
Der richtige Weg, eine Seite mit Noindex zu versehen
Veröffentlicht: 2022-12-02Es mag kontraintuitiv erscheinen, aber nicht jede Seite Ihrer Website sollte in den Suchergebnissen erscheinen. Suchmaschinenoptimierung (SEO) strebt danach, die Sichtbarkeit der Suche und den organischen Traffic zu erhöhen – und manchmal können Sie dieses Ziel am besten erreichen, indem Sie einschränken, welche Inhalte in den Suchergebnissen erscheinen dürfen.
Wenn Sie sich am Kopf kratzen oder meinen Bluff nennen, lesen Sie weiter, um den Wert des noindexing einer Seite oder eines Unterverzeichnisses zu entdecken und wie man noindex-Tags implementiert.
Was bedeutet Noindex?
Der Begriff „noindex“ ist eine spezielle Anweisung in einem Robots-Meta-Tag, das Such-Crawlern mitteilt, die Seite von Suchmaschinen-Ergebnisseiten (SERPs) auszuschließen. Das bedeutet, dass Suchende nicht über die Suche auf die Seite zugreifen können.
Robots-Meta-Tags sind ein wertvoller Bestandteil jeder technischen SEO-Strategie und ermöglichen es Ihnen, Seiten auszuschließen, die den Suchenden keinen Mehrwert bieten oder die Informationen enthalten, die Sie nicht in den Suchergebnissen anzeigen möchten, wie z.
- Bestätigungs- und Dankesseiten
- Anmeldeseiten
- Datenschutzrichtlinie oder Seite mit den Nutzungsbedingungen
- Gesperrter Inhalt
- Fehlermeldungen
Robots-Meta-Tag vs. Robots.txt vs. X-Robots-Tag
Das Robots-Meta-Tag wird oft mit der robots.txt-Datei und dem x-robots-Tag verwechselt. Alle drei geben Anweisungen, Crawler nach Seiten zu durchsuchen, und sind Teil des Robots Exclusion Protocol (REP). Einfacher ausgedrückt: Sie teilen Google mit, was in die Google-Suche eingegeben werden soll und was nicht, sowie welche Seiten gecrawlt werden sollen. Sie können und sollten jedoch nicht austauschbar verwendet werden.
Roboter-Meta-Tag
Ein Robots-Meta-Tag wird dem Abschnitt <head> einer bestimmten Webseite hinzugefügt und gibt nur Anweisungen zu dieser bestimmten Seite weiter. Das Robots-Meta-Tag wird oft als Noindex-Tag oder Noindex-Meta-Tag bezeichnet und kann mehr als nur einem Such-Crawler mitteilen, dass er eine Seite nicht indexieren soll.
Es kann auch verwendet werden, um Crawler aufzufordern, Links nicht zu folgen, eine Seite zu übersetzen, einen bestimmten Suchbot zu blockieren oder zu verhindern, dass ein zwischengespeicherter Link in SERPs erscheint.
Zu den gängigen Anweisungen für Robots-Meta-Tags gehören:
- Noindex, nofollow – <meta name=“robots“ content=“noindex, nofollow“>
Googlebot und andere Web-Crawler können auf die Seite zugreifen, sollten sie jedoch nicht indexieren oder ihren Links folgen. - Noindex, follow — <meta name=“robots“ content=“noindex“>
Googlebot und andere Web-Crawler können auf die Seite zugreifen und den Links darauf folgen, aber sie sollten die Seite selbst nicht indexieren. Sie müssen „Folgen“ nicht in das Meta-Tag aufnehmen, da dies die Standardeinstellung ist.
Robots.txt
Robots.txt ist eine Datei, mit der Websitebesitzer Suchmaschinen mitteilen können, welche Teile ihrer Website nicht gecrawlt werden sollen. Es ist wie ein persönliches „Bitte nicht stören“-Schild für Ihre Website, das im Stammverzeichnis Ihrer Domain oder Subdomain hängt.
Eine robots.txt-Datei eignet sich am besten, um den Zugriff auf und das Crawlen ganzer Unterverzeichnisse zu blockieren, anstatt für einzelne Seiten. Verwenden Sie es, um den Zugriff und die Indexierung von Such-Crawlern zu blockieren:
- Interne Suchseiten
- URL-Parameter
- Foren, in denen nutzergenerierter Spam Probleme verursachen kann
- Interne Unterverzeichnisse, wie diejenigen, die nur für Mitarbeiter bestimmt sind
Befolgen Sie diese Schritte, um eine robots.txt-Datei zu erstellen, und achten Sie darauf, einen Link zu Ihrer XML-Sitemap zu erstellen.
Wenn Sie auf eine Seite verlinken, die in Ihrer robots.txt-Datei enthalten ist, möchten Sie ihr möglicherweise auch ein Robots-Meta-Tag hinzufügen, um sicherzustellen, dass sie nicht in den Suchergebnissen angezeigt wird. Denken Sie daran – robots.txt blockiert nur Crawler am Zugriff auf eine Seite, nicht daran, sie zu indizieren. Wenn Seiten, die unter Ihre robots.txt-Anweisungen fallen, externe Links erhalten, können Suchmaschinen sie indizieren. Verwenden Sie ein Robots-Meta-Tag in Verbindung mit der robots.txt-Datei, um dies zu vermeiden.
X-Robots-Tag
Um zu verhindern, dass ein PDF, Video oder Bild in SERPs erscheint, verwenden Sie ein x-robots-Tag. Die gleichen Anweisungen, die für Robots-Meta-Tags angegeben sind, werden für x-Robots verwendet. Im Gegensatz zum Robots-Meta-Tag, das sich im HTML-Header einer Seite befindet, wird ein x-robots-Tag jedoch in die HTTP-Header-Antwort eingefügt.
Die Direktive sieht so aus:
X-Robots-Tag: noindexWann eine Seite noindexiert werden sollte
Curb-Index-Blähung
Index-Bloat tritt auf, wenn Google Seiten mit wenig bis gar keinem Wert für Suchende indiziert. Diese irrelevanten Seiten ziehen Ressourcen von wertvolleren Seiten ab. Verwenden Sie ein Robots-Meta-Tag, um zu verwalten, welche Seiten in den Suchergebnissen erscheinen.
Beseitigen Sie Keyword-Kannibalisierung
Keyword-Kannibalisierung tritt auf, wenn zwei Seiten ein ähnliches Keyword und eine ähnliche Suchabsicht teilen, wodurch sie in den SERPs gegeneinander antreten.
Wenn Sie zwei Seiten haben, die sich gegenseitig ausschlachten, und beide behalten möchten, ohne ihren Inhalt zu ändern, noindex one. Das heißt, Sie sollten dies nur tun, wenn die Seite, die Sie nicht indexieren, keinen Verkehr von Schlüsselwörtern antreibt, die die andere Seite nicht hat. In einer solchen Situation müssen Sie möglicherweise den Inhalt auf einer oder beiden Seiten überarbeiten, um das Kannibalisierungsproblem zu lösen.
Schützen Sie Gated Landing Pages
Wenn Sie Kunden im Austausch für Kontaktinformationen eine wertvolle Ressource anbieten, stellen Sie sicher, dass sie nicht auf andere Weise zugänglich ist. Fügen Sie ein Robots-Meta-Tag hinzu, um die Seite zu noindexen und zu verhindern, dass sie in SERPs erscheint.
Schließen Sie unbeliebte Produkte von der Suche aus
E-Commerce-Websites bieten oft Produkte an, um bestimmte Kunden zu bedienen, obwohl keine allzu große Nachfrage danach besteht. Beispielsweise kann ein Autoteilehändler oder ein anderes technisches Unternehmen Produkte für bestimmte Modelle oder seltene Geräte haben. Wenn diese Produkt- oder Kategorieseiten keinen organischen Traffic antreiben, können sie im Allgemeinen nicht indexiert werden.
So noindexieren Sie eine Webseite
Das Meta-Tag noindex wird in den Header des HTML einer Seite eingefügt. Der Code unterscheidet nicht zwischen Groß- und Kleinschreibung und sieht folgendermaßen aus:
<meta name="robots" content="noindex">„Roboter“ bedeutet, dass die Richtlinie für jeden Crawler gilt, aber Sie können Crawler herausgreifen, indem Sie „Roboter“ durch bekannte Crawler-Namen wie „Googlebot“ oder „Bingbot“ ersetzen.

Crawler folgen weiterhin Links auf der Seite, es sei denn, Sie fügen auch einen nofollow-Befehl hinzu. Sie können dies tun, um zu verhindern, dass Link Equity durch die Seite fließt, oder um zu verhindern, dass ein Crawler einem Link zu Gated Content folgt.
Um einen nofollow-Wert hinzuzufügen, trennen Sie ihn durch ein Komma von der noindex-Direktive.
<meta name="robots" content="noindex, nofollow">Hinweis: Bevor Sie eine Seite noindexieren, überprüfen Sie in der Google Search Console, ob sie eingehenden organischen Traffic hat. Wenn dies der Fall ist, bestimmen Sie, wie Ihre Website diesen Datenverkehr weiterhin erfassen kann, bevor Sie die Seite noindexieren.
So fügen Sie Ihrem HTML-Code ein Robots-Meta-Tag hinzu
- Öffnen Sie den Quellcode der Seite, die Sie noindexen möchten.
- Suchen Sie die Kopfzeile oben auf der Seite. Es beginnt mit <head> und endet mit </head>. Es wird wahrscheinlich auch anderen Code im Header geben.
- Fügen Sie das Robots-Meta-Tag in einer neuen Zeile hinzu und stellen Sie sicher, dass es zwischen den Tags <head> und </head> erscheint.
Das ist es! Wenn Ihre Seite bereits indexiert ist, können Sie Google bitten, sie erneut zu crawlen, indem Sie ihre URL in das URL-Prüftool einfügen.
Bereits indiziert? Verwenden Sie das Tool zum Entfernen von URLs
Wenn Sie einer neuen Inhaltsseite ein noindex-Tag hinzufügen, sieht der Googlebot die Anweisung beim Crawlen der Seite und indexiert sie nicht.
Wenn Sie das Tag jedoch zu einer bereits indexierten Seite hinzufügen , wird die Seite weiterhin in den Suchergebnissen angezeigt, bis sie erneut gecrawlt wird und die Bots die neuen noindex-Anweisungen sehen. Sie können Google bitten, die URL in der Google Search Console über das URL-Inspektionstool erneut zu crawlen, aber die Seite wird nicht sofort aus den SERPs entfernt.
Wenn Sie eine Seite sofort aus SERP entfernen müssen, verwenden Sie das Entfernungstool in der Google Search Console. Dadurch werden Seiten etwa sechs Monate lang nicht in den Google-Suchergebnissen angezeigt. Bis dahin sollte das Meta-Tag noindex funktionieren.
Wie man eine Seite auf WordPress noindexiert
Jede Seite in WordPress wird standardmäßig indiziert. Sie können das Yoast SEO-Plugin verwenden, um eine Seite in WordPress zu noindexieren, ohne Code schreiben zu müssen. Hier ist wie.
Klicken Sie im Yoast SEO-Metafeld auf die Registerkarte „Erweitert“.
Unter der Frage „Erlauben Sie Suchmaschinen, diesen Beitrag in den Suchergebnissen anzuzeigen?“ Wählen Sie im Dropdown-Feld „Nein“ aus.
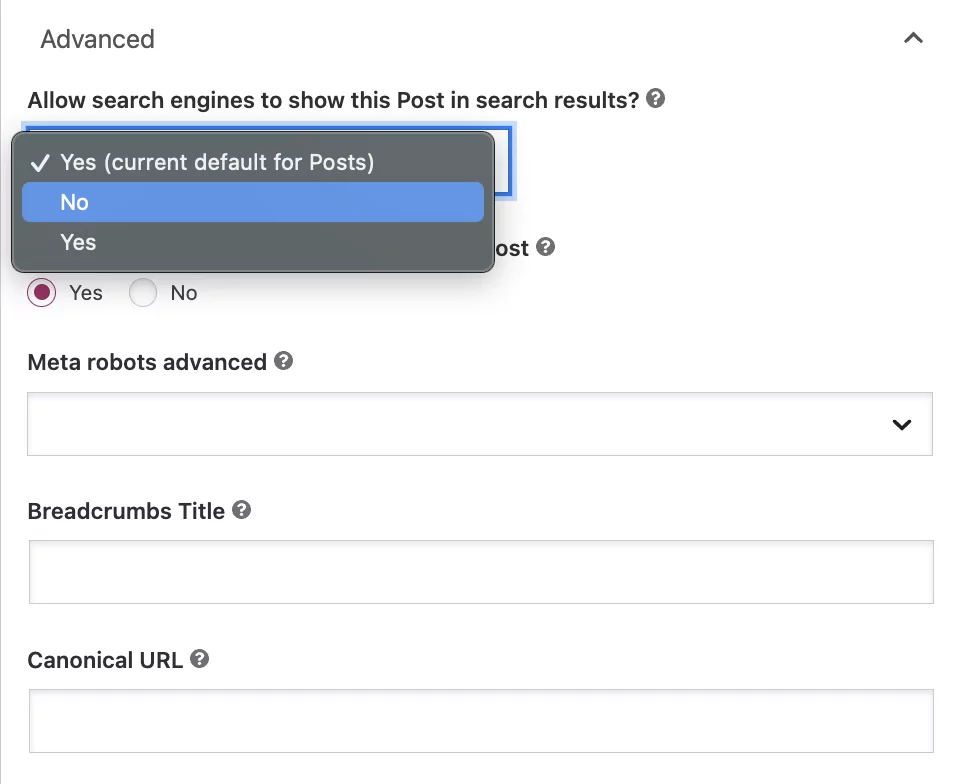
Während diese Einstellung Google anweist, den Beitrag nicht zu indexieren, folgen Bots dennoch automatisch Links auf der Seite, um andere Seiten zu crawlen.
Wenn Sie eine Nofollow-Anweisung hinzufügen möchten, wählen Sie die Schaltfläche „Nein“ unter der Frage: „Sollen Suchmaschinen Links in diesem Beitrag folgen?“.
Häufig gestellte Fragen zu Roboter-Meta-Tags
Befolgen alle Suchmaschinen eine Noindex-Direktive?
Sie können davon ausgehen, dass Google, Bing und andere legitime Suchmaschinen sich an ein Robots-Meta-Tag halten.
Kann ich auf nicht indexierte Seiten verlinken?
Ja. Das noindex-Tag teilt Suchbots mit, wie eine Seite beim Crawlen und Indexieren behandelt werden soll. Es hat keinen Einfluss auf Ihre Fähigkeit, auf eine Seite zu verlinken. Dies kann für Kategorieseiten in einem Blog nützlich sein, die nicht in den Suchergebnissen erscheinen sollen, aber die Bots mit Links zu wertvollen Seiten versorgen können, die sollten.
Wann sollte ich ein Robots-Meta-Tag verwenden?
Wenn Sie eine Seite haben, die den Suchenden keinen Wert bietet, wie z. B. eine Dankeschön-Seite oder eine druckerfreundliche Seite, noindexieren Sie sie mit einem Robots-Meta-Tag, damit sie nicht in SERPs erscheint.
Wann sollte ich keine noindex-Direktive verwenden?
Sie können Probleme mit doppelten Inhalten und einige Probleme mit dem Crawl-Budget technisch mit noindex-Anweisungen lösen, aber dies ist nicht der beste Weg, dies zu tun. Duplicate Content wird am besten mit Canonical Tags gehandhabt, die den Linkwert der Duplikate auf die kanonische Seite konzentrieren. Wenn Sie versuchen, das Crawling-Budget zu schonen, sollten Sie die robots.txt-Datei verwenden, um das Crawlen dieses Abschnitts der Website zu unterbinden.
Geben noindizierte Seiten Link Equity weiter?
Ja. Auch wenn eine Seite nicht indexiert ist, kann sie dennoch jede aufgebaute Ranking-Autorität teilen. Such-Crawler müssen jedoch in der Lage sein, Links auf der Seite zu folgen, damit Link-Equity durchfließen kann. Wenn eine Seite auf noindex und nofollow gesetzt ist, kann sie kein Link-Equity weitergeben.
Wird eine Seite durch Noindexing automatisch aus den Google-SERPs entfernt?
Wenn Ihre Seite bereits indexiert ist, wird sie durch das Hinzufügen eines Robots-Meta-Tags nicht automatisch aus den Suchergebnissen entfernt. Es dauert einige Zeit, bis bereits indexierte Seiten aus den SERPs verschwinden. Such-Bots müssen die Seiten erneut crawlen, um das noindex-Tag zu sehen. Fordern Sie für schnellere Ergebnisse an, dass Google die Seite erneut crawlt und das Tool zum Entfernen von URLs verwendet.
Entdecken Sie problematische Seiten mit einem SEO-Audit
Lassen Sie nicht zu, dass dünne oder doppelte Inhalte Ihre Sichtbarkeit in der Suche beeinträchtigen. Stellen Sie sicher, dass Sie Ihren Seiten die beste Chance geben, einen Rang einzunehmen. Unser 200+-Punkte-SEO-Audit kennzeichnet Probleme wie doppelte Inhalte, eine fehlende robots.txt-Datei, falsch angewendete Robots-Meta-Tags, aufgeblähte Indizes und mehr. Melden Sie sich für eine kostenlose SEO-Beratung an, um zu erfahren, wie unser SEO-Audit-Service Ihre Online-Präsenz maximieren und Ihrem Unternehmen zum Wachstum verhelfen kann.