
Aproveche al máximo Apache Solr: una exploración técnica de la indexación de búsqueda
Publicado: 2023-02-21Una función de búsqueda mejora la experiencia del usuario de un sitio web al permitirle encontrar lo que está buscando de manera fácil y rápida. Más aún para sitios web grandes, sitios de comercio electrónico y sitios con contenido dinámico (sitios de noticias, blogs).
Apache Solr es una de las plataformas de búsqueda más populares utilizadas por sitios web de todos los tamaños. Es un motor de búsqueda de código abierto basado en Java que le permite buscar en grandes cantidades de datos, como artículos, productos, reseñas de clientes y más. Eche un vistazo más profundo a Apache Solr en este artículo.
Consulte este artículo para aprender a configurar Apache Solr en Drupal

¿Por qué Apache Solr es tan popular?
Apache Solr es rápido y flexible y permite la búsqueda de texto completo, resaltado de coincidencias (resalta el término de búsqueda coincidente), búsqueda por facetas (una búsqueda más refinada), indexación en tiempo real (permite que el contenido nuevo se indexe de inmediato), agrupación dinámica ( organiza los resultados de búsqueda en grupos), integración de bases de datos, funciones NoSQL (base de datos no relacional) y manejo de documentos enriquecidos (para indexar una amplia variedad de formatos de documentos como PDF, MS Office, Open office).
Algunos datos interesantes sobre Apache Solr:
- Inicialmente fue desarrollado por CNET Networks, Inc. como un motor de búsqueda para sus sitios web y artículos. Más tarde, fue de código abierto y se convirtió en un proyecto Apache de alto nivel.
- Admite múltiples lenguajes de programación como PHP, Java, Python y Ruby. También proporciona API para estos idiomas.
- Tiene soporte incorporado para la búsqueda geoespacial, lo que permite buscar contenido en función de su ubicación. Especialmente útil para sitios como sitios web de bienes raíces, sitios web de viajes, etc.
- Admite funciones de búsqueda avanzada como revisión ortográfica, autocompletar y búsqueda personalizada a través de API y complementos.
- Utiliza Lucene para indexar y buscar.
que es lucene
Apache Lucene es una biblioteca de búsqueda Java de código abierto que le permite agregar fácilmente búsquedas o recuperación de información a la aplicación. Es versátil, poderoso, preciso y funciona con un algoritmo de búsqueda eficiente.
Aunque es conocido por sus capacidades de búsqueda de texto completo, Lucene también se puede utilizar para la clasificación de documentos, el análisis de datos y la recuperación de información. También es compatible con muchos idiomas además del inglés, como alemán, francés, español, chino, japonés y más.
¿Qué es la indexación?
Todos los motores de búsqueda comienzan con la indexación. La indexación es el procesamiento de datos originales en una búsqueda de referencias cruzadas altamente eficiente para facilitar la búsqueda rápida.
Los motores de búsqueda no indexan los datos directamente. Los textos se dividen primero en fichas (elementos atómicos). La búsqueda es el proceso de consultar el índice de búsqueda y recuperar el documento que coincide con la consulta.
Ventajas de indexar
- Recuperación de información rápida y precisa (recopila, analiza y almacena)
- Sin indexación, el motor de búsqueda requiere más tiempo para escanear cada documento
Flujo de indexación
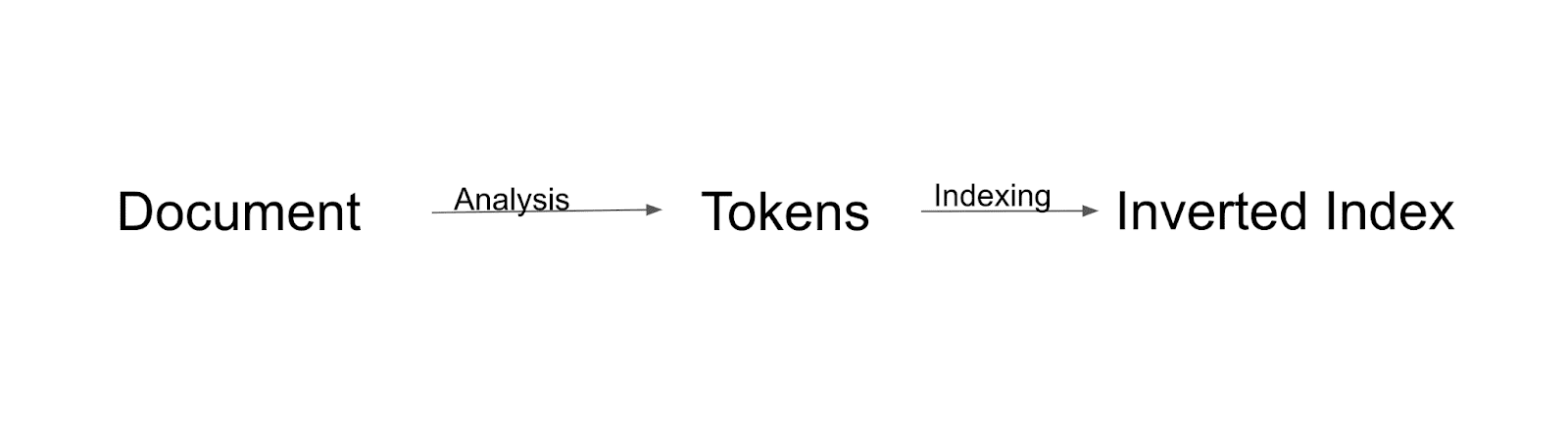
Primero, el documento será analizado y dividido en tokens. Todos esos tokens se indexarán al índice invertido. El índice invertido es una forma en que Solr construye el índice.
Cómo funciona la indexación invertida
Consideremos que tenemos 3 documentos:
- Me encanta el chocolate (D 1)
- Pedí pastel de chocolate (D 2)
- Preparé bizcocho grande de vainilla (D 3)
La forma en que se tokeniza es como se muestra en la segunda columna de la tabla a continuación.

“Chocolate” está disponible en D1 y D2
"Pastel" está disponible en D2 y D3
"Grande" está disponible en D3
"Pedido" está disponible en D2
"Preparado" está disponible en D3
"Vainilla" está disponible en D3
Notarás que palabras como "yo", "amor" no están tokenizadas. Estas se denominan palabras vacías que Solr no indexará ni buscará.
Entonces, cuando alguien busca el término "Pastel de chocolate", el motor busca en el índice. En lugar de buscar el documento, primero busca en el índice para ver en qué documentos se encuentran las palabras "Chocolate" y "Cake". Esto hace que sea más fácil y rápido obtener solo el documento en particular. Esto se llama indexación invertida.
Esquema de almacenamiento
Apache Solr utiliza un esquema de almacenamiento basado en documentos y almacena cada dato como un documento separado dentro de una colección. Esto permite un almacenamiento y una recuperación de datos eficientes y flexibles.
En Drupal, cada nodo se considera como un documento. Entonces, cuando indexa su nodo a Apache Solr, se considera como un documento. Cada documento puede contener varios campos. Lucene no tiene un esquema global común. Lo que significa que puede indexar cualquier tipo de campo en cada documento en Apache Solr.

Cómo instalar Apache Solr
- Primero, asegúrese de tener Java instalado en su sistema.
- A continuación, instalemos Solr desde aquí: https://solr.apache.org/downloads.html
- Descarga y extrae Solr.
- Ejecute este comando en la carpeta Solr.
◦ bin/solr -e productos tecnológicos
Esto creará un núcleo ficticio para la demostración y también iniciará el servidor Solr.
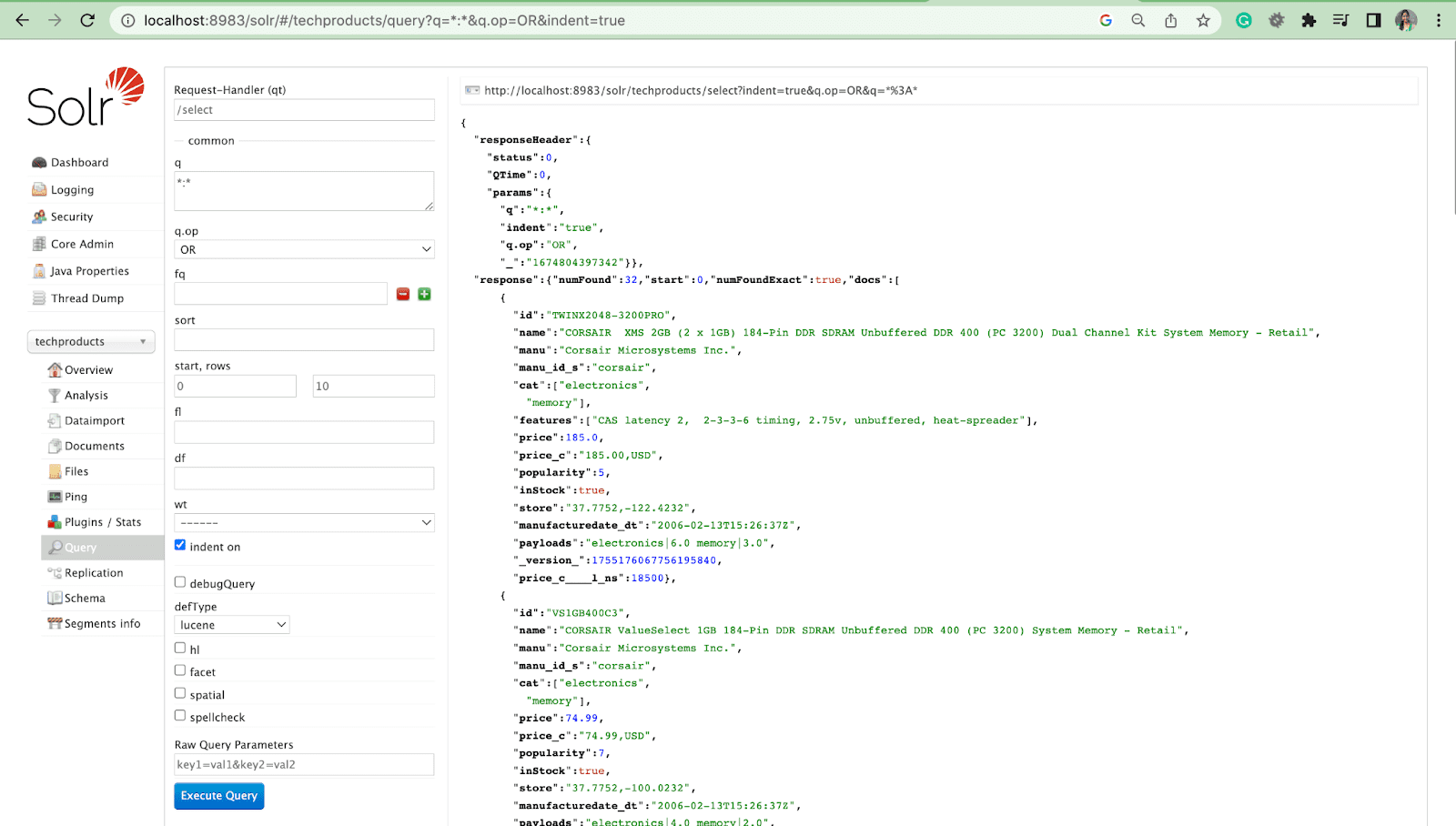
- Una vez que el servidor se haya iniciado, vaya a su navegador y escriba "http://localhost:8983/".
- Asegúrese de que Solr se haya instalado correctamente con el núcleo ficticio.
Estructura de directorios
Una vez que haya instalado Solr, verá muchas carpetas como:
Docs - contiene documentación sobre Solr
Dist : archivo .jar principal de Solr
Contrib : contiene complementos adicionales y funciones especializadas de Solr
Bin - guiones de Solr
Ejemplo : contiene capacidades de demostración de solr
Servidor - corazón de Solr. Contiene aplicación web de Solr, registros, núcleo de Solr

Archivos de configuración
Para crear un núcleo, necesitamos dos archivos obligatorios.
- Esquema.xml
- Solrconfig.xml
Esquema.xml
- Contendrá los tipos de campos que planea admitir y cómo se deben analizar esos tipos.
Solrconfig.xml
- Contiene varias configuraciones que controlan el comportamiento de un núcleo de Solr como el controlador de solicitudes, el despachador de solicitudes, los componentes de consulta, los controladores de actualización, etc.
Consultando en Solr
Ahora veamos cómo consultar los resultados de Solr en la interfaz de usuario de administración de Solr.
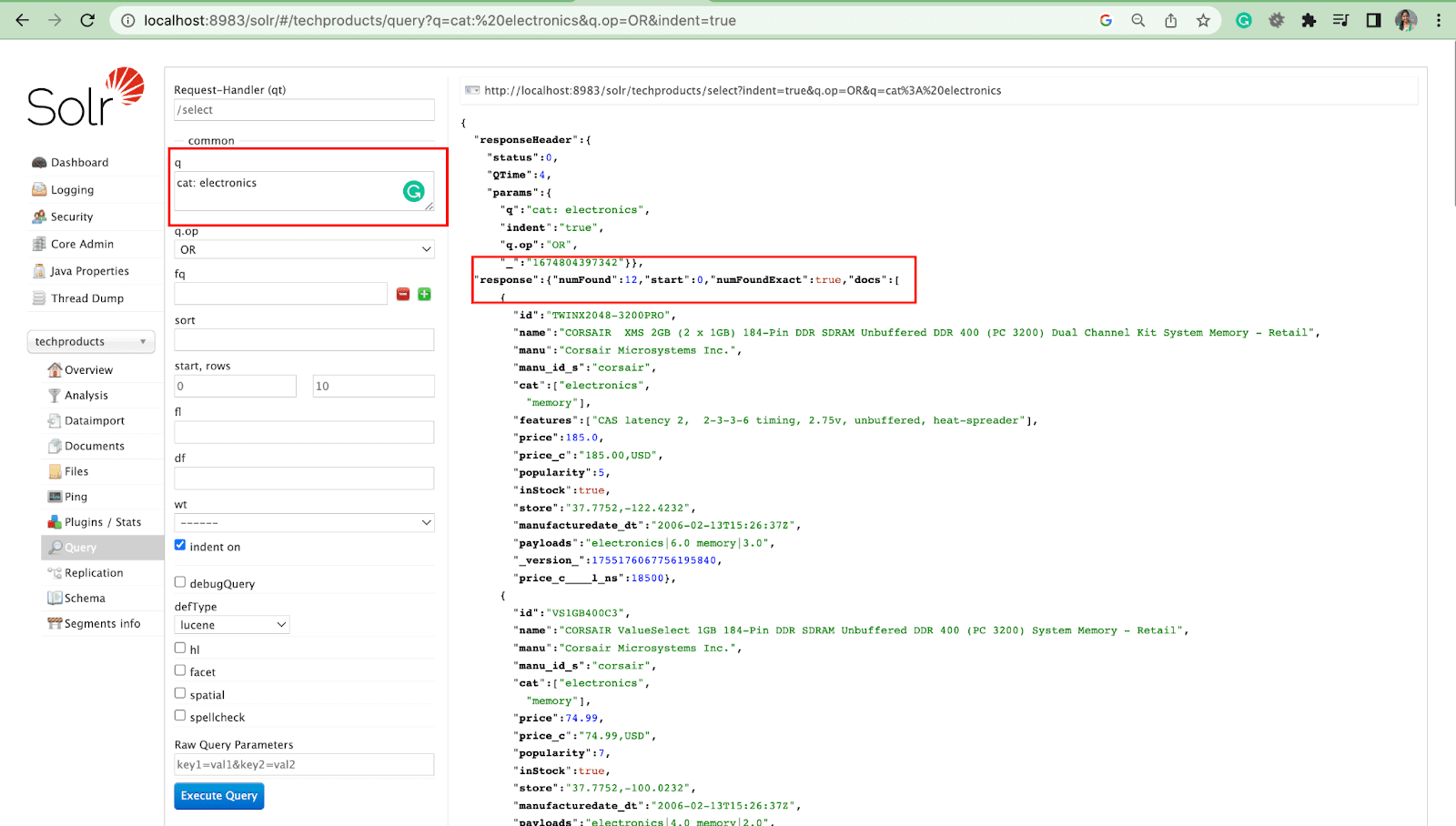
Parámetro de consulta
- Los parámetros locales son argumentos en una solicitud de Solr que son específicos de un parámetro de consulta.
Por ejemplo: gato: electrónica
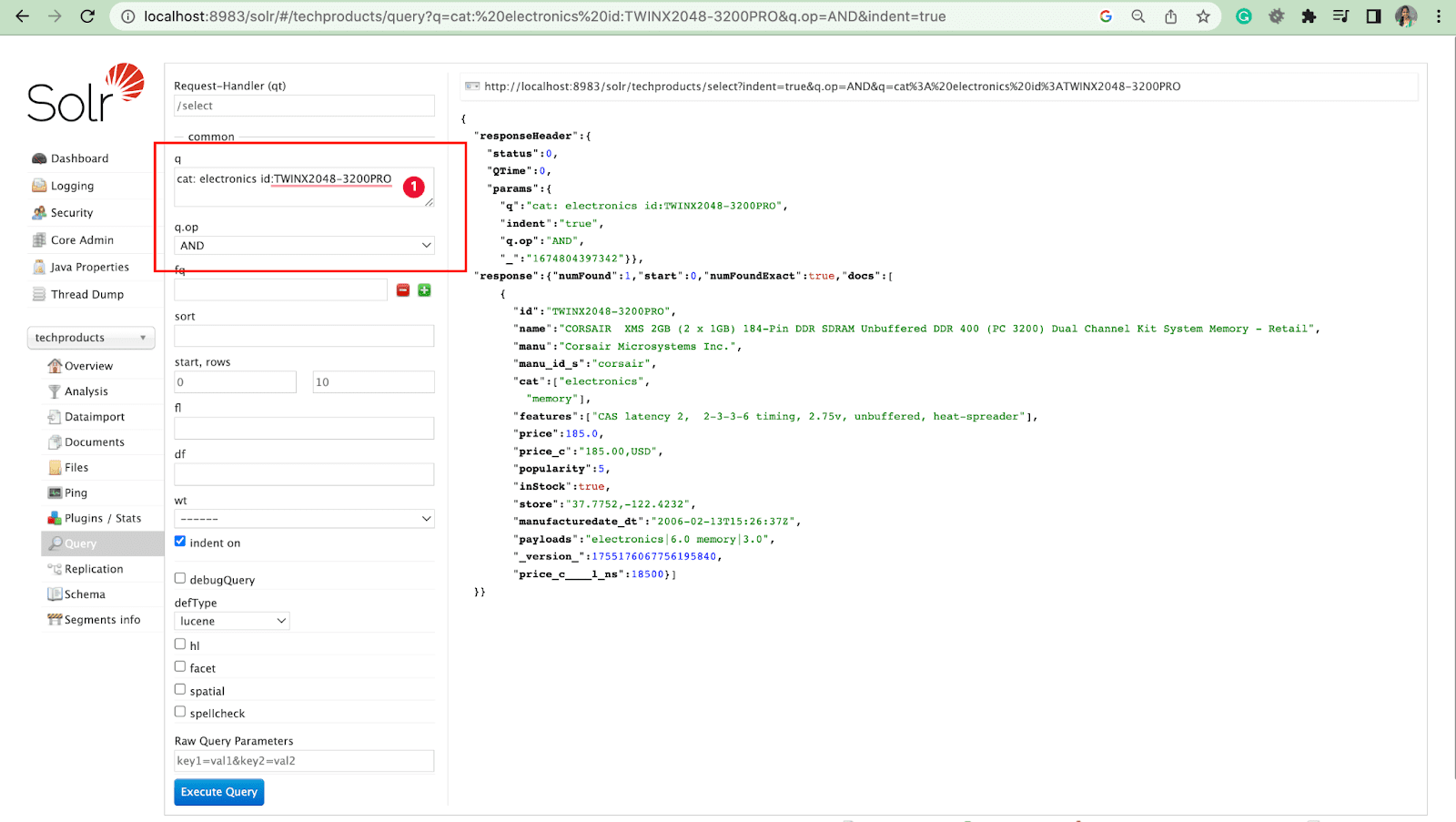
Parámetro de consulta con operaciones
- Podemos consultar varios campos con la operación.
Por ejemplo: cat: electronics id:TWINX2048-3200PRO con q.op Y
[O]
gato: electrónica Y id:TWINX2048-3200PRO
[O]
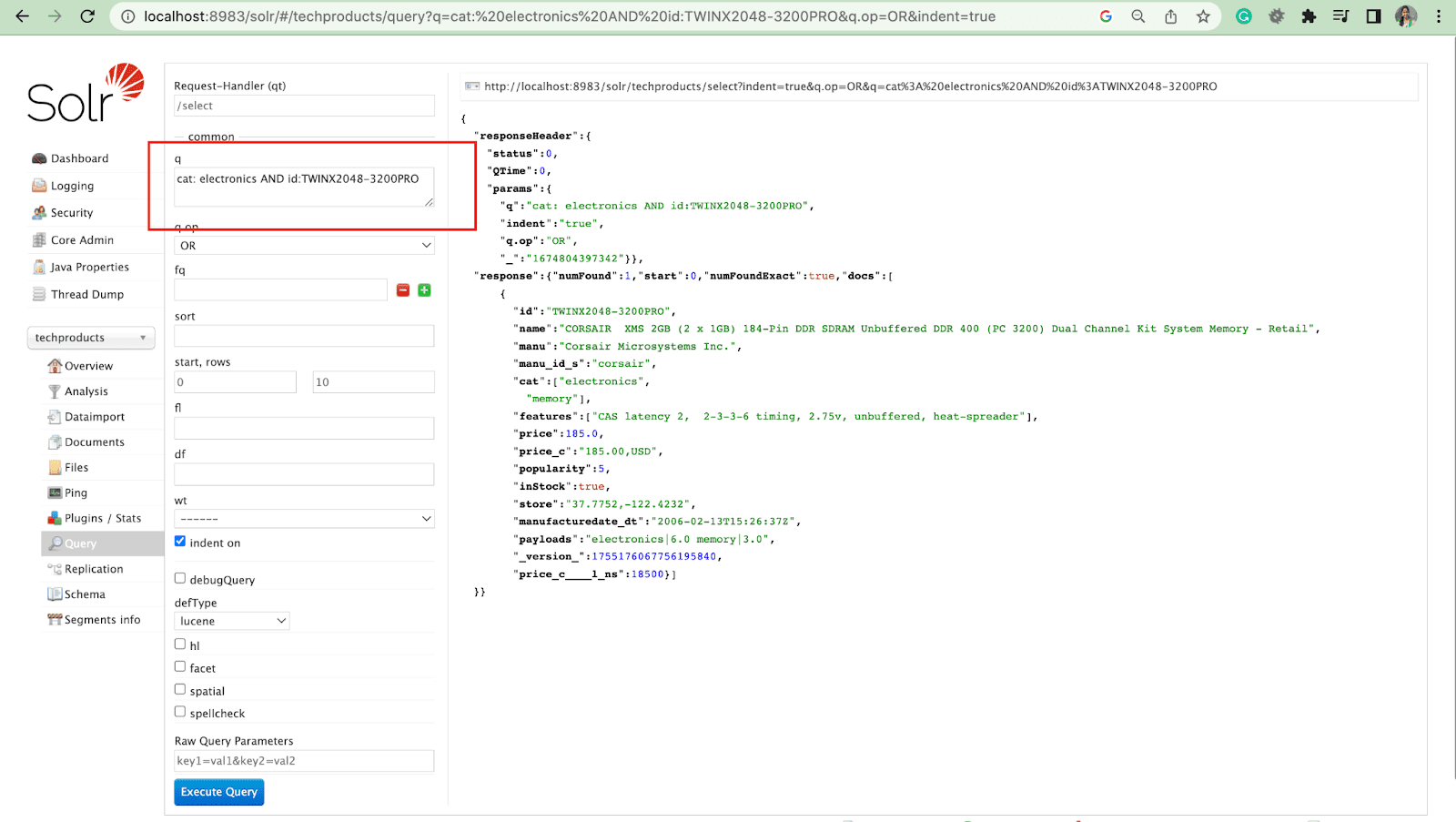
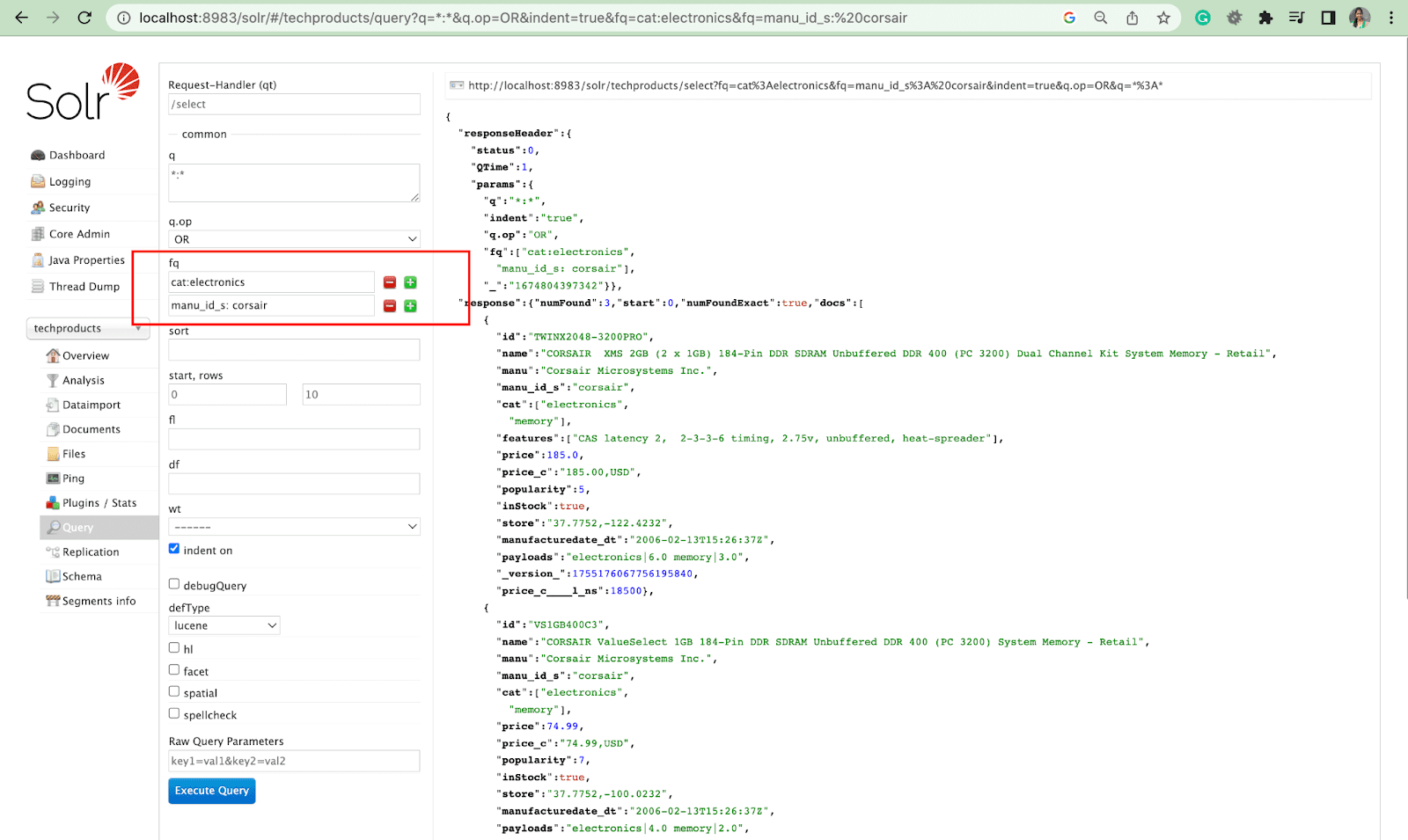
Consulta de filtro
Una consulta de filtro ayuda a reducir los resultados de una búsqueda. El parámetro fq puede especificar una consulta para restringir qué documentos se devuelven en el superconjunto, sin afectar la puntuación.
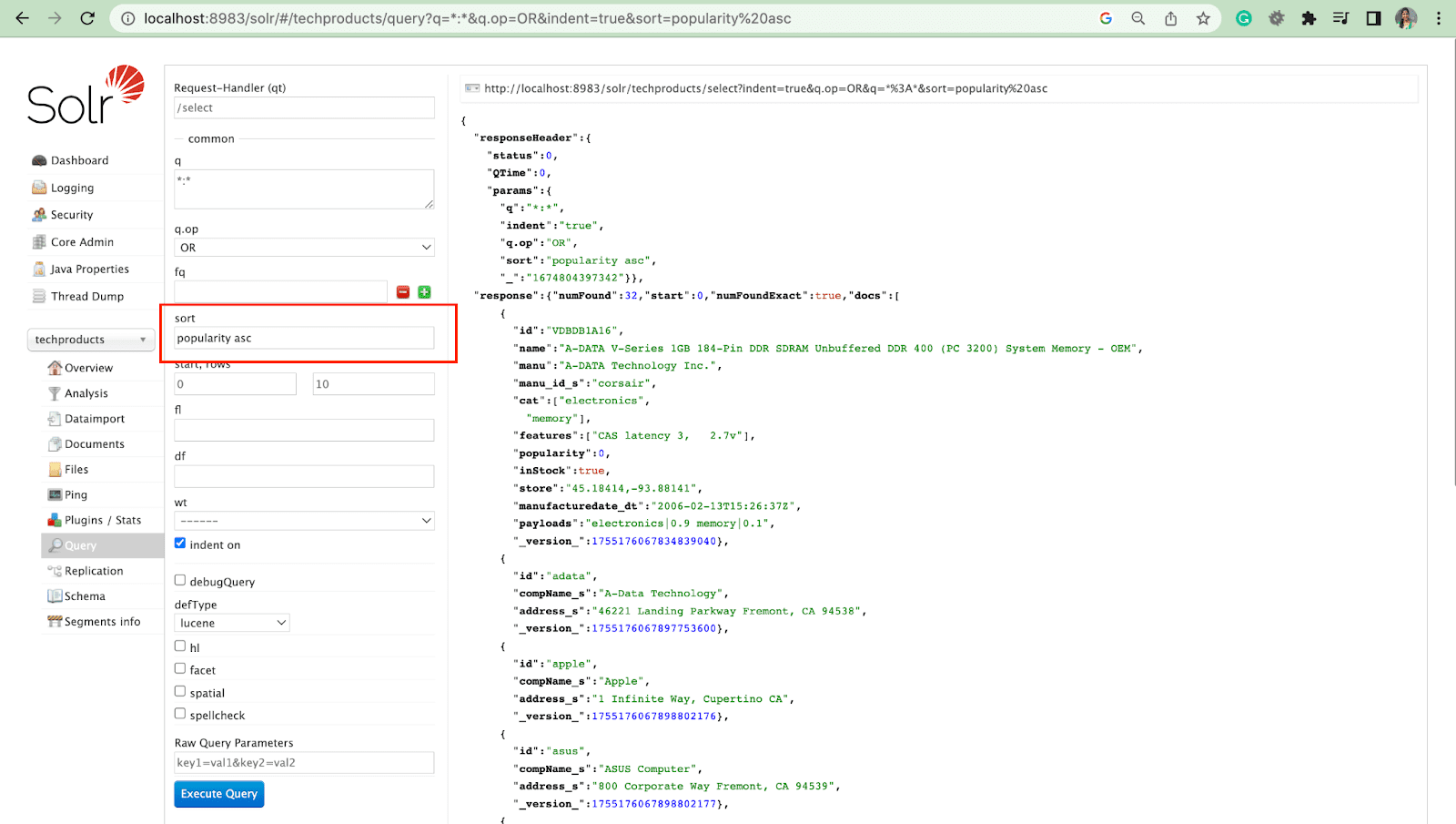
Ordenar parámetro
El parámetro sort organiza los resultados de la búsqueda en orden ascendente (asc) o descendente (desc). Según el contenido, el parámetro se puede utilizar de forma numérica o alfabética.
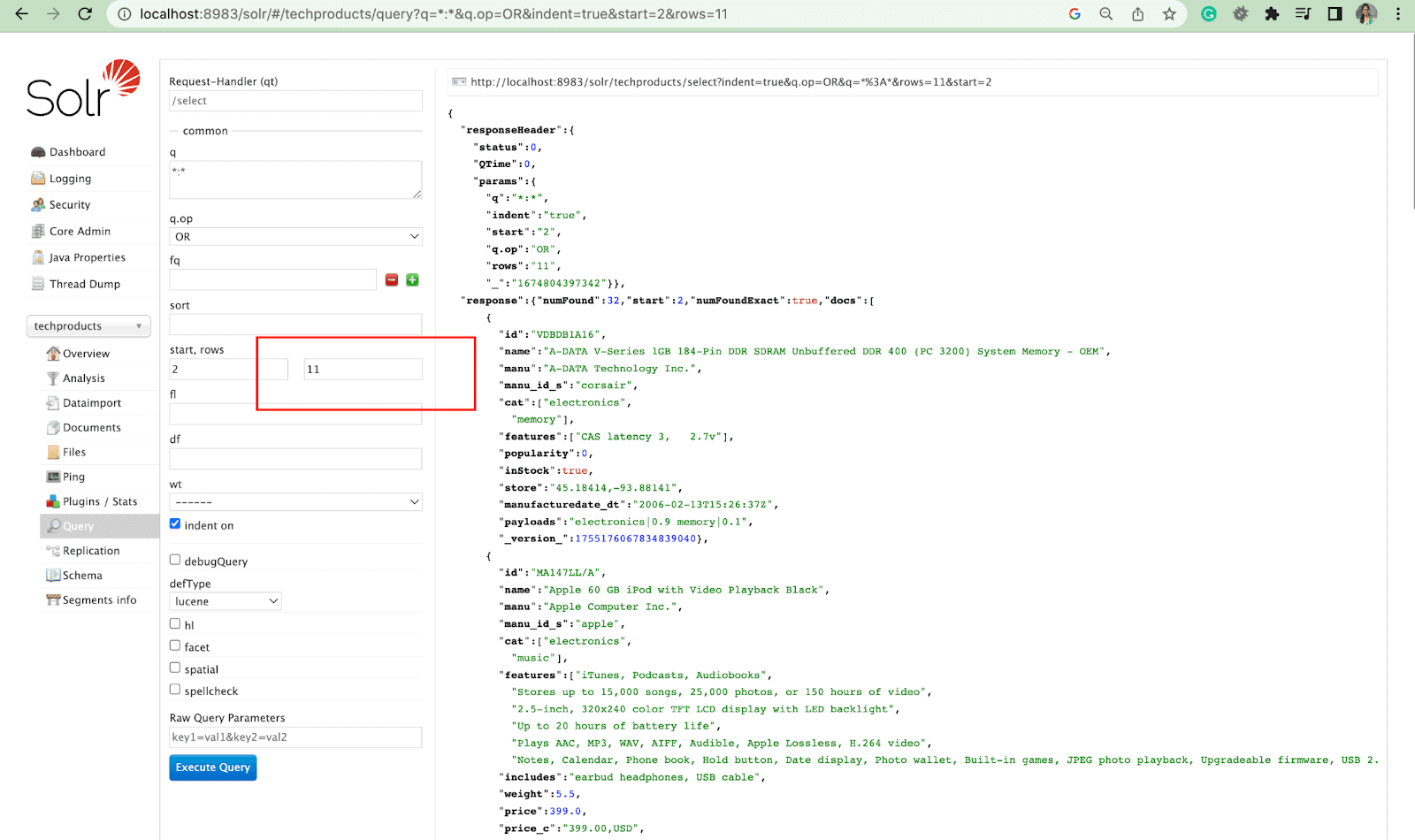
Parámetro de filas
El parámetro de filas le permite paginar los resultados de una consulta.
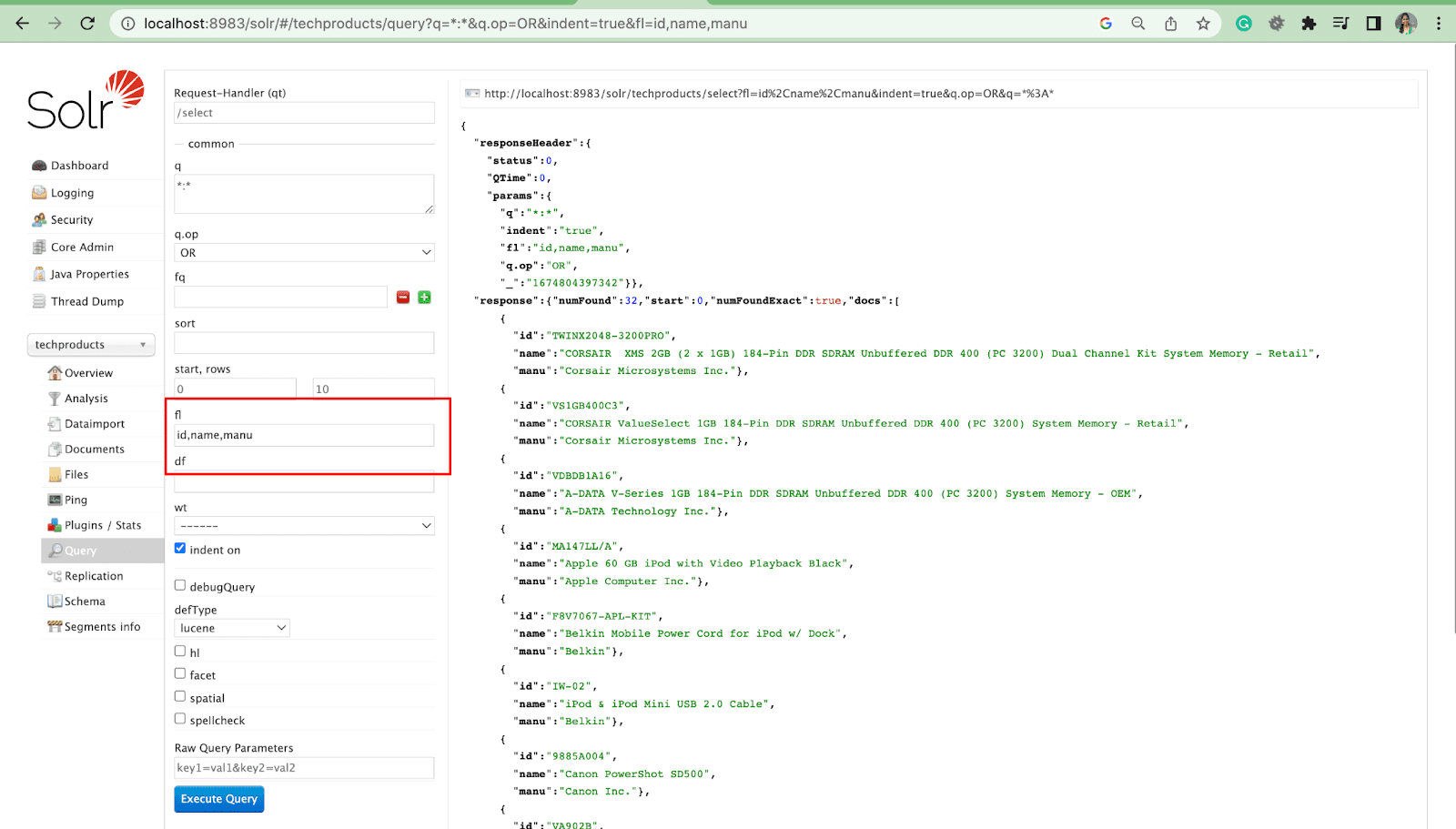
Parámetro de lista de campos
El parámetro fl limita la información incluida en una respuesta de consulta a una lista específica de campos.
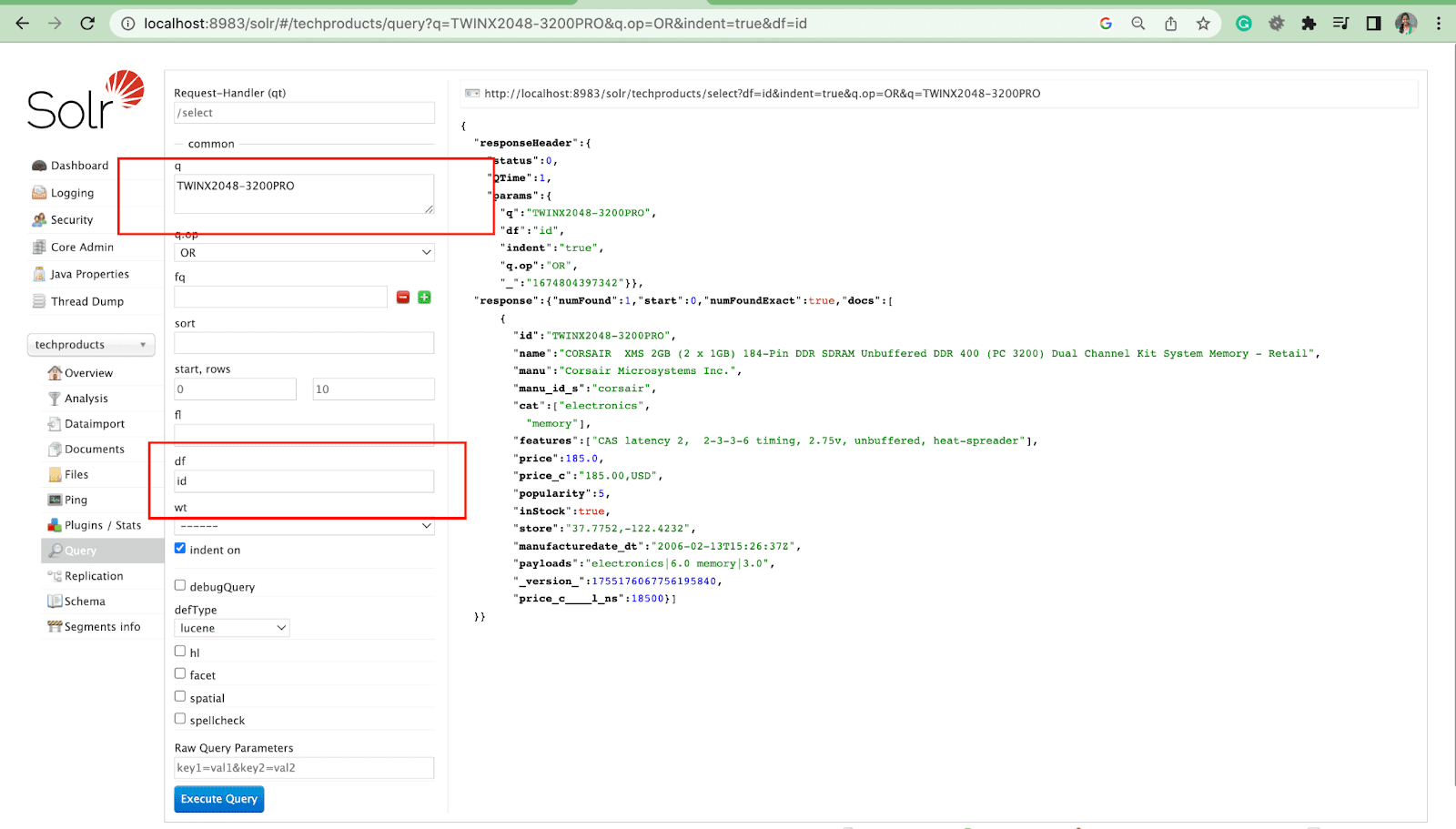
Campo predeterminado Parámetro
El parámetro de campo predeterminado es el campo predeterminado para el parámetro de consulta.
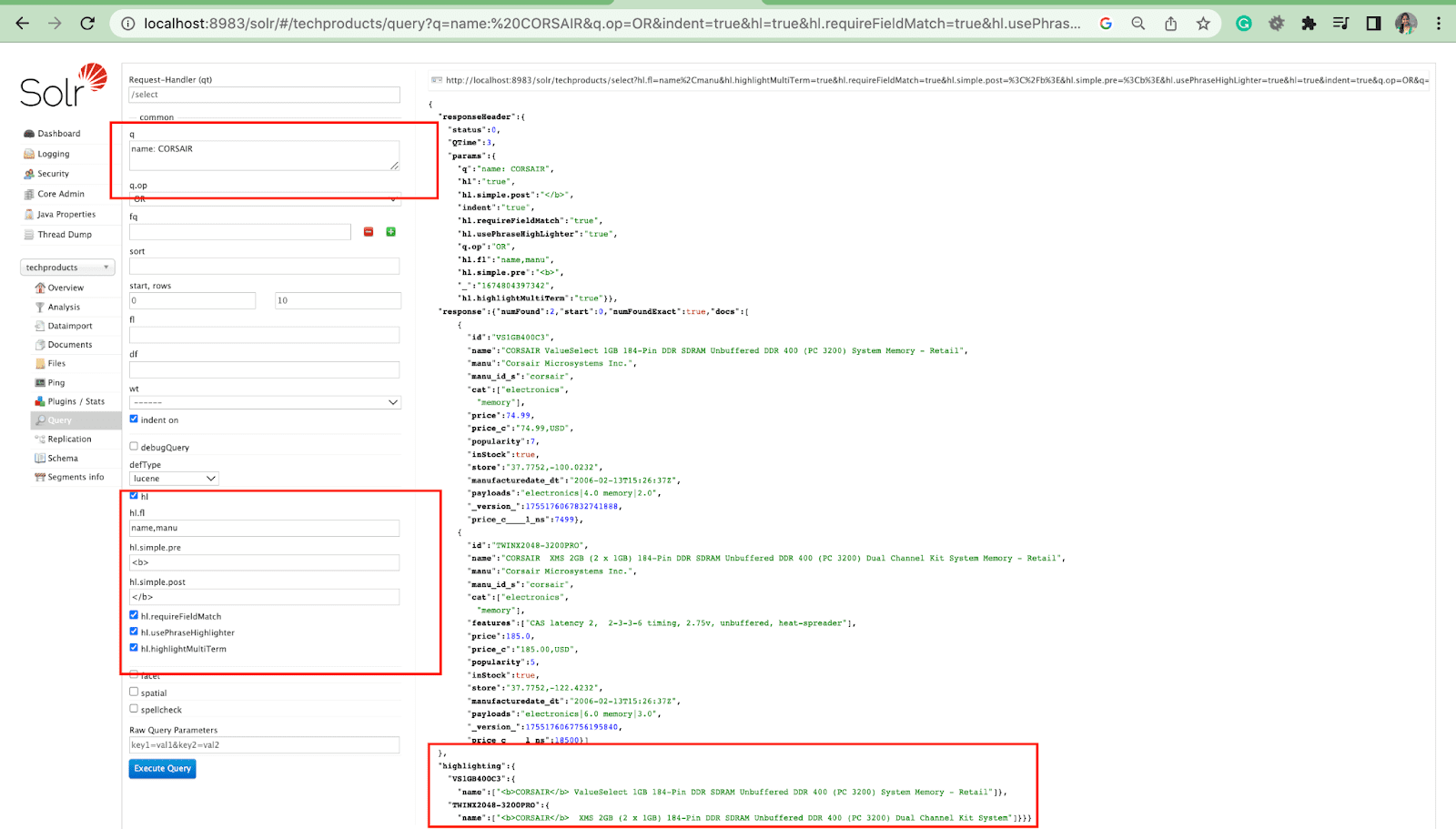
Parámetro destacado
La función de resaltado en Solr permite la inclusión de fragmentos de documentos que coinciden con una consulta.
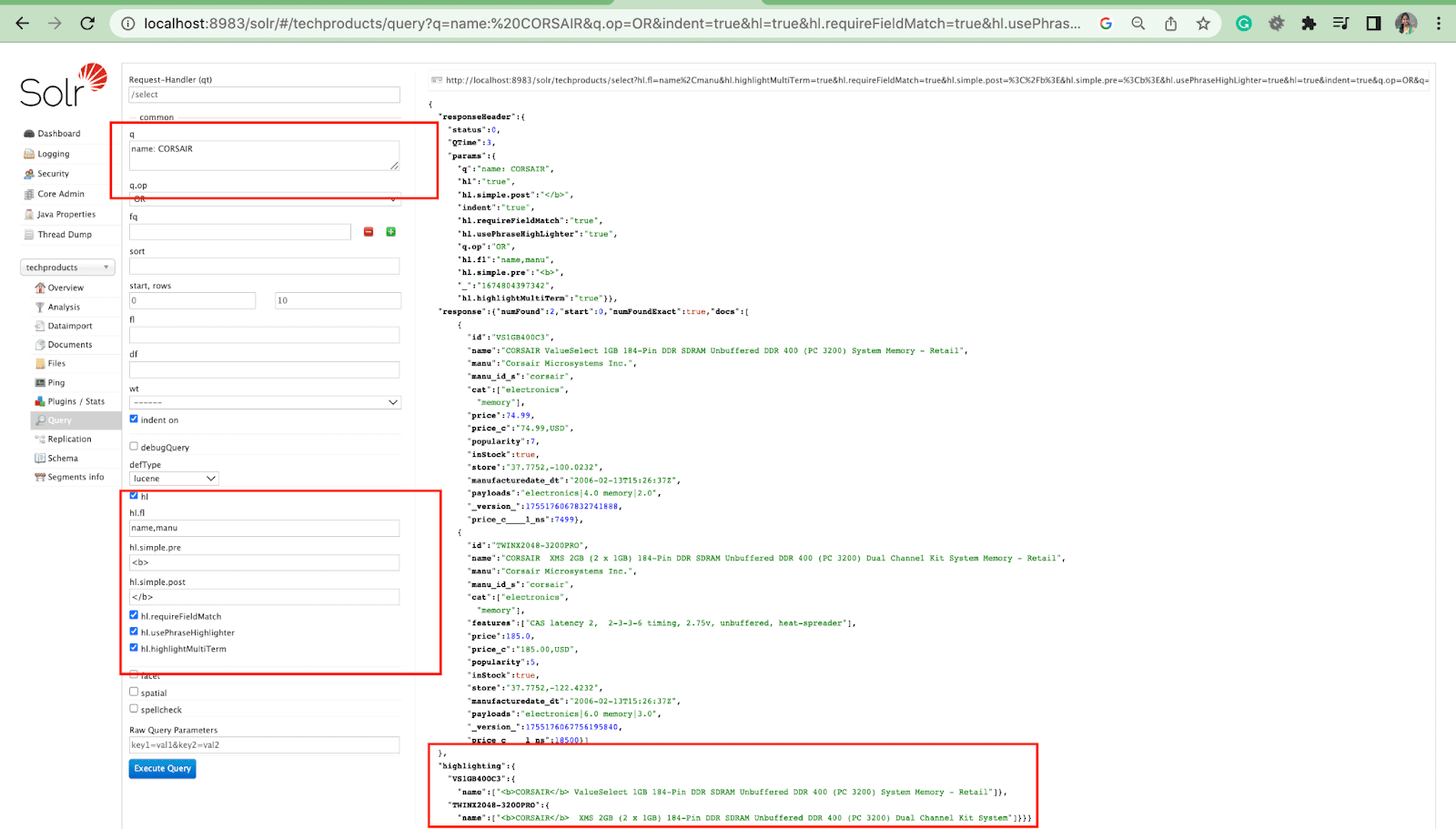
Algunos de los parámetros de resaltado más comunes son:
- Hl.fl : resalta una lista de campos.
- Hl.simple.pre : especifica qué "etiqueta" debe usarse antes de una palabra resaltada.
- Hl.simple.post: especifica qué "etiqueta" debe usarse después de un término resaltado.
- hl.highlightMultiTerm: si se establece en true , Solr resaltará las consultas comodín. Si es false , no se resaltarán en absoluto.
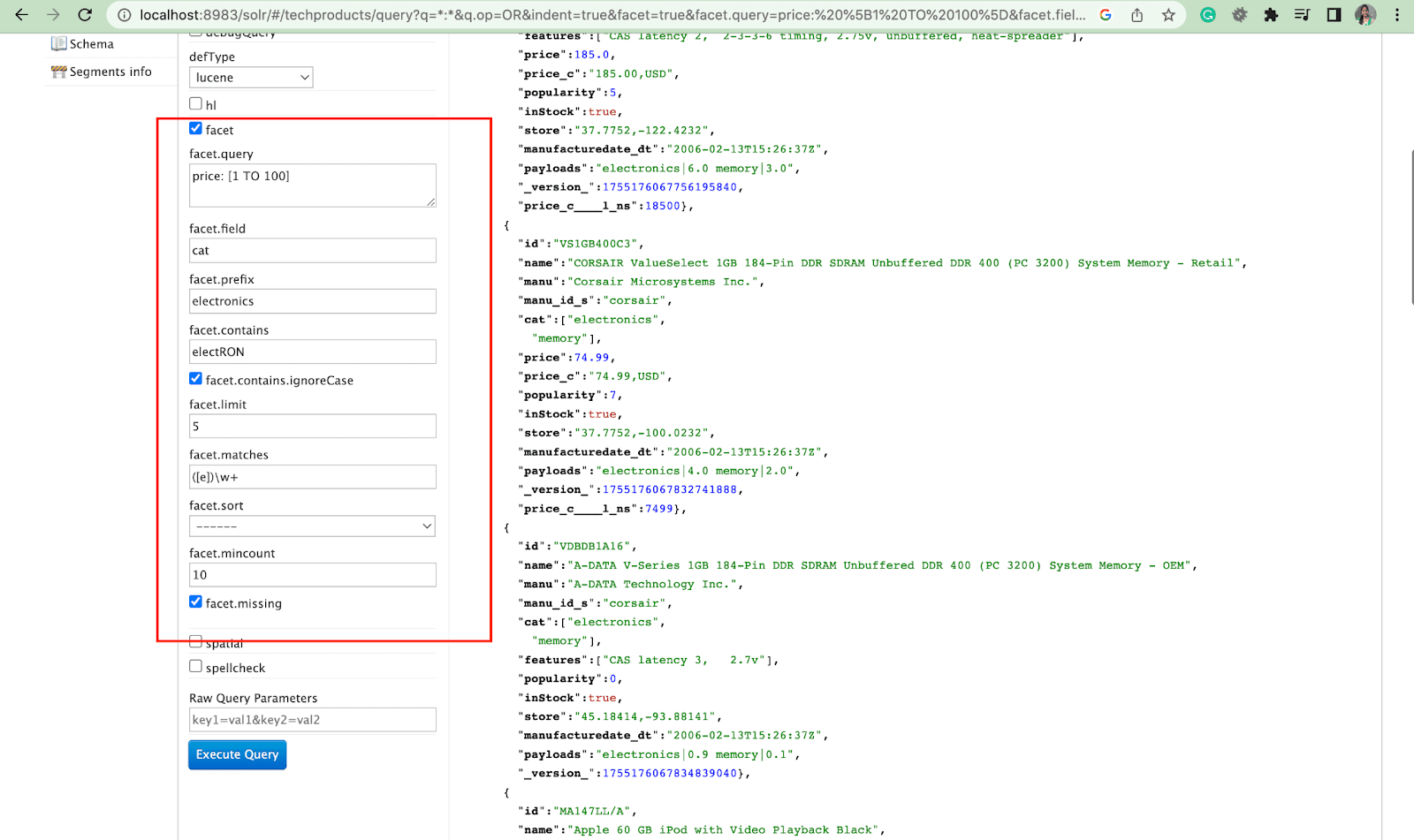
Faceta:
Las facetas permiten a los usuarios explorar y refinar grandes conjuntos de resultados de búsqueda. Se muestran en una interfaz de usuario como casillas de verificación, menús desplegables u otros controles. Los dos parámetros generales para controlar las facetas son:
- Parámetro de faceta
Usando el parámetro faceta, los usuarios pueden generar facetas basadas en los valores de uno o más campos en su índice de búsqueda. En los resultados de búsqueda, el parámetro de faceta se puede configurar para controlar cómo se generan y muestran las facetas.
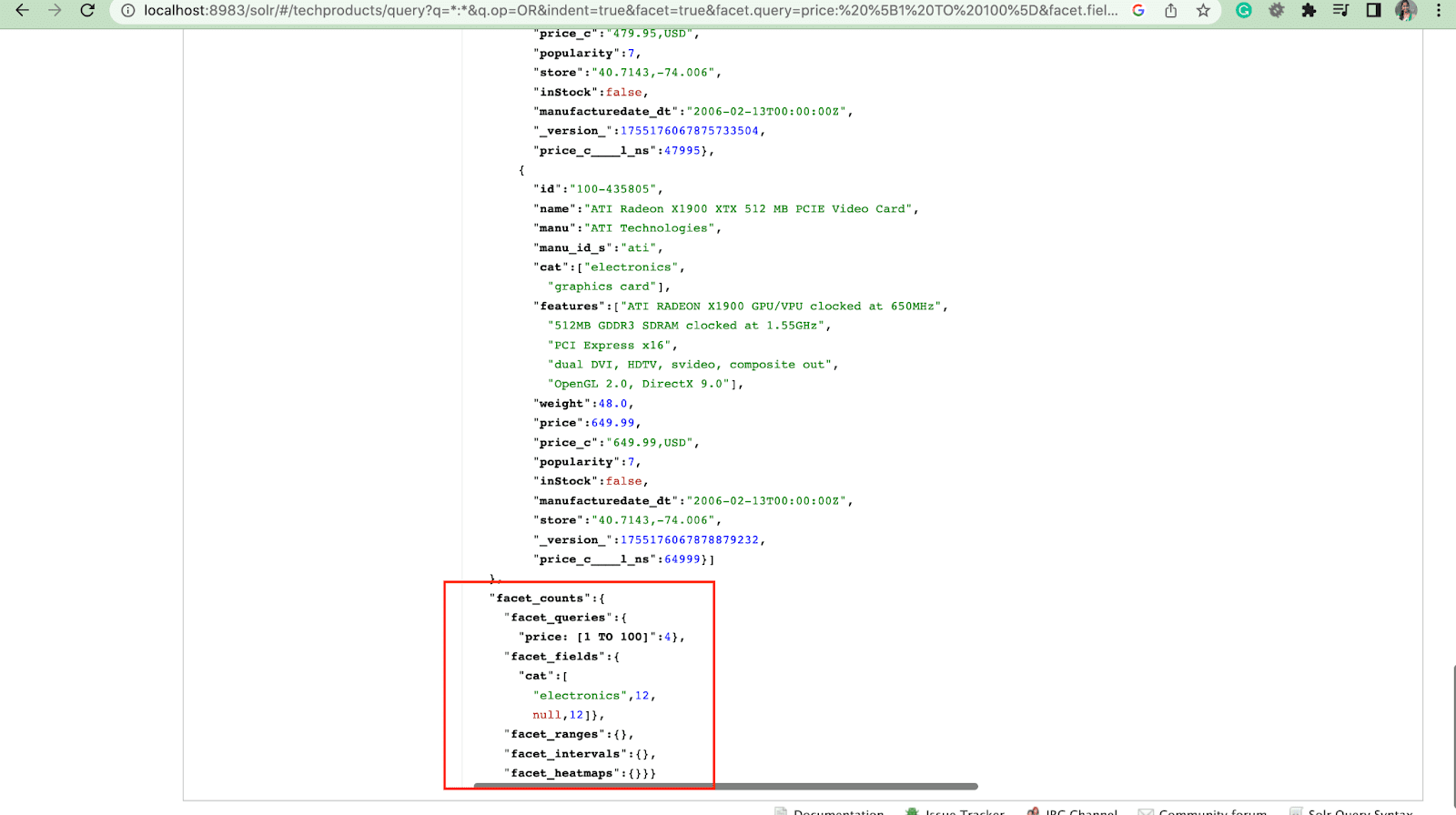
2. Parámetro faceta.consulta
Cuando un usuario incluye un parámetro facet.query en su consulta de Solr, Solr generará una lista de recuentos de facetas que corresponden a la cantidad de documentos en el índice que coinciden con cada consulta. Facet.query es útil cuando desea generar facetas basadas en criterios de búsqueda complejos que no se pueden representar fácilmente mediante un valor de campo simple.
Hay varios otros parámetros de faceta como facet.field (para especificar los campos que deben usarse para generar facetas) , facet.limit (número máximo de facetas para mostrar para cada campo) , facet.mincount (número mínimo de documentos necesarios para la faceta que se incluirá en la respuesta) , facet.sort (especifica el orden en el que se deben mostrar los valores de faceta) .
Pensamientos finales
Apache Solr es un motor de búsqueda muy versátil que viene con muchas funciones interesantes que se pueden personalizar según sus requisitos. Drupal funciona muy bien con Apache Solr. Si está buscando expertos en Drupal para configurar un potente motor de búsqueda para su nuevo proyecto, ¡nos encantaría llevarlo más allá!