RBrwzSk"
},
{
"@tipo": "Valor de la propiedad",
"ID de propiedad": "wikidataQID",
"valor": "Q41506"
}
],
"@escribe": [
"Lugar",
"Organización",
"Cine",
"Corporación",
"Organización Educativa",
"Cosa",
"Colegio o universidad"
]
}
}
]
}
Creemos que implementar el marcado de esquema es extremadamente útil. Si tiene el doble, lea nuestros pros y contras de agregar el artículo de marcado de datos estructurados.
Llevando su búsqueda semántica y GKG adelante
Si este artículo aumenta su conocimiento de la tecnología de gráficos y búsqueda semántica y ahora está ansioso por responder a tales oportunidades, llame a Jeannie Hill al 651-206-2410.
Potencia tu gráfico de conocimiento personal o empresarial ganando nuestra Auditoría de Entidades de Consultas
Referencias:
[1] https://research.google/pubs/pub45634/
[2] https://patents.google.com/patent/WO2014008272A1/en
[3] https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2019083519
[4] https://mobile.twitter.com/aaranged/status/1108444732282163200
[5] https://searchengineland.com/google-search-chatbot-features-this-year-391977
[6] https://cloud.google.com/enterprise-knowledge-graph/docs/search-api