
Was ist Kubernetes-Architektur? Bedeutung + Best Practices
Veröffentlicht: 2023-06-12Die Akzeptanz von Kubernetes hat seit 2014 enorm zugenommen. Inspiriert durch Googles interne Cluster-Management-Lösung Borg vereinfacht Kubernetes die Bereitstellung und Verwaltung Ihrer Anwendungen. Wie jede Container-Orchestrierungssoftware erfreut sich Kubernetes bei IT-Experten immer größerer Beliebtheit, da es sicher und unkompliziert ist. Doch wie bei jedem Tool hilft Ihnen das Erkennen, wie seine Architektur Ihnen dabei hilft, es effektiver zu nutzen.
Lassen Sie uns etwas über die Grundlagen der Kubernetes-Architektur lernen, beginnend damit, was sie ist, was sie tut und warum sie wichtig ist.
Was ist Kubernetes-Architektur?
Kubernetes oder Kubernetes-Architektur ist eine Open-Source-Plattform zum Verwalten und Bereitstellen von Containern. Es bietet Serviceerkennung, Lastausgleich, regenerative Mechanismen, Container-Orchestrierung, Container-Laufzeit und Infrastruktur-Orchestrierung mit Schwerpunkt auf Containern.
Google hat das anpassungsfähige Containerverwaltungssystem Kubernetes entwickelt, das containerisierte Anwendungen in vielen Umgebungen verwaltet. Es hilft dabei, die Bereitstellung von Containeranwendungen zu automatisieren, Änderungen vorzunehmen und diese Anwendungen zu vergrößern und zu verkleinern.
Kubernetes ist jedoch nicht nur ein Container-Orchestrator . Ebenso funktionieren Desktop-Apps unter MacOS, Windows oder Linux; Es ist das Betriebssystem für Cloud-native Anwendungen, da es als Cloud-Plattform für diese Programme dient.
Was ist ein Container?
Container sind ein Standardansatz zum Verpacken von Anwendungen und ihren Abhängigkeiten, damit die Anwendungen problemlos über Laufzeitumgebungen hinweg ausgeführt werden können. Mithilfe von Containern können Sie wesentliche Maßnahmen zur Verkürzung der Bereitstellungszeit und zur Erhöhung der Anwendungszuverlässigkeit ergreifen, indem Sie den Code, die Abhängigkeiten und die Konfigurationen einer App in einem einzigen, benutzerfreundlichen Baustein packen.
Die Anzahl der Container in Unternehmensanwendungen kann unüberschaubar werden. Um das Beste aus Ihren Containern herauszuholen, unterstützt Sie Kubernetes bei der Orchestrierung.
Wofür wird Kubernetes verwendet?
Kubernetes ist eine unglaublich anpassungsfähige und erweiterbare Plattform für die Ausführung von Container-Workloads. Die Kubernetes-Plattform bietet nicht nur die Umgebung zum Erstellen cloudnativer Anwendungen, sondern hilft auch bei der Verwaltung und Automatisierung ihrer Bereitstellungen.
Ziel ist es, Anwendungsbetreiber und Entwickler von der Koordinierung der zugrunde liegenden Rechen-, Netzwerk- und Speicherinfrastruktur zu entlasten und ihnen die Möglichkeit zu geben, sich ausschließlich auf Container-zentrierte Prozesse für den Self-Service-Betrieb zu konzentrieren. Entwickler können außerdem spezielle Bereitstellungs- und Verwaltungsverfahren sowie einen höheren Automatisierungsgrad für Anwendungen erstellen, die aus mehreren Containern bestehen.
Kubernetes kann alle wichtigen Backend-Workloads bewältigen, einschließlich monolithischer Anwendungen, zustandsloser oder zustandsbehafteter Programme, Microservices, Dienste, Batch-Jobs und alles dazwischen.
Kubernetes wird häufig aufgrund der folgenden Vorteile ausgewählt.
- Die Infrastruktur von Kubernetes ist der vieler DevOps-Technologien überlegen.
- Kubernetes zerlegt Container zur präzisen Verwaltung in kleinere Komponenten.
- Kubernetes stellt Software-Updates schnell und regelmäßig bereit.
- Kubernetes bietet eine Plattform für die Entwicklung cloudnativer Apps.
Kubernetes-Architektur und -Komponenten
Die grundlegende Kubernetes-Architektur besteht aus vielen Komponenten, die auch als K8s-Komponenten bezeichnet werden. Bevor wir also direkt loslegen, ist es wichtig, sich die folgenden Konzepte zu merken.
- Die grundlegende Kubernetes-Architektur besteht aus einer Steuerungsebene, die Knoten und Worker-Knoten verwaltet, die containerisierte Apps ausführen.
- Während die Steuerungsebene die Ausführung und Kommunikation verwaltet, führen Worker-Knoten diese Container tatsächlich aus.
- Ein Kubernetes-Cluster ist eine Gruppe von Knoten, und jeder Cluster verfügt über mindestens einen Worker-Knoten.
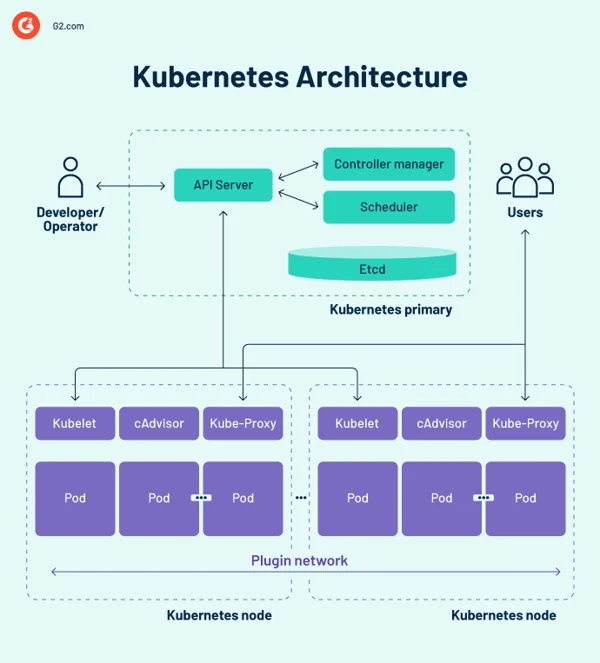
Kubernetes-Architekturdiagramm
Kubernetes-Steuerungsebene
Die Kontrollebene ist das zentrale Nervensystem des Kubernetes-Cluster-Designs und beherbergt die Kontrollkomponenten des Clusters. Außerdem werden die Konfiguration und der Status aller Kubernetes-Objekte im Cluster aufgezeichnet.
Die Kubernetes-Steuerungsebene kommuniziert regelmäßig mit den Recheneinheiten, um sicherzustellen, dass der Cluster wie erwartet funktioniert. Controller überwachen Objektzustände und passen den physischen, beobachteten oder aktuellen Status von Systemobjekten als Reaktion auf Clusteränderungen an den gewünschten Zustand oder die gewünschte Spezifikation an.
Die Steuerungsebene besteht aus mehreren wesentlichen Elementen, darunter dem API-Server (Application Programming Interface), dem Scheduler, dem Controller-Manager und etcd. Diese grundlegenden Kubernetes-Komponenten garantieren, dass Container mit den entsprechenden Ressourcen ausgeführt werden. Diese Komponenten können alle auf einem einzigen Primärknoten funktionieren, viele Unternehmen duplizieren sie jedoch für eine hohe Verfügbarkeit auf mehreren Knoten.
1. Kubernetes-API-Server
Der Kubernetes-API-Server ist das Frontend der Kubernetes-Steuerungsebene. Es erleichtert Aktualisierungen, Skalierung, Konfiguration von Daten und andere Arten der Lebenszyklus-Orchestrierung, indem es API-Management für verschiedene Anwendungen bietet. Da der API-Server das Gateway ist, müssen Benutzer von außerhalb des Clusters darauf zugreifen können. In diesem Fall ist der API-Server ein Tunnel zu Pods, Diensten und Knoten. Benutzer authentifizieren sich über den API-Server.
2. Kubernetes-Planer
Der Kube-Scheduler zeichnet Statistiken zur Ressourcennutzung für jeden Rechenknoten auf, bewertet, ob ein Cluster fehlerfrei ist, und entscheidet, ob und wo neue Container bereitgestellt werden sollen. Der Scheduler bewertet den Gesamtzustand des Clusters und den Ressourcenbedarf des Pods, z. B. Zentraleinheit (CPU) oder Speicher. Anschließend wählt es einen geeigneten Rechenknoten aus und plant die Aufgabe, den Pod oder den Dienst unter Berücksichtigung von Ressourcenbeschränkungen oder -zusicherungen, Datenlokalität, Anforderungen an die Dienstqualität, Anti-Affinität oder Affinitätsstandards.
3. Kubernetes-Controller-Manager
In einer Kubernetes-Umgebung steuern mehrere Controller den Status von Endpunkten (Pods und Dienste), Token und Dienstkonten (Namespaces), Knoten und Replikation (Autoscaling). Der Kube-Controller-Manager, oft auch als Cloud-Controller-Manager oder einfach als Controller bezeichnet, ist ein Daemon, der den Kubernetes-Cluster verwaltet, indem er verschiedene Controller-Aufgaben ausführt.
Der Controller überwacht die Objekte im Cluster, während er die Kubernetes-Kernregelkreise ausführt. Es überwacht sie über den API-Server auf ihren gewünschten und vorhandenen Zustand. Wenn der aktuelle und der beabsichtigte Status verwalteter Objekte nicht übereinstimmen, ergreift der Controller Korrekturmaßnahmen, um den Objektstatus näher an den gewünschten Status zu bringen. Der Kubernetes-Controller übernimmt auch wesentliche Lebenszyklusaufgaben.
4. usw
etcd ist eine verteilte, fehlertolerante Schlüsselwertspeicherdatenbank, die Konfigurationsdaten und Clusterstatusinformationen speichert. Obwohl etcd unabhängig eingerichtet werden kann, dient es oft als Teil der Kubernetes-Steuerungsebene.
Der Raft-Konsensalgorithmus wird verwendet, um den Clusterstatus in etcd beizubehalten. Dies hilft bei der Bewältigung eines typischen Problems im Zusammenhang mit replizierten Zustandsmaschinen und erfordert, dass sich viele Server auf Werte einigen. Raft legt drei Rollen fest: Anführer, Kandidat und Gefolgsmann und schafft Konsens, indem es für einen Anführer stimmt.
Dadurch ist etcd die einzige Quelle der Wahrheit (Single Source of Truth, SSOT) für alle Kubernetes-Clusterkomponenten, die auf Abfragen der Steuerungsebene antwortet und verschiedene Informationen über den Zustand von Containern, Knoten und Pods sammelt. etcd wird auch zum Speichern von Konfigurationsinformationen wie ConfigMaps, Subnetzen, Geheimnissen und Cluster-Statusdaten verwendet.
Kubernetes-Worker-Knoten
Worker-Knoten sind Systeme, die Container ausführen, die von der Steuerungsebene verwaltet werden. Das Kubelet – der zentrale Kubernetes-Controller – läuft auf jedem Knoten als Agent für die Interaktion mit der Steuerungsebene. Darüber hinaus führt jeder Knoten eine Container-Laufzeit-Engine wie Docker oder rkt aus. Auf dem Knoten werden auch weitere Komponenten zur Überwachung, Protokollierung, Serviceerkennung und optionalen Extras ausgeführt.
Einige wichtige Komponenten der Kubernetes-Clusterarchitektur sind wie folgt.
Knoten
Ein Kubernetes-Cluster muss über mindestens einen Rechenknoten verfügen, es können jedoch je nach Kapazitätsanforderungen noch viele weitere vorhanden sein. Da Pods für die Ausführung auf Knoten koordiniert und geplant werden, sind zusätzliche Knoten erforderlich, um die Clusterkapazität zu erhöhen. Knoten erledigen die Arbeit eines Kubernetes-Clusters. Sie verknüpfen Anwendungen sowie Netzwerk-, Rechen- und Speicherressourcen.
Knoten in Rechenzentren können Cloud-native virtuelle Maschinen (VMs) oder Bare-Metal-Server sein.
Container-Laufzeit-Engine
Jeder Rechenknoten verwendet eine Container-Laufzeit-Engine, um Container-Lebenszyklen zu betreiben und zu verwalten. Kubernetes unterstützt Open-Container-Initiative-kompatible Laufzeiten wie Docker, CRI-O und rkt.
Kubelet-Dienst
Auf jedem Rechenknoten ist ein Kubelet enthalten. Dabei handelt es sich um einen Agenten, der mit der Steuerungsebene kommuniziert, um sicherzustellen, dass die Container in einem Pod funktionieren. Wenn die Steuerungsebene verlangt, dass eine bestimmte Aktion in einem Knoten ausgeführt wird, ruft das Kubelet die Pod-Spezifikationen über den API-Server ab und führt den Betrieb aus. Anschließend wird sichergestellt, dass die entsprechenden Behälter in einwandfreiem Zustand sind.
Kube-Proxy-Dienst
Jeder Rechenknoten verfügt über einen Netzwerk-Proxy, den sogenannten Kube-Proxy, der Kubernetes-Netzwerkdienste unterstützt. Um Netzwerkverbindungen innerhalb und außerhalb des Clusters zu verwalten, leitet der Kube-Proxy entweder den Datenverkehr weiter oder ist auf die Paketfilterschicht des Betriebssystems angewiesen.

Der Kube-Proxy-Prozess wird auf jedem Knoten ausgeführt, um sicherzustellen, dass Dienste für andere Parteien verfügbar sind, und um bestimmte Host-Subnetze zu bewältigen. Es fungiert als Netzwerk-Proxy und Service-Load-Balancer auf seinem Knoten und übernimmt das Netzwerk-Routing für den Datenverkehr des User Datagram Protocol (UDP) und des Transmission Control Protocol (TCP). Der Kube-Proxy leitet in Wirklichkeit den Datenverkehr für alle Dienstendpunkte weiter.
Schoten
Bisher haben wir interne und infrastrukturbezogene Ideen behandelt. Pods sind jedoch für Kubernetes von entscheidender Bedeutung, da sie die primären, nach außen gerichteten Komponenten sind, mit denen Entwickler interagieren.
Ein Pod ist die einfachste Einheit im Kubernetes-Containermodell und stellt eine einzelne Instanz einer Anwendung dar. Jeder Pod besteht aus einem Container oder mehreren eng verbundenen Containern, die logisch zusammenpassen und die Regeln ausführen, die die Funktion des Containers bestimmen.
Pods haben eine begrenzte Lebensdauer und sterben letztendlich, nachdem sie aufgerüstet oder verkleinert wurden. Obwohl sie kurzlebig sind, führen sie zustandsbehaftete Anwendungen aus, indem sie eine Verbindung zum persistenten Speicher herstellen.
Pods können auch horizontal skaliert werden, was bedeutet, dass sie die Anzahl der ausgeführten Instanzen erhöhen oder verringern können. Sie sind auch in der Lage, fortlaufende Updates und Canary-Bereitstellungen durchzuführen.
Pods arbeiten gemeinsam auf Knoten, sodass sie Inhalte und Speicher gemeinsam nutzen und möglicherweise über localhost mit anderen Pods kommunizieren. Container können sich über mehrere Computer erstrecken, ebenso wie Pods. Ein einzelner Knoten kann mehrere Pods betreiben, die jeweils zahlreiche Container sammeln.
Der Pod ist die zentrale Verwaltungseinheit im Kubernetes-Ökosystem und dient als logische Grenze für Container, die Ressourcen und Kontext teilen. Die Pod-Gruppierungsmethode, die den gleichzeitigen Betrieb mehrerer abhängiger Prozesse ermöglicht, mildert die Unterschiede zwischen Virtualisierung und Containerisierung.
Arten von Schoten
Im Kubernetes-Containermodell spielen mehrere Arten von Pods eine wichtige Rolle.
- Der Standardtyp ReplicaSet garantiert, dass die angegebene Anzahl von Pods betriebsbereit ist.
- Die Bereitstellung ist eine deklarative Methode zur Verwaltung von ReplicaSets-basierten Pods. Dazu gehören Rollback- und Rolling-Update-Mechanismen.
- Daemonset stellt sicher, dass jeder Knoten eine Instanz eines Pods ausführt. Es kommen Clusterdienste wie Health Monitoring und Log-Weiterleitung zum Einsatz.
- StatefulSet wurde für die Verwaltung von Pods entwickelt, die den Status beibehalten oder beibehalten müssen.
- Job und CronJob führen einmalige oder vordefinierte geplante Jobs aus.
Andere Komponenten der Kubernetes-Architektur
Kubernetes verwaltet die Container einer Anwendung, kann aber auch die zugehörigen Anwendungsdaten in einem Cluster verwalten. Benutzer von Kubernetes können Speicherressourcen anfordern, ohne die zugrunde liegende Speicherinfrastruktur zu verstehen.
Ein Kubernetes-Volume ist ein Verzeichnis, in dem ein Pod auf Daten zugreifen und diese speichern kann. Der Datenträgertyp bestimmt den Inhalt des Datenträgers, seine Entstehung und die Medien, die ihn unterstützen. Persistente Volumes (PVs) sind Cluster-spezifische Speicherressourcen, die häufig von einem Administrator bereitgestellt werden. PVs können auch einen bestimmten Pod überleben.
Kubernetes ist auf Container-Images angewiesen, die in einer Container-Registrierung gespeichert sind. Dabei kann es sich um ein Register eines Drittanbieters handeln oder um eines, das von der Organisation erstellt wird.
Namespaces sind virtuelle Cluster, die innerhalb eines physischen Clusters existieren. Sie sind darauf ausgelegt, unabhängige Arbeitsumgebungen für zahlreiche Benutzer und Teams zu schaffen. Sie verhindern außerdem, dass Teams sich gegenseitig stören, indem sie die Kubernetes-Objekte einschränken, auf die sie zugreifen können. Kubernetes-Container innerhalb eines Pods können über localhost mit anderen Pods kommunizieren und IP-Adressen und Netzwerk-Namespaces gemeinsam nutzen.
Kubernetes vs. Docker Swarm
Sowohl Kubernetes als auch Docker sind Plattformen, die Containerverwaltung und Anwendungsskalierung ermöglichen. Kubernetes bietet eine effektive Container-Management-Lösung, die sich ideal für Anwendungen mit hoher Nachfrage und kompliziertem Setup eignet. Im Gegensatz dazu ist Docker Swarm auf Einfachheit ausgelegt und daher eine ausgezeichnete Wahl für wichtige Apps, die schnell bereitgestellt und gewartet werden können.
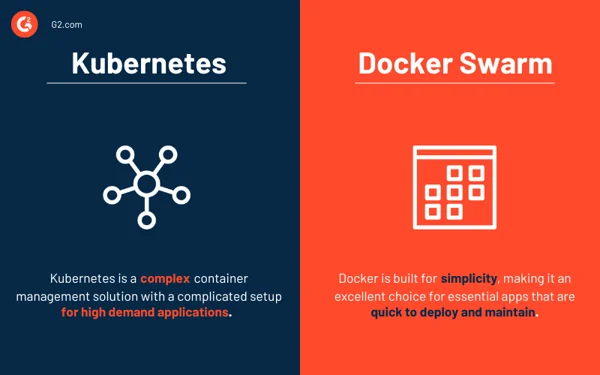
- Docker Swarm ist einfacher bereitzustellen und zu konfigurieren als Kubernetes.
- Kubernetes bietet All-in-One-Skalierbarkeit basierend auf dem Datenverkehr, während Docker Swarm der schnellen Skalierung Priorität einräumt.
- Der automatische Lastausgleich ist in Docker Swarm verfügbar, jedoch nicht in Kubernetes. Allerdings können Lösungen von Drittanbietern einen externen Load Balancer mit Kubernetes verknüpfen.
Die Anforderungen Ihres Unternehmens bestimmen das richtige Werkzeug.
Container-Orchestrierungslösungen
Mit Container-Orchestrierungssystemen können Entwickler mehrere Container für die Anwendungsbereitstellung starten. IT-Manager können diese Plattformen nutzen, um die Verwaltung von Instanzen, die Beschaffung von Hosts und die Verbindung von Containern zu automatisieren.
Im Folgenden sind einige der besten Tools zur Container-Orchestrierung aufgeführt, die die Bereitstellung erleichtern, fehlgeschlagene Container-Implementierungen identifizieren und Anwendungskonfigurationen verwalten.
Top 5 der Container-Orchestrierungssoftware:
- Google Cloud Run
- Amazon Elastic Container Service (Amazon ECS)
- Mirantis Kubernetes Engine
- Google Kubernetes Engine
- Amazon Elastic Kubernetes Service (Amazon EKS)
*Die fünf führenden Container-Orchestrierungslösungen aus dem Grid Report Frühjahr 2023 von G2.

Best Practices und Designprinzipien für die Kubernetes-Architektur
Die Implementierung einer Plattformstrategie, die Sicherheit, Governance, Überwachung, Speicherung, Netzwerk, Container-Lebenszyklusmanagement und Orchestrierung berücksichtigt, ist von entscheidender Bedeutung. Die Einführung und Skalierung von Kubernetes stellt jedoch eine große Herausforderung dar, insbesondere für Unternehmen, die sowohl lokale als auch öffentliche Cloud-Infrastrukturen verwalten. Zur Vereinfachung werden im Folgenden einige Best Practices besprochen, die bei der Architektur von Kubernetes-Clustern berücksichtigt werden müssen.
- Stellen Sie sicher, dass Sie immer über die aktuellste Version von Kubernetes verfügen.
- Investieren Sie in Schulungen für die Entwicklungs- und Betriebsteams.
- Etablieren Sie eine unternehmensweite Governance . Stellen Sie sicher, dass Ihre Tools und Anbieter mit der Kubernetes-Orchestrierung kompatibel sind.
- Erhöhen Sie die Sicherheit , indem Sie Bildscantechniken in Ihren CI/CD-Workflow (Continuous Integration and Delivery) integrieren. Von einem GitHub-Repository heruntergeladener Open-Source-Code sollte immer mit Vorsicht behandelt werden.
- Implementieren Sie eine rollenbasierte Zugriffskontrolle (RBAC) im gesamten Cluster. Modelle, die auf Least Privilege und Zero Trust basieren, sollten die Norm sein.
- Verwenden Sie nur Nicht-Root-Benutzer und machen Sie das Dateisystem schreibgeschützt, um Container weiter zu schützen.
- Vermeiden Sie Standardwerte, da einfache Deklarationen weniger fehleranfällig sind und den Zweck besser kommunizieren.
- Seien Sie bei der Verwendung einfacher Docker Hub-Images vorsichtig, da diese möglicherweise Malware enthalten oder mit unnötigem Code überfüllt sind. Beginnen Sie mit schlankem, sauberem Code und arbeiten Sie sich nach oben. Kleinere Bilder wachsen schneller, beanspruchen weniger Speicherplatz und laden Bilder schneller herunter.
- Halten Sie die Behälter so einfach wie möglich. Ein Prozess pro Container ermöglicht es dem Orchestrator, zu melden, ob dieser Prozess fehlerfrei ist oder nicht.
- Absturz im Zweifelsfall. Führen Sie bei einem Fehler keinen Neustart durch, da Kubernetes einen fehlerhaften Container neu startet.
- Seien Sie beschreibend . Beschreibende Labels kommen gegenwärtigen und zukünftigen Entwicklern zugute.
- Wenn es um Microservices geht, sollten Sie nicht zu spezifisch sein . Jede Funktion innerhalb einer logischen Codekomponente darf nicht deren Microservice sein.
- Wenn möglich, automatisieren Sie . Sie können manuelle Kubernetes-Bereitstellungen vollständig überspringen, indem Sie Ihren CI/CD-Workflow automatisieren.
- Verwenden Sie die Liveliness- und Readiness-Probes, um die Verwaltung von Pod-Lebenszyklen zu unterstützen. Andernfalls werden Pods möglicherweise beendet, während sie initialisiert werden oder Benutzeranfragen empfangen, bevor sie bereit sind.
Tipp: Entdecken Sie Container-Management-Lösungen für bessere Bereitstellungspraktiken.
Denken Sie an Ihre Behälter
Kubernetes, die Container-zentrierte Verwaltungssoftware, ist aufgrund der breiten Nutzung von Containern in Unternehmen zum De-facto-Standard für die Bereitstellung und den Betrieb von Containeranwendungen geworden. Die Kubernetes-Architektur ist einfach und intuitiv. Während es IT-Managern eine bessere Kontrolle über ihre Infrastruktur und Anwendungsleistung gibt, gibt es noch viel zu lernen, um das Beste aus der Technologie herauszuholen.
Sind Sie neugierig, das Thema näher zu erforschen? Erfahren Sie mehr über die wachsende Bedeutung der Containerisierung im Cloud Computing!