
So konfigurieren Sie die robots.txt-Datei von Magento 2 für SEO
Veröffentlicht: 2021-01-21Inhaltsverzeichnis
SEO ist ein wichtiger Faktor für den Erfolg Ihres Shops, und eine richtig konfigurierte robots.txt trägt nicht zuletzt dazu bei, die Arbeit von Suchmaschinen-Crawlern zu erleichtern.
Was ist robots.txt?
Kurz gesagt, robots.txt ist eine Datei, die Suchmaschinen-Crawler anweist, was sie crawlen können und was nicht. Ohne eine robots.txt in Ihrem Stammverzeichnis werden Suchmaschinen-Crawler, die auf Ihren Shop stoßen, alles durchsuchen, was sie können, und dazu gehören auch doppelte oder unwichtige Seiten, für die die Suchmaschinen-Crawler ihr Crawl-Budget nicht verschwenden sollen. Eine robots.txt sollte in der Lage sein, dies zu beheben.
Hinweis : Die robots.txt-Datei sollte nicht verwendet werden, um Ihre Webseiten vor Google zu verbergen. Verwenden Sie zu diesem Zweck stattdessen das Meta-Tag noindex .
Standard-robots.txt-Anweisungen in Magento 2
Standardmäßig enthält die von Magento generierte robots.txt-Datei nur einige grundlegende Anweisungen für den Webcrawler.
# Von Magento bereitgestellte Standardanweisungen User-Agent: * Nicht zulassen: /lib/ Nicht zulassen: /*.php$ Nicht zulassen: /pkginfo/ Nicht zulassen: /bericht/ Nicht zulassen: /var/ Nicht zulassen: /Katalog/ Nicht zulassen: /Kunde/ Nicht zulassen: /sendfriend/ Nicht zulassen: /review/ Nicht zulassen: /*SID=
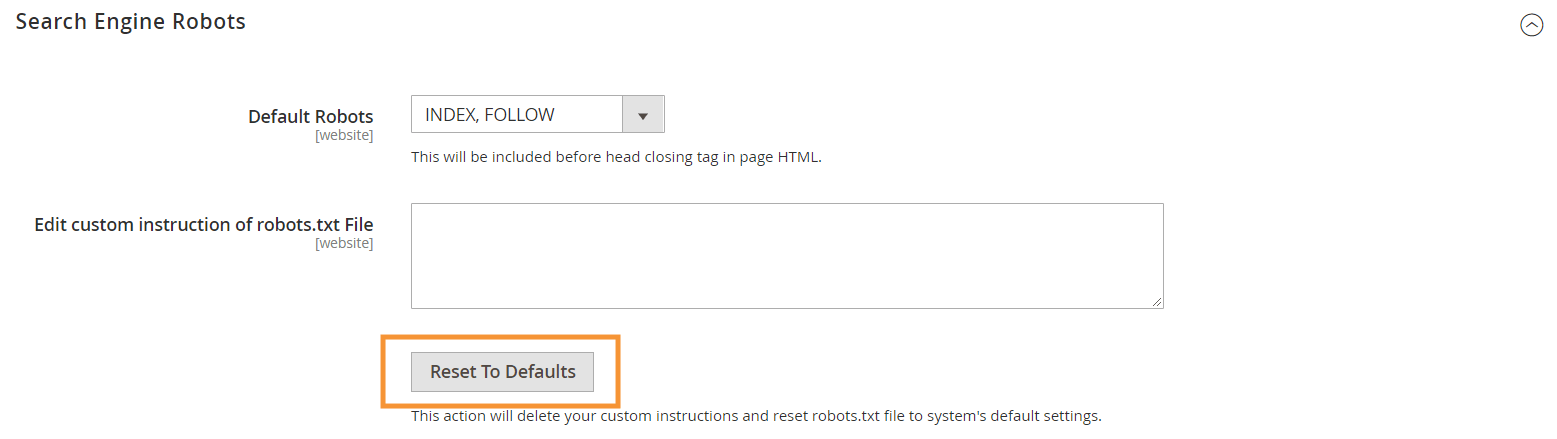
Um diese Standardanweisungen zu generieren , klicken Sie in der Search Engine Robots-Konfiguration in Ihrem Magento-Backend auf die Schaltfläche Auf Standardwerte zurücksetzen.
Warum Sie benutzerdefinierte robots.txt-Anweisungen in Magento 2 erstellen müssen
Während die von Magento bereitgestellten standardmäßigen robots.txt-Anweisungen erforderlich sind, um Crawlern mitzuteilen, dass bestimmte Dateien, die intern vom System verwendet werden, nicht gecrawlt werden sollen, reichen sie für die meisten Magento-Shops nicht annähernd aus.
Suchmaschinen-Robots haben nur eine begrenzte Menge an Ressourcen zum Crawlen von Webseiten. Für eine Website mit Tausenden oder sogar Millionen von URLs, die gecrawlt werden müssen (was häufiger vorkommt, als Sie denken), müssen Sie die Art des zu crawlenden Inhalts priorisieren (mit einer sitemap.xml) und irrelevante URLs verbieten verhindern, dass Seiten gecrawlt werden (mit einer robots.txt). Der letzte Teil erfolgt, indem verhindert wird, dass duplizierte, irrelevante und unnötige Seiten in Ihrer robots.txt gecrawlt werden.
Grundformat von robots.txt-Anweisungen
Die Anweisungen in der robots.txt-Datei sind kohärent und für technisch nicht versierte Benutzer geeignet:
# Regel 1 User-Agent: Googlebot Nicht zulassen: /nogooglebot/ # Regel 2 User-Agent: * Erlauben: / Sitemap: https://www.example.com/sitemap.xml
-
User-agent: Gibt den spezifischen Crawler an, für den die Regel gilt. Einige gängige User-Agents sindGooglebot,Googlebot-Image,Mediapartners-Google,Googlebot-Videousw. Eine ausführliche Liste gängiger Crawler finden Sie unter Übersicht über Google-Crawler.
-
Allow&Disallow: Geben Sie Pfade an, auf die die designierten Crawler zugreifen können oder nicht.Allow: /bedeutet beispielsweise, dass der Crawler uneingeschränkt auf die gesamte Website zugreifen kann.
-
Sitemap: Gibt den Pfad zur Sitemap für Ihr Geschäft an. Sitemap ist eine Möglichkeit, Suchmaschinen-Crawlern mitzuteilen, welche Inhalte priorisiert werden sollen, während der Rest des Inhalts in robots.txt Crawlern mitteilt, welche Inhalte sie crawlen können oder nicht.
Auch in robots.txt können Sie mehrere Platzhalter für Pfadwerte verwenden, wie zum Beispiel:

-
*: Wenn es inuser-agenteingefügt wird, bezieht sich das Sternchen (*) auf alle Suchmaschinen-Crawler (mit Ausnahme von AdsBot-Crawlern), die die Website besuchen. Wenn es in denAllow/DisallowDirektiven verwendet wird, bedeutet es 0 oder mehr Instanzen eines beliebigen gültigen Zeichens (z. B.Allow: /example*.cssstimmt mit /example.css überein und auch mit / example12345.css ). -
$: bezeichnet das Ende einer URL. Beispielsweise blockiertDisallow: /*.php$alle Dateien, die auf .php enden -
#: bezeichnet den Beginn eines Kommentars, der von Crawlern ignoriert wird.
Hinweis : Mit Ausnahme des sitemap.xml-Pfads sind Pfade in robots.txt immer relativ , was bedeutet, dass Sie keine vollständigen URLs (z. B. https://simicart.com/nogooglebot/) verwenden können, um Pfade anzugeben.
robots.txt in Magento 2 konfigurieren
So greifen Sie in Ihrem Magento 2-Adminbereich auf den robots.txt-Dateieditor zu:
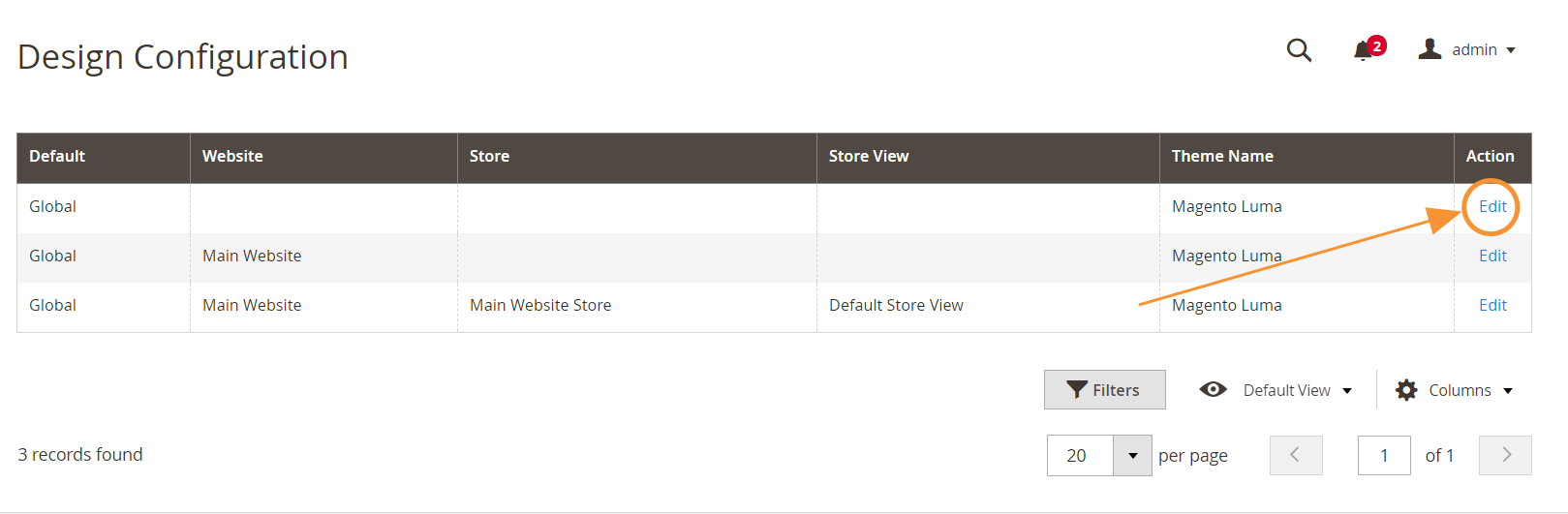
Schritt 1 : Gehen Sie zu Inhalt > Design > Konfiguration
Schritt 2 : Bearbeiten Sie die globale Konfiguration in der ersten Zeile
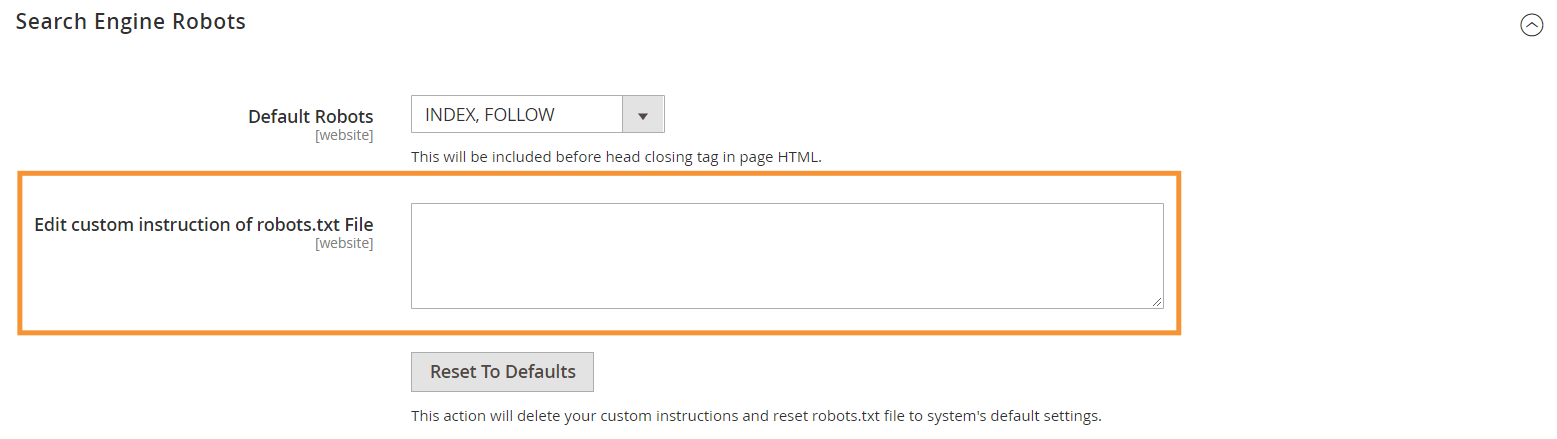
Schritt 3 : Bearbeiten Sie im Abschnitt Search Engine Robots benutzerdefinierte Anweisungen
Empfohlene robots.txt-Anweisungen
Hier ist unsere empfohlene Anleitung, die den allgemeinen Anforderungen entsprechen sollte. Natürlich ist jedes Geschäft anders und Sie müssen möglicherweise ein paar weitere Regeln anpassen oder hinzufügen, um die besten Ergebnisse zu erzielen.
User-Agent: * # Standardanweisungen: Nicht zulassen: /lib/ Nicht zulassen: /*.php$ Nicht zulassen: /pkginfo/ Nicht zulassen: /bericht/ Nicht zulassen: /var/ Nicht zulassen: /Katalog/ Nicht zulassen: /Kunde/ Nicht zulassen: /sendfriend/ Nicht zulassen: /review/ Nicht zulassen: /*SID= # Übliche Magento-Dateien im Root-Verzeichnis verbieten: Nicht zulassen: /cron.php Nicht zulassen: /cron.sh Nicht zulassen: /error_log Nicht zulassen: /install.php Nicht zulassen: /LICENSE.html Nicht zulassen: /LICENSE.txt Nicht zulassen: /LICENSE_AFL.txt Nicht zulassen: /STATUS.txt # Benutzerkonto verbieten & Checkout-Seiten: Nicht zulassen: /checkout/ Nicht zulassen: /onestepcheckout/ Nicht zulassen: /Kunde/ Nicht zulassen: /Kunde/Konto/ Nicht zulassen: /Kunde/Konto/Login/ # Katalogsuchseiten nicht zulassen: Nicht zulassen: /catalogsearch/ Nicht zulassen: /catalog/product_compare/ Nicht zulassen: /catalog/category/view/ Nicht zulassen: /catalog/product/view/ # URL-Filtersuche verbieten Nicht zulassen: /*?dir* Nicht zulassen: /*?dir=desc Nicht zulassen: /*?dir=asc Nicht zulassen: /*?limit=all Nicht zulassen: /*?modus* # CMS-Verzeichnisse verbieten: Nicht zulassen: /app/ Nicht zulassen: /bin/ Nicht zulassen: /dev/ Nicht zulassen: /lib/ Nicht zulassen: /phpserver/ Nicht zulassen: /pub/ # Duplicate Content verbieten: Nicht zulassen: /tag/ Nicht zulassen: /review/ Nicht zulassen: /*?*product_list_mode= Nicht zulassen: /*?*product_list_order= Nicht zulassen: /*?*product_list_limit= Nicht zulassen: /*?*product_list_dir= # Server Einstellungen # Allgemeine technische Verzeichnisse und Dateien auf einem Server verbieten Nicht zulassen: /cgi-bin/ Nicht zulassen: /cleanup.php Nicht zulassen: /apc.php Nicht zulassen: /memcache.php Nicht zulassen: /phpinfo.php # Versionskontrollordner und andere nicht zulassen Nicht zulassen: /*.git Nicht zulassen: /*.CVS Nicht zulassen: /*.Zip$ Nicht zulassen: /*.Svn$ Nicht zulassen: /*.Idee$ Nicht zulassen: /*.Sql$ Nicht zulassen: /*.Tgz$ Sitemap: https://www.example.com/sitemap.xml
Fazit
Das Erstellen einer robots.txt-Datei ist nur einer der vielen Schritte in der Magento-SEO-Checkliste – und die richtige Optimierung eines Magento-Shops für Suchmaschinen ist sicherlich keine leichte Aufgabe für die meisten Shop-Inhaber. Wenn Sie sich damit nicht beschäftigen möchten, können wir uns um alles für Sie kümmern. Hier bei SimiCart bieten wir SEO- und Geschwindigkeitsoptimierungsdienste an, die die besten Ergebnisse für Ihr Geschäft garantieren.