
¿Qué es la agrupación de conmutación por error? Cómo funciona + Soluciones
Publicado: 2023-09-22Las empresas que necesitan transacciones en línea no pueden permitirse averías en los servidores. Como resultado, estas empresas buscan formas de crear un procedimiento a prueba de fallos que mantenga sus datos seguros incluso si el servidor colapsa. Uno de esos métodos es la agrupación en clústeres de conmutación por error.
La agrupación en clústeres de conmutación por error puede estar gobernada por soluciones de proveedores de sistemas de nombres de dominio (DNS) administrados; sin embargo, comprender su mecanismo y sus características clave puede ayudar a limitar cualquier desafío de conmutación por error.
¿Qué es la agrupación de conmutación por error?
La agrupación de conmutación por error opera en un grupo de servidores informáticos para garantizar alta disponibilidad (HA) o disponibilidad continua (CA) para las aplicaciones del servidor. Esta tecnología garantiza que si falla un servidor o nodo, otro nodo del clúster esté listo para asumir la carga de trabajo sin interrupciones.
Este enfoque mantiene las cargas de trabajo de su servidor escalables y disponibles. Muchos programas de servidor importantes, como Microsoft Exchange , Microsoft SQL Server y Hyper-V , dependen de clústeres de conmutación por error para protegerse.
Algunos clústeres de conmutación por error emplean servidores físicos, mientras que otros utilizan máquinas virtuales (VM) . Cada uno selecciona el tipo de clúster que necesita en función de los requisitos de su aplicación de servidor.
Un clúster consta de dos o más nodos que intercambian datos y software para procesarlos a través de cables físicos o una red segura especializada. Se puede utilizar tecnología de agrupación en clústeres de varios tipos para equilibrio de carga, almacenamiento y computación simultánea o paralela. En algunos casos, los clústeres de conmutación por error se combinan con tecnologías de agrupación adicionales.
La función principal de un clúster de conmutación por error es proporcionar CA o HA para aplicaciones y servicios. Los clústeres de CA, también conocidos como clústeres tolerantes a fallas (FT), permiten a los usuarios finales continuar usando aplicaciones y servicios incluso si falla un servidor. Es posible que vea una breve interrupción en el servicio causada por los clústeres HA, pero el sistema puede recuperarse sin pérdida de datos y con poco tiempo de inactividad.
¿Por qué es importante la agrupación en clústeres de conmutación por error?
Con la agrupación de conmutación por error, puede reparar nodos inactivos sin cerrar su base de datos, evitando problemas de tiempo de inactividad y reparando rápidamente servidores averiados. Además, en caso de falla del hardware, esta técnica finaliza la base de datos para proteger los nodos activos.
La agrupación en clústeres de conmutación por error también automatiza la recuperación de datos en caso de fallo. Esto reduce su dependencia del equipo de tecnología de la información (TI) y permite que sus servidores se recuperen rápidamente. También ofrece una excelente disponibilidad de clústeres de lenguaje de consulta estructurado (SQL) con un tiempo de inactividad mínimo. La funcionalidad de conmutación por error automatizada de la agrupación de conmutación por error preserva la función de su base de datos, incluso si hay una avería en el hardware.
¿Cómo funcionan los clústeres de conmutación por error?
La agrupación de conmutación por error consta de dos procesos fundamentales, HA y CA, para aplicaciones de servidor.
Mientras que los clústeres de conmutación por error de CA intentan alcanzar el 100 % de disponibilidad, los clústeres de HA se esfuerzan por alcanzar el 99,999 %, comúnmente conocido como cinco nueves. Este tiempo de inactividad no supera los 5,26 minutos al año. Los clústeres de CA tienen mayor disponibilidad pero requieren más hardware para funcionar, lo que aumenta su costo general.
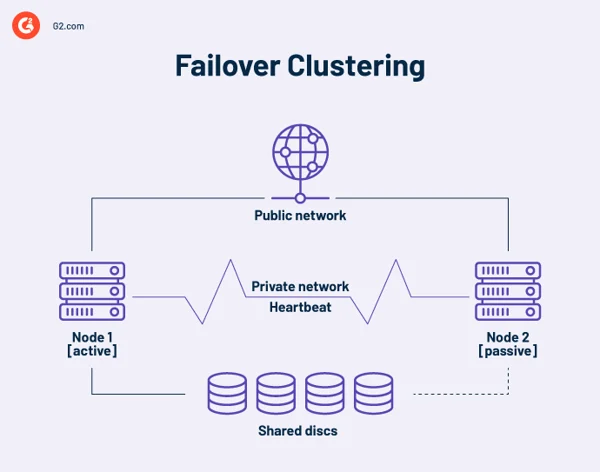
Clústeres de conmutación por error de alta disponibilidad
Un clúster de alta disponibilidad es un conjunto de computadoras independientes que comparten recursos y datos. Los nodos de un clúster de conmutación por error tienen acceso al almacenamiento compartido. También se incluye un enlace de monitoreo en los clústeres de alta disponibilidad para verificar el latido o el estado de los otros servidores. Un latido es una red privada compartida únicamente por los nodos del clúster. No es accesible desde el exterior.
En cualquier momento, al menos un nodo de un clúster está activo y al menos uno está inactivo o pasivo.
En una disposición básica de dos nodos, si el nodo 1 falla, el nodo 2 reconoce el fallo a través de la conexión de latido y se configura como el nodo activo. El software de agrupación en clústeres en cada nodo garantiza que los clientes se conecten a un nodo activo.
Las instalaciones más grandes pueden emplear servidores dedicados para administrar el clúster. Un servidor de administración de clústeres siempre envía señales de latido para identificar cualquier nodo que falle y, de ser así, indicarle a otro nodo que asuma el trabajo.
Algunas herramientas de software de administración de clústeres manejan HA para VM agrupando las máquinas y servidores en un clúster. Si un host falla, un host diferente reanuda las máquinas virtuales.
Como posible punto único de falla, el almacenamiento compartido representa un riesgo. Sin embargo, combinar una matriz redundante de discos independientes 6 y 10 (también conocidos como RAID 6 y RAID 10) puede ayudar a mantener el servicio incluso si fallan dos discos duros.
La energía eléctrica podría ser otro punto único de falla si todos los servidores están conectados a la misma red. Proporcionar a cada nodo su propio sistema de alimentación ininterrumpida (UPS) los mantiene protegidos.
Clústeres de conmutación por error de disponibilidad continua
A diferencia del paradigma HA, un clúster tolerante a fallas comprende numerosas computadoras que comparten una única copia del sistema operativo (SO) de una computadora. Los comandos de software dados a un sistema también se ejecutan en los otros sistemas.
CA insiste en que la organización emplea equipos informáticos formateados y un UPS de respaldo. CA necesita una réplica casi perfecta y constantemente accesible del sistema físico o virtual que ejecuta el servicio. Este modelo de redundancia se conoce como 2N.
Los sistemas CA pueden compensar una amplia gama de fallos. Un sistema tolerante a fallas puede identificar un mal funcionamiento de:
- Una unidad de disco duro
- Una unidad de procesamiento en una computadora.
- Un subsistema para entrada y salida (E/S)
- una fuente de energía
- Un componente de una red.
El punto de falla puede descubrirse rápidamente y un componente o método de respaldo puede tomar su lugar inmediatamente sin interrumpir el siguiente servicio.
El software de agrupación en clústeres puede conectar dos o más servidores para que se comporten como un único servidor virtual o construir varias configuraciones de clústeres de conmutación por error de CA alternativas. Por ejemplo, si uno de los servidores virtuales falla, los demás responden eliminando temporalmente el servidor virtual del quórum del clúster. Luego, el servidor virtual redistribuye la carga entre los otros servidores hasta que el servidor bloqueado esté listo para reiniciarse.
Un servidor de hardware doble con todos los componentes físicos replicados es una alternativa a los clústeres de conmutación por error de CA. Calculan por separado y simultáneamente en varias plataformas de hardware y se sincronizan mediante un nodo dedicado que monitorea los resultados de ambos servidores físicos. Si bien esta solución brinda protección, puede resultar más costosa.
Funciones de agrupación en clústeres de conmutación por error
Muchas organizaciones utilizan clústeres de conmutación por error para aplicaciones de misión crítica. Esto se debe a que las siguientes características hacen que la agrupación de conmutación por error sea una técnica importante.
- Escalabilidad : debido a que la agrupación en clústeres de conmutación por error se basa en un grupo de clústeres que colaboran para evitar fallas en el servidor, puede escalar fácilmente según sea necesario agregando nuevos clústeres.
- Estabilidad: los servidores agrupados se conectan mediante cables. Los clústeres restantes aún pueden ofrecer servicio incluso si uno o más fallan debido a factores externos.
- Monitoreo en tiempo real: los nodos del clúster se monitorean constantemente para garantizar que funcionen correctamente. Cuando un clúster se reinicia o se transfiere a otro nodo.
- Volumen compartido de clúster (CSV): esta característica proporciona un espacio de nombres consistente y distribuido para que los nodos lo utilicen mientras trabajan con almacenamiento compartido. Es fundamental mantener las aplicaciones del servidor ejecutándose sin interrupciones de principio a fin.
Tipos de clústeres de conmutación por error
En la última década se han producido avances significativos en la agrupación en clústeres de conmutación por error, y muchas organizaciones ahora ofrecen su propia versión de soluciones de agrupación en clústeres. Algunos de los servicios de clúster más comunes se detallan aquí.

Clústeres de conmutación por error de VMware
VMware proporciona numerosas tecnologías de virtualización para clústeres de VM. La arquitectura CA de vSphere vMotion duplica con precisión una máquina virtual VMware y su red entre redes de centros de datos físicos.
VMware vSphere HA, un segundo producto, proporciona HA para máquinas virtuales agrupándolas a ellas y a sus hosts en un clúster para una conmutación por error automatizada. Además, el programa no depende de componentes externos como DNS, lo que reduce los posibles puntos de falla.
Clúster de conmutación por error del servidor de Windows
El método del clúster de conmutación por error del servidor de Windows (WSFC) fomenta la creación de servidores de conmutación por error de Hyper-V. Entre 2016 y 2019, esta estrategia se hizo popular entre los usuarios de Microsoft Windows. WSFC permite la supervisión del clúster y ofrece el mecanismo de conmutación por error necesario de forma automática. En caso de pérdida del servidor, WFSC mueve los clústeres a un nodo separado o intenta reiniciarlos. Además, su tecnología CSV proporciona un espacio de nombres distribuido que permite que varios nodos compartan memoria.
Servidor SQL
Este producto de Microsoft, presentado con SQL Server 2017, tiene soluciones HA sólidas que utilizan tecnología WSFC. Los componentes del servidor SQL se consideran recursos del clúster WSFC en este contexto. Están aún más integrados con otros recursos dependientes de WSFC. Como resultado, WSFC tiene autoridad para identificar y comunicar órdenes para reiniciar una instancia de servidor SQL o mover instancias como esas a un nuevo nodo.
Red Hat Linux
Además de Microsoft, otros proveedores de sistemas operativos vienen con sus propias soluciones de clúster de conmutación por error. Por ejemplo, los fanáticos de Red Hat Enterprise Linux (RHEL) pueden usar la extensión HA y Red Hat Global File System (GFS/GFS2) para establecer clústeres de conmutación por error de HA. Se admiten clústeres extendidos de un solo clúster que abarcan muchas ubicaciones y clústeres de múltiples sitios tolerantes a desastres . La replicación del almacenamiento de datos de la red de área de almacenamiento (SAN) se usa comúnmente en clústeres de múltiples sitios.
Aplicaciones de la agrupación en clústeres de conmutación por error
Este robusto mecanismo facilita las siguientes aplicaciones en tiempo real.
Disponibilidad de aplicaciones de misión crítica.
Las computadoras de procesamiento de transacciones en línea (OLTP) deben tener sistemas resistentes a fallas. OLTP, que requiere disponibilidad total, se utiliza para sistemas de reserva de aerolíneas, comercio electrónico de acciones y banca en cajeros automáticos.
Muchas industrias, como la de fabricación, envío y venta minorista, emplean clústeres de CA o computadoras resistentes a fallas para aplicaciones de misión importante. Como ejemplos se incluyen el comercio electrónico, la gestión de pedidos y los sistemas de control de tiempo del personal.
Los clústeres de alta disponibilidad suelen ser aceptables para agrupar aplicaciones y servicios que requieren sólo cinco nueves de tiempo de actividad.
Alivio de desastres
La recuperación ante desastres también se beneficia de la agrupación en clústeres de conmutación por error. Se recomienda encarecidamente que los servidores de conmutación por error se alojen en sitios remotos porque una calamidad como un incendio o una inundación destruye todo el hardware y software físico.
Storage Replica, una tecnología que duplica volúmenes entre servidores para recuperación ante desastres , se incluye en Windows Server 2016 y 2019. La conmutación por error extendida es una característica tecnológica que permite que los clústeres de conmutación por error abarquen dos ubicaciones.
Las organizaciones pueden replicar datos en varios centros ampliando los clústeres de conmutación por error. Si ocurre una tragedia en un lugar, todos los datos se conservan en servidores de conmutación por error en los demás.
Replicación de una base de datos
Según Microsoft, el WSFC se lanzó por primera vez en Windows Server 2016 para salvaguardar los servicios "críticos", como su base de datos del servidor SQL y el servidor de comunicaciones Microsoft Exchange.
Para la replicación de bases de datos , otros proveedores ofrecen tecnología de clúster de conmutación por error. Por ejemplo, MySQL Cluster tiene un método de latido que permite una rápida detección de fallas en otros nodos del clúster, a menudo en menos de un segundo, sin interrupciones del servicio para los clientes.
Las bases de datos se pueden replicar en sitios lejanos utilizando la capacidad de replicación geográfica.
Beneficios de los clústeres de conmutación por error
La idea de los clústeres de conmutación por error es garantizar que los usuarios experimenten interrupciones mínimas en el servicio. Sin embargo, a continuación se analizan otros beneficios adicionales de la agrupación en clústeres de conmutación por error.
- Mayor disponibilidad de recursos: si un servidor inteligente falla, los demás en el clúster asumen la carga. Esto ahorra tiempo e información cruciales.
- Asignación estratégica de recursos: puedes distribuir proyectos entre nodos de la forma que elijas. Esto minimiza los gastos generales, ya que no todas las computadoras son necesarias para ejecutar todos los proyectos simultáneamente, lo que le brinda una manera de utilizar sus recursos con mayor libertad.
- Mayor poder de procesamiento: más máquinas, más potencia.
- Mayor escalabilidad: a medida que su base de usuarios y la complejidad de sus informes se expanden, también pueden hacerlo sus recursos.
- Gestión simplificada: la agrupación en clústeres facilita el manejo de sistemas importantes o que cambian rápidamente.
Limitaciones de la agrupación de conmutación por error
Por muy importante que sea la agrupación en clústeres de conmutación por error, se enfrenta a las siguientes limitaciones.
- Configuraciones complejas: la configuración de clústeres de conmutación por error para Windows requiere que manejes muchas redes y tarjetas de red a la vez. Como resultado, implementar este método es difícil, especialmente para principiantes.
- Integraciones de herramientas: los clústeres de conmutación por error de Windows y Hyper-V deben integrarse más estrechamente. Tienes que ajustar cada uno de ellos. para completar la agrupación de conmutación por error con éxito.
- Interfaz web: no hay una interfaz web para ajustar los parámetros del clúster. Para acceder a la función del administrador de clústeres, debe iniciar sesión manualmente en un escritorio remoto.
Soluciones de clustering de conmutación por error: proveedores de DNS administrados
Al trabajar en conjunto con sistemas de agrupación de conmutación por error, los proveedores de DNS administrados redirigen el tráfico a servidores o centros de datos alternativos durante eventos de conmutación por error, lo que garantiza un acceso ininterrumpido a sus servicios para lograr una alta disponibilidad y minimizar el tiempo de inactividad.
Los cinco principales proveedores de DNS administrados:
- DNS de nube
- DNS azul
- Infoblox NIOS
- DESARROLLO DE WPMU
- Administrador de DNS
*Arriba se muestran los cinco principales proveedores de software de DNS administrado del informe Grid de otoño de 2023 de G2.

Modernizando la confiabilidad
La agrupación de conmutación por error ha surgido como una opción confiable y esencial para una alta disponibilidad y tolerancia a fallas dentro de las infraestructuras de TI actuales. Proporciona operaciones continuas a pesar de fallas de hardware o mantenimiento programado al distribuir automáticamente cargas de trabajo y recursos entre numerosos nodos en red. Esta tecnología le brinda otra forma de manejar el aspecto más importante de su negocio: hacer que la experiencia de cada cliente sea segura y feliz.
¡Fortalecer la resiliencia de su sistema tampoco hace daño!
Comience con una guía de seguridad DNS para una estrategia de sistema sólida.