
Was ist Failover-Clustering? Wie funktioniert es + Lösungen
Veröffentlicht: 2023-09-22Unternehmen, die Online-Transaktionen benötigen, können sich Serverausfälle nicht leisten. Aus diesem Grund suchen diese Unternehmen nach Möglichkeiten, ein ausfallsicheres Verfahren zu schaffen, das ihre Daten auch dann schützt, wenn der Server ausfällt. Eine dieser Methoden ist das Failover-Clustering.
Failover-Clustering kann durch Lösungen von Managed Domain Name System (DNS)-Anbietern gesteuert werden; Das Verständnis des Mechanismus und der wichtigsten Funktionen kann jedoch dazu beitragen, etwaige Failover-Herausforderungen zu begrenzen.
Was ist Failover-Clustering?
Failover-Clustering wird auf einer Gruppe von Computerservern ausgeführt, um eine hohe Verfügbarkeit (HA) oder kontinuierliche Verfügbarkeit (CA) für Serveranwendungen sicherzustellen. Diese Technologie stellt sicher, dass beim Ausfall eines Servers oder Knotens ein anderer Cluster-Knoten bereitsteht, um die Arbeitslast ohne Unterbrechung zu übernehmen.
Durch diesen Ansatz bleiben Ihre Server-Workloads skalierbar und verfügbar. Viele große Serverprogramme wie Microsoft Exchange , Microsoft SQL Server und Hyper-V verlassen sich auf Failover-Clustering, um sich selbst zu schützen.
Einige Failover- Cluster verwenden physische Server, während andere virtuelle Maschinen (VMs) verwenden. Jeder wählt die Art von Cluster, die er benötigt, basierend auf den Anforderungen seiner Serveranwendung.
Ein Cluster besteht aus zwei oder mehr Knoten, die Daten und Software zur Verarbeitung über physische Kabel oder ein spezielles sicheres Netzwerk austauschen. Verschiedene Arten von Clustering-Technologien können für Lastausgleich, Speicherung und gleichzeitiges oder paralleles Rechnen verwendet werden. In einigen Fällen werden Failover-Cluster mit zusätzlichen Clustering-Technologien kombiniert.
Die Hauptfunktion eines Failover-Clusters besteht darin, CA oder HA für Anwendungen und Dienste bereitzustellen. CA-Cluster, auch als fehlertolerante (FT) Cluster bekannt, ermöglichen es Endbenutzern, Anwendungen und Dienste auch dann weiter zu nutzen, wenn ein Server ausfällt. Durch HA-Cluster kann es zu einer kurzen Dienstunterbrechung kommen, das System kann sich jedoch ohne Datenverlust und mit geringer Ausfallzeit erholen.
Warum ist Failover-Clustering wichtig?
Mit Failover-Clustering können Sie inaktive Knoten reparieren, ohne Ihre Datenbank herunterzufahren. So vermeiden Sie Ausfallzeiten und können defekte Server schnell reparieren. Darüber hinaus beendet diese Technik im Falle eines Hardwarefehlers die Datenbank, um die aktiven Knoten zu schützen.
Failover-Clustering automatisiert auch die Datenwiederherstellung im Falle eines Fehlers. Dadurch reduzieren Sie Ihre Abhängigkeit vom Personal der Informationstechnologie (IT) und ermöglichen eine schnelle Wiederherstellung Ihrer Server. Es bietet außerdem eine hervorragende SQL-Clusterverfügbarkeit (Structured Query Language) mit minimaler Ausfallzeit. Die automatisierte Failover-Funktionalität des Failover-Clusterings bewahrt die Funktion Ihrer Datenbank, selbst wenn es zu einem Hardwareausfall kommt.
Wie funktionieren Failover-Cluster?
Failover-Clustering besteht aus zwei grundlegenden Prozessen, HA und CA, für Serveranwendungen.
Während CA-Failover-Cluster versuchen, eine Verfügbarkeit von 100 % zu erreichen, streben HA-Cluster eine Verfügbarkeit von 99,999 % an, was allgemein als „Five Nines“ bekannt ist. Diese Ausfallzeit beträgt maximal 5,26 Minuten pro Jahr. CA-Cluster verfügen über eine höhere Verfügbarkeit, erfordern jedoch mehr Hardware für den Betrieb, was ihre Gesamtkosten erhöht.
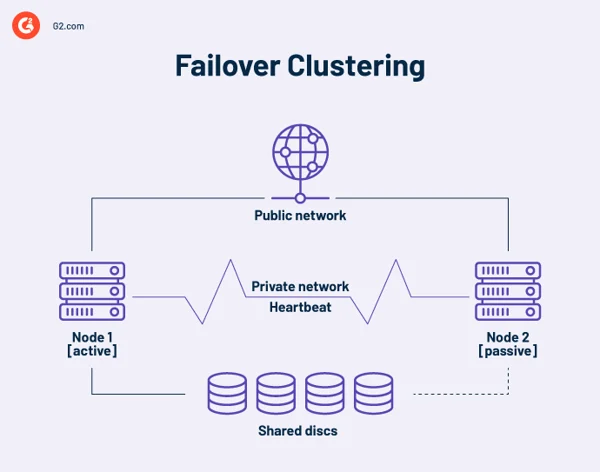
Hochverfügbare Failover-Cluster
Ein Hochverfügbarkeitscluster ist eine Sammlung unabhängiger Computer, die Ressourcen und Daten gemeinsam nutzen. Die Knoten eines Failover-Clusters haben Zugriff auf gemeinsam genutzten Speicher. In Hochverfügbarkeitsclustern ist außerdem ein Überwachungslink enthalten, um den Heartbeat oder den Zustand der anderen Server zu überprüfen. Ein Heartbeat ist ein privates Netzwerk, das nur von den Knoten im Cluster gemeinsam genutzt wird. Es ist von außen nicht zugänglich.
Zu jedem Zeitpunkt ist mindestens ein Knoten in einem Cluster aktiv und mindestens einer ist inaktiv oder passiv.
Fällt in einer einfachen Zwei-Knoten-Anordnung Knoten 1 aus, erkennt Knoten 2 den Ausfall über die Heartbeat-Verbindung und konfiguriert sich selbst als aktiver Knoten. Die Clustering-Software auf jedem Knoten garantiert, dass Clients eine Verbindung zu einem aktiven Knoten herstellen.
Größere Installationen verwenden möglicherweise dedizierte Server zur Verwaltung des Clusters. Ein Cluster-Management-Server sendet immer Heartbeat-Signale, um ausgefallene Knoten zu identifizieren und, falls ja, einen anderen Knoten anzuweisen, die Arbeit zu übernehmen.
Einige Cluster-Management-Softwaretools handhaben HA für VMs, indem sie die Maschinen und Server in einem Cluster gruppieren. Wenn ein Host ausfällt, nimmt ein anderer Host die VMs wieder auf.
Als möglicher einzelner Fehlerpunkt stellt Shared Storage ein Risiko dar. Die Kombination eines redundanten Arrays unabhängiger Festplatten 6 und 10 – auch bekannt als RAID 6 und RAID 10 – kann jedoch dazu beitragen, den Betrieb auch dann aufrechtzuerhalten, wenn zwei Festplatten ausfallen.
Wenn alle Server an dasselbe Stromnetz angeschlossen sind, kann die Stromversorgung ein weiterer Single Point of Failure sein. Durch die Ausstattung jedes Knotens mit einer eigenen unterbrechungsfreien Stromversorgung (USV) bleibt dieser geschützt.
Failover-Cluster mit kontinuierlicher Verfügbarkeit
Im Gegensatz zum HA-Paradigma umfasst ein fehlertoleranter Cluster zahlreiche Computer, die sich eine einzige Kopie des Betriebssystems (OS) eines Computers teilen. Softwarebefehle, die einem System erteilt werden, werden auch auf den anderen Systemen ausgeführt.
CA besteht darauf, dass die Organisation formatierte Computerausrüstung und eine Backup-USV einsetzt. CA benötigt eine ständig zugängliche und nahezu perfekte Nachbildung des physischen oder virtuellen Systems, auf dem der Dienst ausgeführt wird. Dieses Redundanzmodell ist als 2N bekannt.
CA-Systeme können eine Vielzahl von Fehlern kompensieren. Ein fehlertolerantes System kann eine Fehlfunktion von Folgendem erkennen:
- Eine Festplatte
- Eine Verarbeitungseinheit in einem Computer
- Ein Subsystem für Eingabe und Ausgabe (I/O)
- Eine Stromquelle
- Eine Komponente eines Netzwerks
Die Fehlerstelle kann umgehend entdeckt werden und eine Backup-Komponente oder -Methode kann sofort ihren Platz einnehmen, ohne den nächsten Dienst zu unterbrechen.
Clustering-Software kann zwei oder mehr Server verbinden, um sich wie ein einzelner virtueller Server zu verhalten, oder verschiedene alternative CA-Failover-Cluster-Konfigurationen erstellen. Fällt beispielsweise einer der virtuellen Server aus, reagieren die anderen, indem sie den virtuellen Server vorübergehend aus dem Cluster-Quorum entfernen. Der virtuelle Server verteilt dann die Last auf die anderen Server, bis der abgestürzte Server zum Neustart bereit ist.
Ein doppelter Hardwareserver , bei dem alle physischen Komponenten repliziert sind, ist eine Alternative zu CA-Failover-Clustern. Sie rechnen separat und gleichzeitig auf verschiedenen Hardwareplattformen und synchronisieren sich über einen dedizierten Knoten, der die Ergebnisse beider physischer Server überwacht. Diese Lösung bietet zwar Schutz, ist jedoch möglicherweise teurer.
Failover-Clustering-Funktionen
Viele Organisationen nutzen Failover-Clustering für geschäftskritische Anwendungen. Dies liegt daran, dass die folgenden Merkmale das Failover-Clustering zu einer wichtigen Technik machen.
- Skalierbarkeit : Da Failover-Clustering auf einer Gruppe von Clustern basiert, die zusammenarbeiten, um Serverausfälle zu verhindern, können Sie bei Bedarf einfach und problemlos skalieren, indem Sie neue Cluster hinzufügen.
- Stabilität: Geclusterte Server verbinden sich über Kabel. Die verbleibenden Cluster können weiterhin Dienste anbieten, selbst wenn einer oder mehrere aufgrund externer Faktoren ausfallen.
- Echtzeitüberwachung: Die Clusterknoten werden ständig überwacht, um sicherzustellen, dass sie ordnungsgemäß funktionieren. Wenn ein Cluster neu gestartet oder auf einen anderen Knoten übertragen wird.
- Cluster Shared Volume (CSV): Diese Funktion stellt einen konsistenten und verteilten Namespace für Knoten bereit, die sie bei der Arbeit mit gemeinsam genutztem Speicher verwenden können. Es ist von entscheidender Bedeutung, dass Serveranwendungen von Anfang bis Ende unterbrechungsfrei laufen.
Arten von Failover-Clustern
Im letzten Jahrzehnt wurden beim Failover-Clustering erhebliche Fortschritte erzielt, und viele Unternehmen bieten mittlerweile ihre eigene Version von Clustering-Lösungen an. Einige der gängigsten Clusterdienste werden hier detailliert beschrieben.

VMware-Failover-Cluster
VMware bietet zahlreiche Virtualisierungstechnologien für VM-Cluster. Die CA-Architektur von vSphere vMotion dupliziert präzise eine virtuelle VMware-Maschine und ihr Netzwerk zwischen physischen Rechenzentrumsnetzwerken.
VMware vSphere HA, ein zweites Produkt, bietet HA für VMs, indem es diese und ihre Hosts für ein automatisiertes Failover in einem Cluster gruppiert. Darüber hinaus ist das Programm nicht auf externe Komponenten wie DNS angewiesen, wodurch mögliche Fehlerquellen verringert werden.
Windows-Server-Failover-Cluster
Die Windows-Server-Failover-Cluster-Methode (WSFC) fördert die Erstellung von Hyper-V-Failover-Servern. Zwischen 2016 und 2019 wurde diese Strategie bei Microsoft Windows-Benutzern immer beliebter. WSFC ermöglicht die Clusterüberwachung und bietet automatisch den erforderlichen Failover-Mechanismus. Bei einem Serververlust verschiebt WFSC die Cluster auf einen separaten Knoten oder versucht, sie neu zu starten. Darüber hinaus bietet die CSV-Technologie einen verteilten Namensraum, der es mehreren Knoten ermöglicht, den Speicher gemeinsam zu nutzen.
SQL Server
Dieses mit SQL Server 2017 eingeführte Microsoft-Produkt verfügt über robuste HA-Lösungen, die die WSFC-Technologie nutzen. SQL Server-Komponenten gelten in diesem Zusammenhang als WSFC-Clusterressourcen. Sie sind außerdem mit anderen WSFC-abhängigen Ressourcen integriert. Daher hat WSFC die Befugnis, Anweisungen zum Neustart einer SQL Server-Instanz oder zum Verschieben ähnlicher Instanzen auf einen neuen Knoten zu identifizieren und zu kommunizieren.
Red Hat Linux
Außer Microsoft verfügen auch andere Betriebssystemanbieter über eigene Failover-Cluster-Lösungen. Fans von Red Hat Enterprise Linux (RHEL) können beispielsweise die HA-Erweiterung und das Red Hat Global File System (GFS/GFS2) verwenden, um HA-Failover-Cluster einzurichten. Es werden Single-Cluster-Stretch-Cluster unterstützt, die sich über viele Standorte erstrecken, sowie katastrophentolerante Cluster mit mehreren Standorten. Die SAN-Datenspeicherreplikation (Storage Area Network) wird häufig in Clustern mit mehreren Standorten verwendet.
Anwendungen des Failover-Clusterings
Dieser robuste Mechanismus ermöglicht die folgenden Echtzeitanwendungen.
Verfügbarkeit geschäftskritischer Anwendungen.
Computer zur Online-Transaktionsverarbeitung (OLTP) müssen über fehlerresistente Systeme verfügen. OLTP, das eine vollständige Verfügbarkeit erfordert, wird für Flugreservierungssysteme, den elektronischen Aktienhandel und das Geldautomaten-Banking verwendet.
Viele Branchen wie Fertigung, Versand und Einzelhandel nutzen CA-Cluster oder ausfallsichere Computer für unternehmenswichtige Anwendungen. Beispiele hierfür sind E-Commerce, Auftragsverwaltung und Personalzeiterfassungssysteme.
Hochverfügbarkeitscluster eignen sich häufig zum Clustern von Anwendungen und Diensten, die nur eine Betriebszeit von fünf bis neun Sekunden erfordern.
Katastrophenhilfe
Auch die Notfallwiederherstellung profitiert vom Failover-Clustering. Es wird dringend empfohlen, Failover-Server an entfernten Standorten zu hosten, da eine Katastrophe wie ein Feuer oder eine Überschwemmung die gesamte physische Hardware und Software zerstört.
Storage Replica, eine Technologie, die Volumes zwischen Servern für die Notfallwiederherstellung dupliziert, ist in Windows Server 2016 und 2019 enthalten. Stretch-Failover ist eine Technologiefunktion, mit der Failover-Cluster zwei Standorte umfassen können.
Durch die Erweiterung von Failover-Clustern können Unternehmen Daten über verschiedene Zentren replizieren . Wenn an einem Standort eine Tragödie eintritt, bleiben alle Daten auf Failover-Servern an den anderen Standorten erhalten.
Replikation einer Datenbank
Laut Microsoft wurde die WSFC erstmals in Windows Server 2016 eingeführt, um „geschäftskritische“ Dienste wie die SQL-Server-Datenbank und den Microsoft Exchange-Kommunikationsserver zu schützen.
Für die Datenbankreplikation bieten andere Anbieter die Failover-Cluster-Technologie an. MySQL Cluster verfügt beispielsweise über eine Heartbeat-Methode, die eine schnelle Fehlererkennung bei anderen Knoten im Cluster ermöglicht, oft in weniger als einer Sekunde, ohne dass es zu Dienstunterbrechungen für Clients kommt.
Mithilfe der geografischen Replikationsfunktion können Datenbanken an weit entfernte Standorte repliziert werden.
Vorteile von Failover-Clustern
Die Idee von Failover-Clustern besteht darin, sicherzustellen, dass Benutzer möglichst wenig Dienstunterbrechungen erleiden. Im Folgenden werden jedoch weitere zusätzliche Vorteile des Failover-Clusterings erläutert.
- Erhöhte Ressourcenverfügbarkeit: Fällt ein intelligenter Server aus, übernehmen die anderen im Cluster die Last. Das spart entscheidende Zeit und Informationen.
- Strategische Ressourcenzuweisung: Sie können Projekte auf beliebige Weise zwischen den Knoten verteilen. Dies minimiert den Overhead, da nicht alle Computer alle Projekte gleichzeitig ausführen müssen, sodass Sie Ihre Ressourcen freier nutzen können.
- Erhöhte Rechenleistung: Mehr Maschinen, mehr Leistung.
- Höhere Skalierbarkeit: Wenn Ihre Benutzerbasis und die Berichtskomplexität wachsen, können auch Ihre Ressourcen wachsen.
- Vereinfachte Verwaltung: Clustering erleichtert den Umgang mit wichtigen oder sich schnell ändernden Systemen.
Einschränkungen des Failover-Clusterings
So wichtig Failover-Clustering auch ist, es stößt auf die folgenden Einschränkungen.
- Komplexe Konfigurationen: Bei der Failover-Clustering-Konfiguration für Windows müssen Sie viele Netzwerke und Netzwerkkarten gleichzeitig verwalten. Daher ist die Anwendung dieser Methode insbesondere für Anfänger schwierig.
- Tool-Integrationen: Windows-Failover-Clustering und Hyper-V müssen stärker integriert werden. Sie müssen jeden von ihnen anpassen um das Failover-Clustering erfolgreich abzuschließen.
- Webschnittstelle: Es gibt keine Webschnittstelle zum Anpassen von Clusterparametern. Um auf die Cluster-Manager-Funktion zuzugreifen, müssen Sie sich manuell bei einem Remote-Desktop anmelden.
Failover-Clustering-Lösungen: verwaltete DNS-Anbieter
Durch die Zusammenarbeit mit Failover-Clustering-Systemen leiten verwaltete DNS-Anbieter den Datenverkehr bei Failover-Ereignissen auf alternative Server oder Rechenzentren um und stellen so einen ununterbrochenen Zugriff auf Ihre Dienste sicher, sodass Sie eine hohe Verfügbarkeit erreichen und Ausfallzeiten minimieren.
Die fünf besten verwalteten DNS-Anbieter:
- Cloudflare-DNS
- Azure DNS
- Infoblox NIOS
- WPMU-ENTWICKLER
- DNS-Manager
* Oben sind die fünf führenden Managed-DNS-Anbietersoftware aus dem G2-Grid-Grid-Bericht vom Herbst 2023 aufgeführt.

Zuverlässigkeit modernisieren
Failover-Clustering hat sich als zuverlässige und wesentliche Option für hohe Verfügbarkeit und Fehlertoleranz in aktuellen IT-Infrastrukturen herausgestellt. Es gewährleistet einen kontinuierlichen Betrieb trotz Hardwarefehlern oder geplanter Wartung, indem es Arbeitslasten und Ressourcen automatisch auf zahlreiche Netzwerkknoten verteilt. Diese Technologie bietet Ihnen eine weitere Möglichkeit, den wichtigsten Aspekt Ihres Geschäfts zu bewältigen – die Erfahrung jedes Kunden sicher und glücklich zu machen.
Es schadet auch nicht, die Widerstandsfähigkeit Ihres Systems zu stärken!
Beginnen Sie mit einem Leitfaden zur DNS-Sicherheit für eine robuste Systemstrategie.